标签:
准备:
create table t(x int primary key,y int unique,z int);
insert into t(x,y,z) values(1,1,1),(2,2,2),(3,3,3),(4,4,4),(5,5,5),(6,6,6),(7,7,7),(8,8,8),(9,9,9);
情况1:select 没有用到索引
explain select z from t;
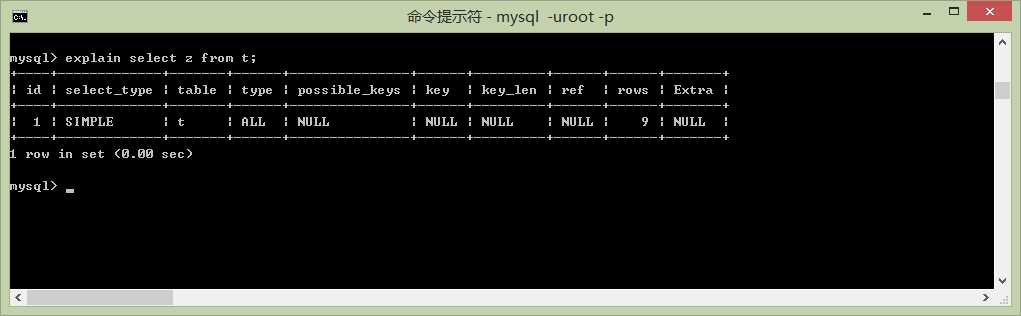
type = all 说明是全表扫描、也就是说把表中的数据都读一遍才得到结果、这种查询通常是非常慢的。为查询加上与之匹配的索引效果会好许多。
情况2:用到了索引
select y from t;
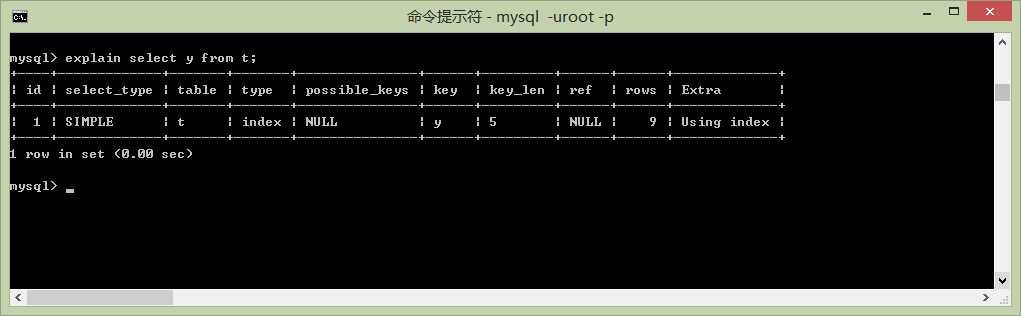
type = index 说明查询用到了索引、与type=all相比由于不要把整个表载入内存,只要载入索引就可以完成查询、所以数据的读取量就少了。相比type=all通常会快一些。
情况3:
用到了索引、但是只需要载入索引的一部份就可以完成查询
select min(y),max(y) from t;
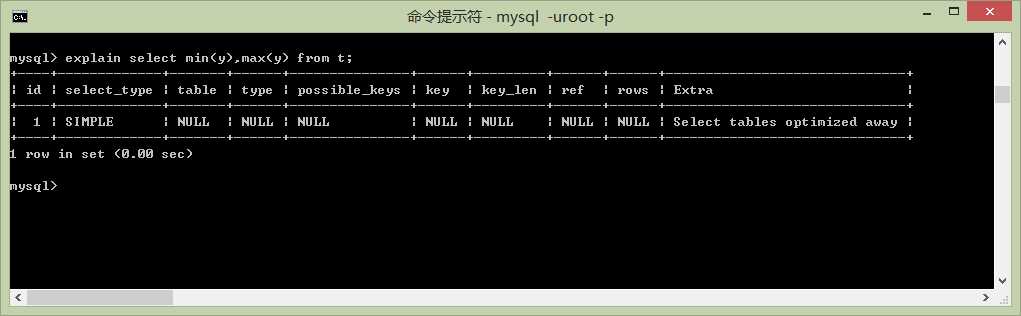
与情况2相比它更加牛逼、table=null说明它不用去表里面找、type=null看起来它索引都没有用到就好像它是从计数器中取到的一样。但是我认为它还是走了索引的,只不过是索引的一小部分。注意它的Extra 说明“Select tables optimized away”
情况4:
where 条件有索引可用,select 执行count,sum
select count(y),sum(y) from t where y>3;
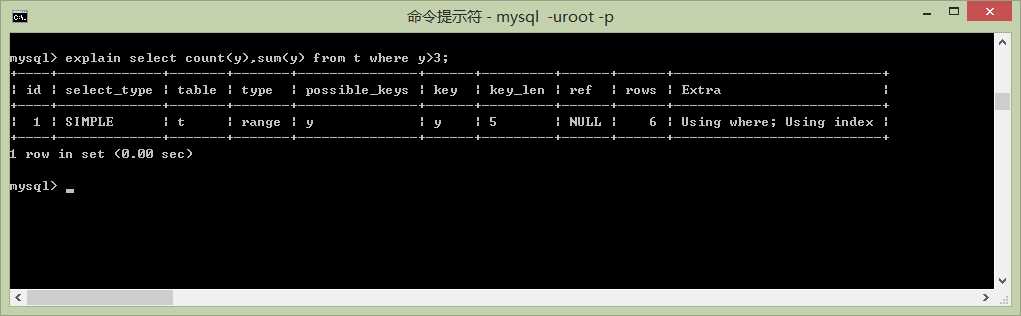
key = y 说明使用了索引y、 type = range 说明它不用载入整个索引、只要载入一部分就可以了(y>3的部分)。
情况5:
where 段有主键索引可用,select 段是聚合函数
select sum(x),min(x),max(x),count(x) from t where x>3;
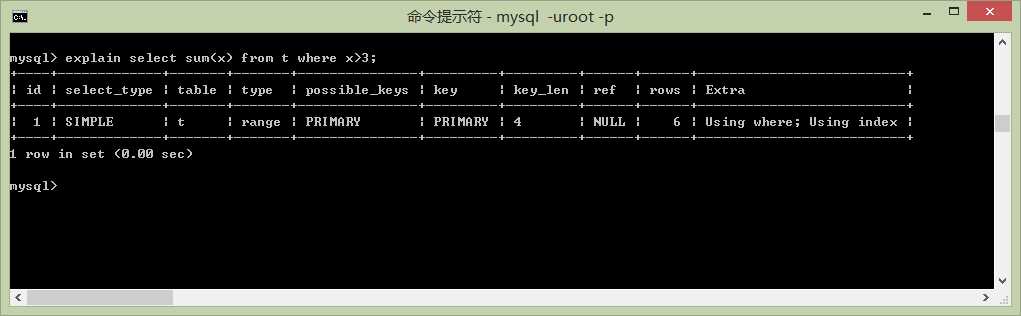
这里我有一个问题就是情况5中的key_len是4情况4中的key_len是5但是x,y可都是int 类型啊!
标签:
原文地址:http://www.cnblogs.com/JiangLe/p/4389100.html