标签:
在平常开发中,去重复数据经常使用到,本人新手,接触Oracle也不久,开发中用到的小知识点,记录一下,老鸟可绕道,如果有写错的,请指正。
去重复记录可以使用distinct,当只查询一列数据时,可以轻松去掉重复的数据,当查询多列数据时,如果有一列的数据不相同,distinct则认为数据是不相同的,也就是数据将不会合并,这时类似是group by 某写字段的结果一样,此时的结果可能不是我们想要的。下面说下查询多列时去重复及合计重复记录的条数。
当做个不同的链接查询,得到的结果如下:
1 select 2 rownum, 3 z.zdbh, 4 z.adsljdsbmc, 5 z.glwxtgdbh, 6 sysdate 7 from rebase_ztgd z left join rebase_dzgd d 8 on z.glwxtgdbh=d.djbh
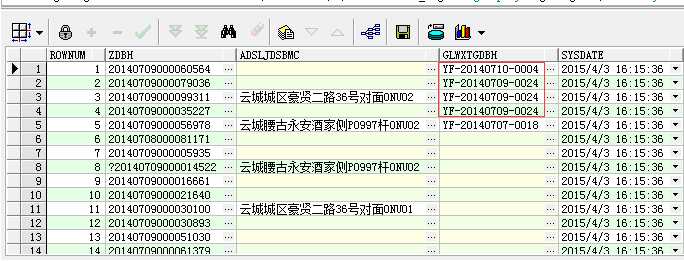
而如果这样写
select rownum, z.zdbh, z.adsljdsbmc, z.glwxtgdbh, sysdate from rebase_ztgd z left join rebase_dzgd d on z.glwxtgdbh=d.djbh where z.glwxtgdbh is not null and z.id in(select min(id) from rebase_ztgd b group by b.glwxtgdbh ) order by z.id desc;

重复数据只取一条,关键代码是这里:
z.id in(select min(id) from rebase_ztgd b group by b.glwxtgdbh )这句就是从重复的
glwxtgdbh字段分组,然后取出最小ID的那条记录,当然,里边不一定是使用min,也可以用Max
下面说下怎么记录重复记录的条数:
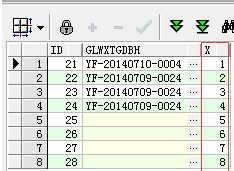
首先看下这行SQL语句的效果:
select id,z.glwxtgdbh,row_number() over (order by id) x from rebase_ztgd z;
其实就是用到row_number()函数,根据ID排序,生成一列连续编号的列X
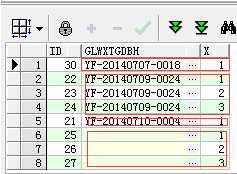
再看下面这行SQL语句:
select id,z.glwxtgdbh,row_number() over (partition by z.glwxtgdbh order by id) x from rebase_ztgd z;
这句大概意思是,用row_NUMBER()函数配合over聚合函数,对单列glwxtgdbh
分组 分组内按id排序:
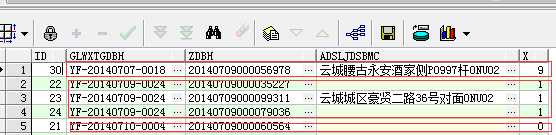
然后看下上面两个相减的结果:
select z.id,z.glwxtgdbh,z.zdbh,z.adsljdsbmc,row_number() over (order by z.id) - row_number() over (partition by z.glwxtgdbh order by z.id) x from rebase_ztgd z
大致意思是id排序值 减去glwxtgdbh
分组内id排序值 = 连续相同值的排序值
然后使用count函数就可以计算出每组的条数了
select max(zdbh), count(*), max(adsljdsbmc)节电设备名称, max(glwxtgdbh)关联工单, sysdate from( select z.id,z.glwxtgdbh,z.zdbh,z.adsljdsbmc,row_number() over (order by z.id) - row_number() over (partition by z.glwxtgdbh order by z.id) x from rebase_ztgd z left join rebase_dzgd d on z.glwxtgdbh=d.djbh) where glwxtgdbh is not null group by x order by min(id)

我想合并成这样的
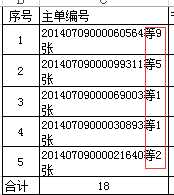
然后将两个列合并下就可以了:如下
select to_char(rownum) 序号,t.* from( select case when count(*)=1 then max(zdbh)||‘有‘||count(*)||‘张‘ else max(zdbh)||‘等‘||count(*)||‘张‘ end 主单编号, max(adsljdsbmc)节电设备名称, max(glwxtgdbh)关联工单, sysdate from( select z.id,z.glwxtgdbh,z.zdbh,z.adsljdsbmc,row_number() over (order by z.id) - row_number() over (partition by z.glwxtgdbh order by z.id) x from rebase_ztgd z left join rebase_dzgd d on z.glwxtgdbh=d.djbh) where glwxtgdbh is not null group by x order by min(id) )t union all select ‘合计‘序号,‘33‘,‘‘,‘‘,sysdate from dual
效果如下:
这样就完成了。。
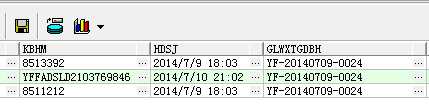
获取重复数据可用:
select * from rebase_ztgd where glwxtgdbh in ( select glwxtgdbh from rebase_ztgd group by glwxtgdbh having count(id) > 1 )
Oracle初级入门 根据某字段重复只取一条记录,并计计算重复条数
标签:
原文地址:http://www.cnblogs.com/Agan2213/p/4390653.html