标签:
评分公式
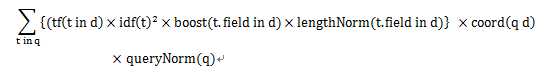
1.coord(q,d),查询覆盖率
/** Implemented as <code>overlap / maxOverlap</code>. */ @Override public float coord(int overlap, int maxOverlap) { return overlap / (float)maxOverlap; }
例如:
查询:query=title:search and content:lucenen 确定最大覆盖maxOverlap = 2
索引文档内容:1.{title:search ***,content:lucenen ***}
title和content全部命中:overlap = 2 coord(q,d) = 2/2
2.{title:search ***,content:solr ***}
只有title命中:overlap = 1 coord(q,d) = 1/2
通过该参数影响排序的手段是修改分词使Token更多的命中Term,提高coord值
2.queryNorm(q),查询权重得分,对结果排序无影响,同一次查询该因子得分一致
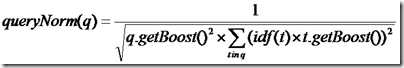
/** Implemented as <code>1/sqrt(sumOfSquaredWeights)</code>. */ @Override public float queryNorm(float sumOfSquaredWeights) { return (float)(1.0 / Math.sqrt(sumOfSquaredWeights)); }
sumOfSquaredWeights 查询权重得分
TermQuery权重,BooleanQuery权重
t in q: term in query
一次查询的BooleanQuery、TermQuery权重是一致的,该queryNorm因子在同一次查询对排序结果无影响,而是用来比较不同次查询的分数
括号里针对解析出的每个Term进行分数累加,例如:查询"lucene and solr",lucene的分数 + solr的分数
3.tf(TermFreq),词频,该Term在该文档出现的频率
tf = sqrt(Term在该文档出现的次数)
/** Implemented as <code>sqrt(freq)</code>. */ @Override public float tf(float freq) { return (float)Math.sqrt(freq); }
查询词在该文档中出现的次数越多,表明该文档越重要
4.idf(InverseDocumentFreq逆向文本频率),docFreq(term出现的文档数量),numDocs所有文档数量
/** Implemented as <code>log(numDocs/(docFreq+1)) + 1</code>. */ @Override public float idf(long docFreq, long numDocs) { return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0); }
5.t.getBoost(),term in document的查询权重,solr调用接口 title:lucene^3
6.lengthNorm()term in document
/** Implemented as * <code>state.getBoost()*lengthNorm(numTerms)</code>, where * <code>numTerms</code> is {@link FieldInvertState#getLength()} if {@link * #setDiscountOverlaps} is false, else it‘s {@link * FieldInvertState#getLength()} - {@link * FieldInvertState#getNumOverlap()}. * * @lucene.experimental */ @Override public float lengthNorm(FieldInvertState state) { final int numTerms; if (discountOverlaps) numTerms = state.getLength() - state.getNumOverlap(); else numTerms = state.getLength(); return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms))); }
该因子由两部分组成
1.state.getBoost(),改值是由创建索引时指定的field权重
2.(float)(1.0/Math.sqrt(numTerms)),numTerms代表term对应field的长度,如果title:lucene的numTerms对应的文档"title:lucenen"比文档"title:lucene and solr"重要
标签:
原文地址:http://www.cnblogs.com/miniqiang/p/4422194.html