标签:
catalog
1. Netlink简介 2. Netlink Function API Howto 3. Generic Netlink HOWTO kernel API 4. RFC 3549 Linux Netlink as an IP Services Protocol 5. sendmsg、recvmsg In User Space 6. kernel_recvmsg、kernel_sendmsg In Kernel Space 7. NetLink Sockets C++ Library 8. Netlink Protocol Library Suite (libnl)
1. Netlink简介
Netlink is a flexible, robust, wire-format communications channel typically used for kernel to user communication although it can also be used for user to user and kernel to kernel communications. Netlink communication channels are associated with families or "busses", where each bus deals with a specific service; for example
1. 路由daemon(NETLINK_ROUTE) 2. 1-wire子系统(NETLINK_W1) 3. 用户态socket协议(NETLINK_USERSOCK) 4. 防火墙(NETLINK_FIREWALL) 5. socket监视(NETLINK_INET_DIAG) 6. netfilter日志(NETLINK_NFLOG) 7. ipsec安全策略(NETLINK_XFRM) 8. SELinux事件通知(NETLINK_SELINUX) 9. iSCSI子系统(NETLINK_ISCSI) 10. 进程审计(NETLINK_AUDIT) 11. 转发信息表查询(NETLINK_FIB_LOOKUP) 12. netlink connector(NETLINK_CONNECTOR) 13. netfilter子系统(NETLINK_NETFILTER) 14. IPv6防火墙(NETLINK_IP6_FW) 15. DECnet路由信息(NETLINK_DNRTMSG) 16. 内核事件向用户态通知(NETLINK_KOBJECT_UEVENT) 17. 通用netlink(NETLINK_GENERIC)
Netlink相对于系统调用,ioctl以及/proc文件系统而言具有以下优点
1. 为了使用netlink,用户仅需要在include/linux/netlink.h中增加一个新类型的netlink协议定义即可,如 #define NETLINK_MYTEST 17 然后,内核和用户态应用就可以立即通过 socket API 使用该 netlink 协议类型进行数据交换。但系统调用需要增加新的系统调用,ioctl 则需要增加设备或文件, 那需要不少代码,proc 文件系统则需要在 /proc 下添加新的文件或目录,那将使本来就混乱的 /proc 更加混乱 2. netlink是一种异步通信机制,在内核与用户态应用之间传递的消息保存在socket缓存队列中,发送消息只是把消息保存在接收者的socket的接 收队列,而不需要等待接收者收到消息,但系统调用与 ioctl 则是同步通信机制,如果传递的数据太长,将影响调度粒度 3.使用 netlink 的内核部分可以采用模块的方式实现,使用 netlink 的应用部分和内核部分没有编译时依赖,但系统调用就有依赖,而且新的系统调用的实现必须静态地连接到内核中,它无法在模块中实现,使用新系统调用的应用在编译时需要依赖内核 4.netlink 支持多播,内核模块或应用可以把消息多播给一个netlink组,属于该neilink 组的任何内核模块或应用都能接收到该消息,内核事件向用户态的通知机制就使用了这一特性,任何对内核事件感兴趣的应用都能收到该子系统发送的内核事件 5.内核可以使用 netlink 首先发起会话(双向的),但系统调用和 ioctl 只能由用户应用发起调用 6.netlink 使用标准的 socket API,因此很容易使用,但系统调用和 ioctl则需要专门的培训才能使用
0x2: Netllink通信流程
从用户态-内核态交互的角度来看,Netlink的通信流程如下
1. 应用程序将待发送的数据通过sendmsg()传给Netlink,Netlink进行"组包",这实际上是一次内存拷贝 2. Netlink在buffer满之后,即组包完成,将消息一次性进行"穿透拷贝",即copy_from_user、copy_to_user,这是一次代价较高的系统调用 3. 内核模块从Netlink的buffer逐个取出数据包,即拆包,这个过程可以串行的实现,也可以异步地实现
Relevant Link:
http://www.linuxfoundation.org/collaborate/workgroups/networking/netlink
2. Netlink Function API Howto
0x1: User Space
用户态应用使用标准的socket APIs,socket()、bind()、sendmsg()、recvmsg()、close()就能很容易地使用netlink socket
socket(AF_NETLINK, SOCK_RAW, netlink_type) 1. 参数1: 1) AF_NETLINK 2) PF_NETLINK //在 Linux 中,它们俩实际为一个东西,它表示要使用netlink 2. 参数2: 1) SOCK_RAW 2) SOCK_DGRAM 3. 参数3: 指定Netlink协议类型 #define NETLINK_ROUTE 0 /* Routing/device hook */ #define NETLINK_W1 1 /* 1-wire subsystem */ #define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */ #define NETLINK_FIREWALL 3 /* Firewalling hook */ #define NETLINK_INET_DIAG 4 /* INET socket monitoring */ #define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */ #define NETLINK_XFRM 6 /* ipsec */ #define NETLINK_SELINUX 7 /* SELinux event notifications */ #define NETLINK_ISCSI 8 /* Open-iSCSI */ #define NETLINK_AUDIT 9 /* auditing */ #define NETLINK_FIB_LOOKUP 10 #define NETLINK_CONNECTOR 11 #define NETLINK_NETFILTER 12 /* netfilter subsystem */ #define NETLINK_IP6_FW 13 #define NETLINK_DNRTMSG 14 /* DECnet routing messages */ #define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace */ #define NETLINK_GENERIC 16 //NETLINK_GENERIC是一个通用的协议类型,它是专门为用户使用的,因此,用户可以直接使用它,而不必再添加新的协议类型
对于每一个netlink协议类型,可以有多达 32多播组,每一个多播组用一个位表示,netlink 的多播特性使得发送消息给同一个组仅需要一次系统调用,因而对于需要多拨消息的应用而言,大大地降低了系统调用的次数
bind(fd, (struct sockaddr*)&nladdr, sizeof(struct sockaddr_nl)); 函数bind()用于把一个打开的netlink socket与netlink源socket地址绑定在一起。netlink socket的地址结构如下 struct sockaddr_nl { //字段 nl_family 必须设置为 AF_NETLINK 或着 PF_NETLINK sa_family_t nl_family; //字段 nl_pad 当前没有使用,因此要总是设置为 0 unsigned short nl_pad; /* 字段 nl_pid 为接收或发送消息的进程的 ID 1. nl_pid = 0: 消息接收者为内核或多播组 2. nl_pid != 0: nl_pid 实际上未必是进程 ID,它只是用于区分不同的接收者或发送者的一个标识,用户可以根据自己需要设置该字段 */ __u32 nl_pid; /* nl_groups 用于指定多播组,bind 函数用于把调用进程加入到该字段指定的多播组 1. nl_groups = 0: 该消息为单播消息,调用者不加入任何多播组 2. nl_groups != 0: 多播消息 */ __u32 nl_groups; };
值得注意的是,传递给 bind 函数的地址的 nl_pid 字段应当设置为本进程的进程 ID,这相当于 netlink socket 的本地地址。但是,对于一个进程的多个线程使用 netlink socket 的情况,字段 nl_pid 则可以设置为其它的值,如
pthread_self() << 16 | getpid();
字段 nl_pid 实际上未必是进程 ID,它只是用于区分不同的接收者或发送者的一个标识,用户可以根据自己需要设置该字段
关于使用netlink api及其相关参数,请参阅另一篇文章 http://www.cnblogs.com/LittleHann/p/3867214.html //搜索:user_client.c(用户态程序)
从netlink发送消息相关的数据结构中我们可以看出netlink发送消息的逻辑
1. 对于程序员来说,发送消息的系统调用接口只有sendmsg,每次调用sendmsg只需要传入struct msghdr结构体的实例即可 2. 对于每个struct msghdr结构的实例来说,都必须指定struct iovec成员,即所有单个的消息都会被"挂入"一个"队列"中,用于缓存集中发送 3. 每个代表"消息队列"的struct iovec结构体实例,都必须指定struct nlmsghdr成员,即消息头,用于实现"多路复用"和"多路分解"
0x2: Kernel Space
内核使用netlink需要专门的API,这完全不同于用户态应用对netlink的使用。如果用户需要增加新的netlink协 议类型,必须通过修改linux/netlink.h来实现,当然,目前的netlink实现已经包含了一个通用的协议类型 NETLINK_GENERIC以方便用户使用,用户可以直接使用它而不必增加新的协议类型
在内核中,为了创建一个netlink socket用户需要调用如下函数 struct sock *netlink_kernel_create(int unit, void (*input)(struct sock *sk, int len));
当内核中发送netlink消息时,也需要设置目标地址与源地址,linux/netlink.h中定义了一个宏
struct netlink_skb_parms { /* Skb credentials struct scm_creds { //pid表示消息发送者进程ID,也即源地址,对于内核,它为 0 u32 pid; kuid_t uid; kgid_t gid; }; struct scm_creds creds; /* 字段portid表示消息接收者进程 ID,也即目标地址,如果目标为组或内核,它设置为 0,否则 dst_group 表示目标组地址,如果它目标为某一进程或内核,dst_group 应当设置为 0 */ __u32 portid; __u32 dst_group; __u32 flags; struct sock *sk; }; #define NETLINK_CB(skb) (*(struct netlink_skb_parms*)&((skb)->cb))
在内核中,模块调用函数 netlink_unicast 来发送单播消息
int netlink_unicast(struct sock *sk, struct sk_buff *skb, u32 pid, int nonblock);
Relevant Link:
http://www.cnblogs.com/iceocean/articles/1594195.html http://blog.csdn.net/zcabcd123/article/details/8272423
3. Generic Netlink HOWTO kernel API
Relevant Link:
http://www.linuxfoundation.org/collaborate/workgroups/networking/generic_netlink_howto
4. RFC 3549 Linux Netlink as an IP Services Protocol
A Control Plane (CP) is an execution environment that may have several sub-components, which we refer to as CPCs. Each CPC provides control for a different IP service being executed by a Forwarding Engine (FE) component. This relationship means that there might be several CPCs on a physical CP, if it is controlling several IP services.
In essence, the cohesion between a CP component and an FE component is the service abstraction.
0x1: Control Plane Components (CPCs)
Control Plane Components encompass signalling protocols, with diversity ranging from dynamic routing protocols, such as OSPF to tag distribution protocols, such as CR-LDP. Classical management protocols and activities also fall under this category.
These include SNMP、COPS、and proprietary CLI/GUI configuration mechanisms. The purpose of the control plane is to provide an execution environment for the above-mentioned activities with the ultimate goal being to configure and manage the second Network Element (NE) component: the FE. The result of the configuration defines the way that packets traversing the FE are treated.
0x2: Forwarding Engine Components (FECs)
The FE is the entity of the NE that incoming packets (from the network into the NE) first encounter.
The FE‘s service-specific component massages the packet to provide it with a treatment to achieve an IP service, as defined by the Control Plane Components for that IP service. Different services will utilize different FECs. Service modules may be chained to achieve a more complex service
When built for providing a specific service, the FE service component will adhere to a forwarding model.
1. Linux IP Forwarding Engine Model
____ +---------------+ +->-| FW |---> | TCP, UDP, ... | | +----+ +---------------+ | | ^ v | _|_ +----<----+ | FW | | +----+ ^ | | Y To host From host stack stack ^ | |_____ | Ingress ^ Y device ____ +-------+ +|---|--+ ____ +--------+ Egress ->----->| FW |-->|Ingress|-->---->| Forw- |->| FW |->| Egress | device +----+ | TC | | ard | +----+ | TC |--> +-------+ +-------+ +--------+
The figure above shows the Linux FE model per device. The only mandatory part of the datapath is the Forwarding module, which is RFC 1812 conformant. The different Firewall (FW), Ingress Traffic Control, and Egress Traffic Control building blocks are not mandatory in the datapath and may even be used to bypass the RFC 1812 module.
These modules are shown as simple blocks in the datapath but, in fact, could be multiple cascaded, independent submodules within the indicated blocks.
2. IP Services
In the diagram below, we show a simple FE<->CP setup to provide an example of the classical IPv4 service with an extension to do some basic QoS egress scheduling and illustrate how the setup fits in this described model.
Control Plane (CP) .------------------------------------ | /^^^^^^\ /^^^^^^\ | | | | | COPS |-\ | | | ospfd | | PEP | \ | | \ / \_____/ | | /------\_____/ | / | | | | | / | | |_________\__________|____|_________| | | | | ****************************************** Forwarding ************* Netlink layer ************ Engine (FE) ***************************************** .-------------|-----------|----------|---|------------- | IPv4 forwarding | | | | FE Service / / | | Component / / | | ---------------/---------------/--------- | | | | / | | packet | | --------|-- ----|----- | packet in | | | IPv4 | | Egress | | out -->--->|------>|---->|Forwarding|----->| QoS |--->| ---->|-> | | | | | Scheduler| | | | | ----------- ---------- | | | | | | | --------------------------------------- | | | -------------------------------------------------------
0x3: Netlink Logical Model
In the diagram below we show a simple FEC<->CPC logical relationship. We use the IPv4 forwarding FEC (NETLINK_ROUTE, which is discussed further below) as an example.
Control Plane (CP) .------------------------------------ | /^^^^^\ /^^^^^\ | | | | / CPC-2 \ | | | CPC-1 | | COPS | | | | ospfd | | PEP | | | | / \____ _/ | | \____/ | | | | | | ****************************************| ************* BROADCAST WIRE ************ FE---------- *****************************************. | IPv4 forwarding | | | | | FEC | | | | | --------------/ ----|-----------|-------- | | | / | | | | | | .-------. .-------. .------. | | | | |Ingress| | IPv4 | |Egress| | | | | |police | |Forward| | QoS | | | | | |_______| |_______| |Sched | | | | | ------ | | | --------------------------------------- | | | -----------------------------------------------------
Netlink logically models FECs and CPCs in the form of nodes interconnected to each other via a broadcast wire.
The wire is specific to a service. The example above shows the broadcast wire belonging to the extended IPv4 forwarding service.
Nodes (CPCs or FECs as illustrated above) connect to the wire and register to receive specific messages. CPCs may connect to multiple wires if it helps them to control the service better. All nodes(CPCs and FECs) dump packets on the broadcast wire. Packets can be discarded by the wire if they are malformed or not specifically formatted for the wire. Dropped packets are not seen by any of the nodes. The Netlink service may signal an error to the sender if it detects a malformatted Netlink packet.
0x4: Message Format
There are three levels to a Netlink message: The general Netlink message header, the IP service specific template, and the IP service specific data.
从网络的角度来看,Netlink是一种传输层通信协议
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | Netlink message header | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | IP Service Template | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | IP Service specific data in TLVs | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The Netlink message is used to communicate between the FEC and CPC for parameterization of the FECs, asynchronous event notification of FEC events to the CPCs, and statistics querying/gathering (typically by a CPC).
0x5: Protocol Model
1. Service Addressing
Access is provided by first connecting to the service on the FE. The connection is achieved by making a socket() system call to the PF_NETLINK domain. Each FEC is identified by a protocol number. One may open either SOCK_RAW or SOCK_DGRAM type sockets, although Netlink does not distinguish between the two. The socket connection provides the basis for the FE<->CP addressing.
Connecting to a service is followed (at any point during the life of the connection) by either issuing a service-specific command (from the CPC to the FEC, mostly for configuration purposes), issuing a statistics-collection command, or subscribing/unsubscribing to service events. Closing the socket terminates the transaction.
2. Netlink Message Header
Netlink messages consist of a byte stream with one or multiple Netlink headers and an associated payload. If the payload is too big to fit into a single message it, can be split over multiple Netlink messages, collectively called a multipart message. For multipart messages, the first and all following headers have the NLM_F_MULTI Netlink header flag set, except for the last header which has the Netlink header type NLMSG_DONE.
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Type | Flags | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Process ID (PID) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
3. The ACK Netlink Message
This message is actually used to denote both an ACK and a NACK. Typically, the direction is from FEC to CPC (in response to an ACK request message). However, the CPC should be able to send ACKs back to FEC when requested. The semantics for this are IP service specific.
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Netlink message header | | type = NLMSG_ERROR | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Error code | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | OLD Netlink message header | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Relevant Link:
https://tools.ietf.org/html/rfc3549
5. sendmsg、recvmsg In User Space
0x1: sendmsg
/source/net/socket.c
/* * BSD sendmsg interface */ SYSCALL_DEFINE3(sendmsg, int, fd, struct msghdr __user *, msg, unsigned, flags) { struct compat_msghdr __user *msg_compat = (struct compat_msghdr __user *)msg; struct socket *sock; struct sockaddr_storage address; struct iovec iovstack[UIO_FASTIOV], *iov = iovstack; unsigned char ctl[sizeof(struct cmsghdr) + 20] __attribute__ ((aligned(sizeof(__kernel_size_t)))); /* 20 is size of ipv6_pktinfo */ unsigned char *ctl_buf = ctl; struct msghdr msg_sys; int err, ctl_len, iov_size, total_len; int fput_needed; err = -EFAULT; if (MSG_CMSG_COMPAT & flags) { if (get_compat_msghdr(&msg_sys, msg_compat)) return -EFAULT; } else { err = copy_msghdr_from_user(&msg_sys, msg); if (err) return err; } sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; /* do not move before msg_sys is valid */ err = -EMSGSIZE; if (msg_sys.msg_iovlen > UIO_MAXIOV) goto out_put; /* Check whether to allocate the iovec area */ err = -ENOMEM; iov_size = msg_sys.msg_iovlen * sizeof(struct iovec); if (msg_sys.msg_iovlen > UIO_FASTIOV) { iov = sock_kmalloc(sock->sk, iov_size, GFP_KERNEL); if (!iov) goto out_put; } /* This will also move the address data into kernel space */ if (MSG_CMSG_COMPAT & flags) { err = verify_compat_iovec(&msg_sys, iov, (struct sockaddr *)&address, VERIFY_READ); } else err = verify_iovec(&msg_sys, iov, (struct sockaddr *)&address, VERIFY_READ); if (err < 0) goto out_freeiov; total_len = err; err = -ENOBUFS; if (msg_sys.msg_controllen > INT_MAX) goto out_freeiov; ctl_len = msg_sys.msg_controllen; if ((MSG_CMSG_COMPAT & flags) && ctl_len) { err = cmsghdr_from_user_compat_to_kern(&msg_sys, sock->sk, ctl, sizeof(ctl)); if (err) goto out_freeiov; ctl_buf = msg_sys.msg_control; ctl_len = msg_sys.msg_controllen; } else if (ctl_len) { if (ctl_len > sizeof(ctl)) { ctl_buf = sock_kmalloc(sock->sk, ctl_len, GFP_KERNEL); if (ctl_buf == NULL) goto out_freeiov; } err = -EFAULT; /* * Careful! Before this, msg_sys.msg_control contains a user pointer. * Afterwards, it will be a kernel pointer. Thus the compiler-assisted * checking falls down on this. */ if (copy_from_user(ctl_buf, (void __user *)msg_sys.msg_control, ctl_len)) goto out_freectl; msg_sys.msg_control = ctl_buf; } msg_sys.msg_flags = flags; if (sock->file->f_flags & O_NONBLOCK) msg_sys.msg_flags |= MSG_DONTWAIT; err = sock_sendmsg(sock, &msg_sys, total_len); out_freectl: if (ctl_buf != ctl) sock_kfree_s(sock->sk, ctl_buf, ctl_len); out_freeiov: if (iov != iovstack) sock_kfree_s(sock->sk, iov, iov_size); out_put: fput_light(sock->file, fput_needed); out: return err; }
/source/net/socket.c
int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size) { struct kiocb iocb; struct sock_iocb siocb; int ret; init_sync_kiocb(&iocb, NULL); iocb.private = &siocb; /* 调用__sock_sendmsg进行UDP数据报的发送 */ ret = __sock_sendmsg(&iocb, sock, msg, size); if (-EIOCBQUEUED == ret) ret = wait_on_sync_kiocb(&iocb); return ret; } static inline int __sock_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size) { struct sock_iocb *si = kiocb_to_siocb(iocb); int err; si->sock = sock; si->scm = NULL; si->msg = msg; si->size = size; err = security_socket_sendmsg(sock, msg, size); if (err) return err; /* const struct proto_ops inet_dgram_ops = { .family = PF_INET, .owner = THIS_MODULE, .release = inet_release, .bind = inet_bind, .connect = inet_dgram_connect, .socketpair = sock_no_socketpair, .accept = sock_no_accept, .getname = inet_getname, .poll = udp_poll, .ioctl = inet_ioctl, .listen = sock_no_listen, .shutdown = inet_shutdown, .setsockopt = sock_common_setsockopt, .getsockopt = sock_common_getsockopt, .sendmsg = inet_sendmsg, .recvmsg = sock_common_recvmsg, .mmap = sock_no_mmap, .sendpage = inet_sendpage, #ifdef CONFIG_COMPAT .compat_setsockopt = compat_sock_common_setsockopt, .compat_getsockopt = compat_sock_common_getsockopt, #endif }; EXPORT_SYMBOL(inet_dgram_ops); 从结构体中可以看出,sendmsg()对应的系统调用是inet_sendmsg() 我们继续跟进分析inet_sendmsg() \linux-2.6.32.63\net\ipv4\af_inet.c */ return sock->ops->sendmsg(iocb, sock, msg, size); }
\linux-2.6.32.63\net\ipv4\af_inet.c
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size) { struct sock *sk = sock->sk; /* We may need to bind the socket. */ if (!inet_sk(sk)->num && inet_autobind(sk)) return -EAGAIN; /* INET SOCKET调用协议特有sendmsg操作符 对于INET socket中的udp发送,协议特有操作符集为udp_prot linux-2.6.32.63\net\ipv4\udp.c struct proto udp_prot = { .name = "UDP", .owner = THIS_MODULE, .close = udp_lib_close, .connect = ip4_datagram_connect, .disconnect = udp_disconnect, .ioctl = udp_ioctl, .destroy = udp_destroy_sock, .setsockopt = udp_setsockopt, .getsockopt = udp_getsockopt, .sendmsg = udp_sendmsg, .recvmsg = udp_recvmsg, .sendpage = udp_sendpage, .backlog_rcv = __udp_queue_rcv_skb, .hash = udp_lib_hash, .unhash = udp_lib_unhash, .get_port = udp_v4_get_port, .memory_allocated = &udp_memory_allocated, .sysctl_mem = sysctl_udp_mem, .sysctl_wmem = &sysctl_udp_wmem_min, .sysctl_rmem = &sysctl_udp_rmem_min, .obj_size = sizeof(struct udp_sock), .slab_flags = SLAB_DESTROY_BY_RCU, .h.udp_table = &udp_table, #ifdef CONFIG_COMPAT .compat_setsockopt = compat_udp_setsockopt, .compat_getsockopt = compat_udp_getsockopt, #endif }; EXPORT_SYMBOL(udp_prot); 可以看出,对于UDP,流程进入udp_sendmsg函数(.sendmsg对应的是udp_sendmsg()函数),我们继续跟进udp_sendmsg() \linux-2.6.32.63\net\ipv4\udp.c */ return sk->sk_prot->sendmsg(iocb, sk, msg, size); } EXPORT_SYMBOL(inet_sendmsg);
0x2: recvmsg
/source/net/socket.c
/* * BSD recvmsg interface */ SYSCALL_DEFINE3(recvmsg, int, fd, struct msghdr __user *, msg, unsigned int, flags) { struct compat_msghdr __user *msg_compat = (struct compat_msghdr __user *)msg; struct socket *sock; struct iovec iovstack[UIO_FASTIOV]; struct iovec *iov = iovstack; struct msghdr msg_sys; unsigned long cmsg_ptr; int err, iov_size, total_len, len; int fput_needed; /* kernel mode address */ struct sockaddr_storage addr; /* user mode address pointers */ struct sockaddr __user *uaddr; int __user *uaddr_len; if (MSG_CMSG_COMPAT & flags) { if (get_compat_msghdr(&msg_sys, msg_compat)) return -EFAULT; } else { err = copy_msghdr_from_user(&msg_sys, msg); if (err) return err; } sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; err = -EMSGSIZE; if (msg_sys.msg_iovlen > UIO_MAXIOV) goto out_put; /* Check whether to allocate the iovec area */ err = -ENOMEM; iov_size = msg_sys.msg_iovlen * sizeof(struct iovec); if (msg_sys.msg_iovlen > UIO_FASTIOV) { iov = sock_kmalloc(sock->sk, iov_size, GFP_KERNEL); if (!iov) goto out_put; } /* Save the user-mode address (verify_iovec will change the * kernel msghdr to use the kernel address space) */ uaddr = (__force void __user *)msg_sys.msg_name; uaddr_len = COMPAT_NAMELEN(msg); if (MSG_CMSG_COMPAT & flags) err = verify_compat_iovec(&msg_sys, iov, (struct sockaddr *)&addr, VERIFY_WRITE); else err = verify_iovec(&msg_sys, iov, (struct sockaddr *)&addr, VERIFY_WRITE); if (err < 0) goto out_freeiov; total_len = err; cmsg_ptr = (unsigned long)msg_sys.msg_control; msg_sys.msg_flags = flags & (MSG_CMSG_CLOEXEC|MSG_CMSG_COMPAT); /* We assume all kernel code knows the size of sockaddr_storage */ msg_sys.msg_namelen = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg_sys, total_len, flags); if (err < 0) goto out_freeiov; len = err; if (uaddr != NULL) { err = move_addr_to_user((struct sockaddr *)&addr, msg_sys.msg_namelen, uaddr, uaddr_len); if (err < 0) goto out_freeiov; } err = __put_user((msg_sys.msg_flags & ~MSG_CMSG_COMPAT), COMPAT_FLAGS(msg)); if (err) goto out_freeiov; if (MSG_CMSG_COMPAT & flags) err = __put_user((unsigned long)msg_sys.msg_control - cmsg_ptr, &msg_compat->msg_controllen); else err = __put_user((unsigned long)msg_sys.msg_control - cmsg_ptr, &msg->msg_controllen); if (err) goto out_freeiov; err = len; out_freeiov: if (iov != iovstack) sock_kfree_s(sock->sk, iov, iov_size); out_put: fput_light(sock->file, fput_needed); out: return err; }
6. kernel_recvmsg、kernel_sendmsg In Kernel Space
0x1: kernel_recvmsg
/source/net/socket.c
int kernel_recvmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size, int flags) { mm_segment_t oldfs = get_fs(); int result; set_fs(KERNEL_DS); /* * the following is safe, since for compiler definitions of kvec and * iovec are identical, yielding the same in-core layout and alignment */ msg->msg_iov = (struct iovec *)vec, msg->msg_iovlen = num; result = sock_recvmsg(sock, msg, size, flags); set_fs(oldfs); return result; }
对于内核态来说,数据包此时已经copy到了Netlink的KERNEL态缓存了
0x2: kernel_sendmsg
/source/net/socket.c
int kernel_sendmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size) { mm_segment_t oldfs = get_fs(); int result; set_fs(KERNEL_DS); /* * the following is safe, since for compiler definitions of kvec and * iovec are identical, yielding the same in-core layout and alignment */ msg->msg_iov = (struct iovec *)vec; msg->msg_iovlen = num; result = sock_sendmsg(sock, msg, size); set_fs(oldfs); return result; }
Relevant Link:
http://www.opensource.apple.com/source/Heimdal/Heimdal-247.9/lib/roken/sendmsg.c https://fossies.org/dox/glibc-2.21/sysdeps_2mach_2hurd_2sendmsg_8c_source.html http://lxr.free-electrons.com/source/net/socket.c
7. NetLink Sockets C++ Library
0x1: Features
1. Cross Platform Library 2. Easy to use 3. Powerful and Reliable 4. Supports both Ip4 and Ip6 5. SocketGroup class to manage the connections 6. OnAcceptReady, OnReadReady, OnDisconnect callback model 7. Fully documented library API 8. Enables to Develop socket functionality extremely Fast 9. Fits single threaded and multi-threaded designs
Relevant Link:
http://sourceforge.net/projects/netlinksockets/
8. Netlink Protocol Library Suite (libnl)
The libnl suite is a collection of libraries providing APIs to netlink protocol based Linux kernel interfaces.
Netlink is a IPC mechanism primarly between the kernel and user space processes. It was designed to be a more flexible successor to ioctl to provide mainly networking related kernel configuration and monitoring interfaces.
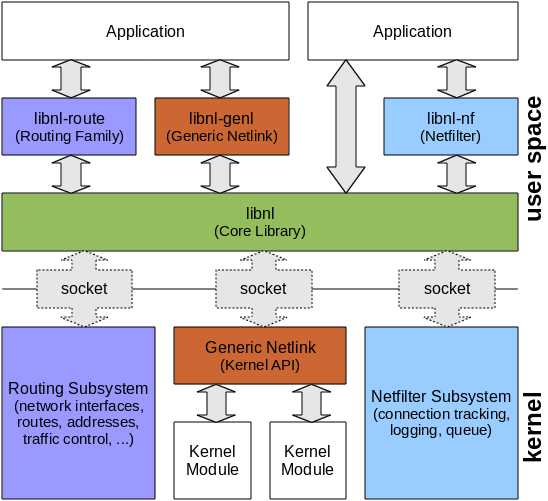
The interfaces are split into several small libraries to not force applications to link against a single, bloated library.
0x1: libnl
Core library implementing the fundamentals required to use the netlink protocol such as socket handling, message construction and parsing, and sending and receiving of data. This library is kept small and minimalistic. Other libraries of the suite depend on this library.
0x2: libnl-route
API to the configuration interfaces of the NETLINK_ROUTE family including network interfaces, routes, addresses, neighbours, and traffic control.
0x3: libnl-genl
API to the generic netlink protocol, an extended version of the netlink protocol.
0x4: libnl-nf
API to netlink based netfilter configuration and monitoring interfaces (conntrack, log, queue)
Relevant Link:
http://www.carisma.slowglass.com/~tgr/libnl/ http://www.carisma.slowglass.com/~tgr/libnl/doc/core.html
Copyright (c) 2015 LittleHann All rights reserved
NetLink Communication Mechanism And Netlink Sourcecode Analysis
标签:
原文地址:http://www.cnblogs.com/LittleHann/p/4418754.html