标签:
开篇介绍
SQL Profilling Task 可能我们很多人都没有在 SSIS 中真正使用过,所以对于这个控件的用法可能也不太了解。那我们换一个讲法,假设我们有这样的一个需求 - 需要对数据库表中的一些数据做一些数据分析,比如统计一下数据表中各列中实际数据的长度,各长度区间范围;比如统计一下各数据列中非空字段的比例,表的行数,重复字段等等。那么如果不是专门做过这种数据源数据分析的话,可能不知道用什么方式能够非常快的得到这些信息。写 SQL 语句?我想这个过程也是非常耗费时间和精力的。
实际上,在 SSIS 2012 中有这么一个控件 SQL Profilling Task 可以帮助我们做到这些事情,对数据源的数据快速的做出分析。能够非常快速的弄清楚我们面对的数据源是什么样的一种特征,这些将在实际 ETL 处理过程中对我们 BI 开发人员是非常有帮助的。并且,还有一种情况,我们可以将这种数据分析的结果直接在 SSIS 中通过邮件发送给相关的数据库管理员,或者数据分析和管理人员,那么他们对这种数据的了解会更加清晰,更早的判断出数据源中的数据异常等问题。
SQL Profilling Task 的初步体验
新建一个包,并新建一个 ADO.NET 链接管理器,这次我们的测试源对象可以换成任意一个数据库,那我这里把数据源换成 AdventureWorkLT2012 数据库。
注意:在这里必须使用 ADO.NET 链接管理器,这是一个特别的限制,并且只支持 SQL Server 版本。另外一个就是必须对 tempdb 数据库有读写权限,因为这里面有大量的计算,聚合汇总等过程。
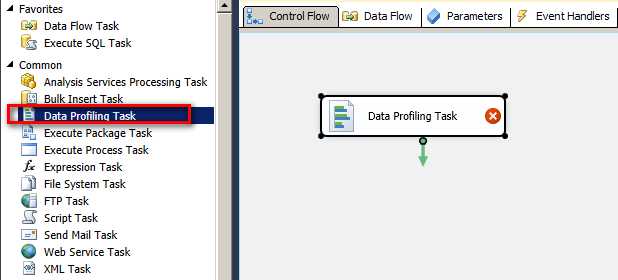
拖放一个 SQL Profilling Task到控制流中。
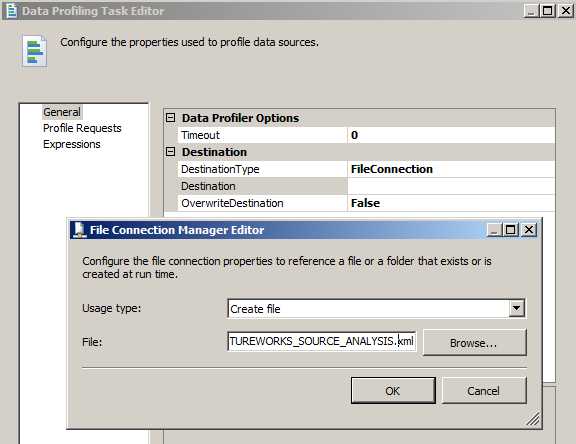
双击编辑,第一件要做的事情就是创建一个 XML 文件来保存 SQL Profilling Task 对指定数据源,表的分析结果的文件。OverwriteDestination 可以每次指定让它覆盖掉以前的旧文件,但是另外一种方式就是根据执行日期去生成不同的文件,关于这一点在前面很多例子中就已经提到了。
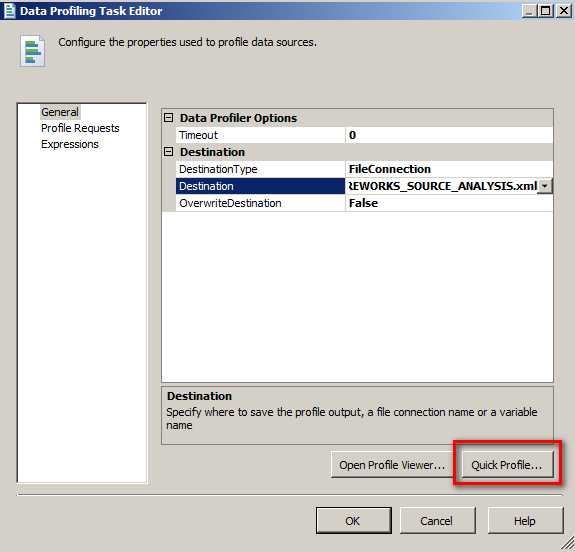
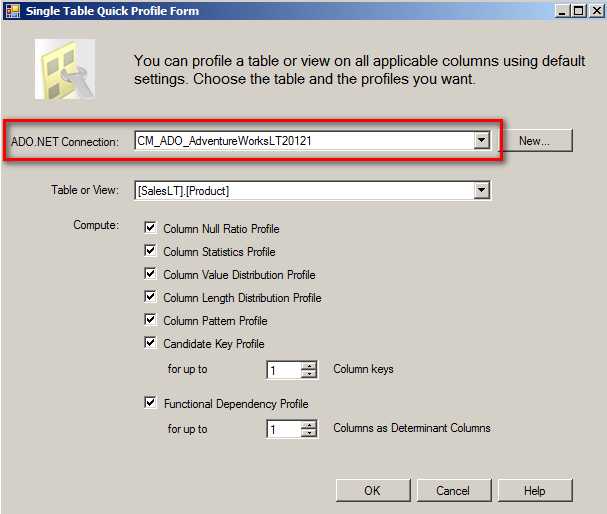
选择 Quick Profile
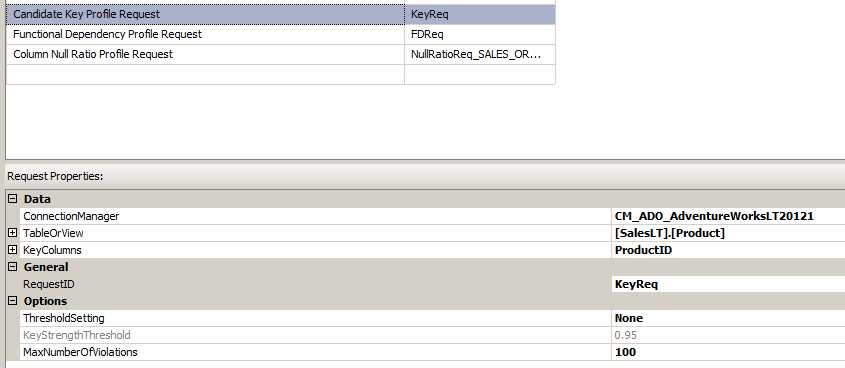
在这里选择好之前创建好的 ADO.NET 链接管理器,并选择表或者视图; 我们在这里首先配置的是表 Product,配置完成之后对于后面所有的表是都可以看的到的。
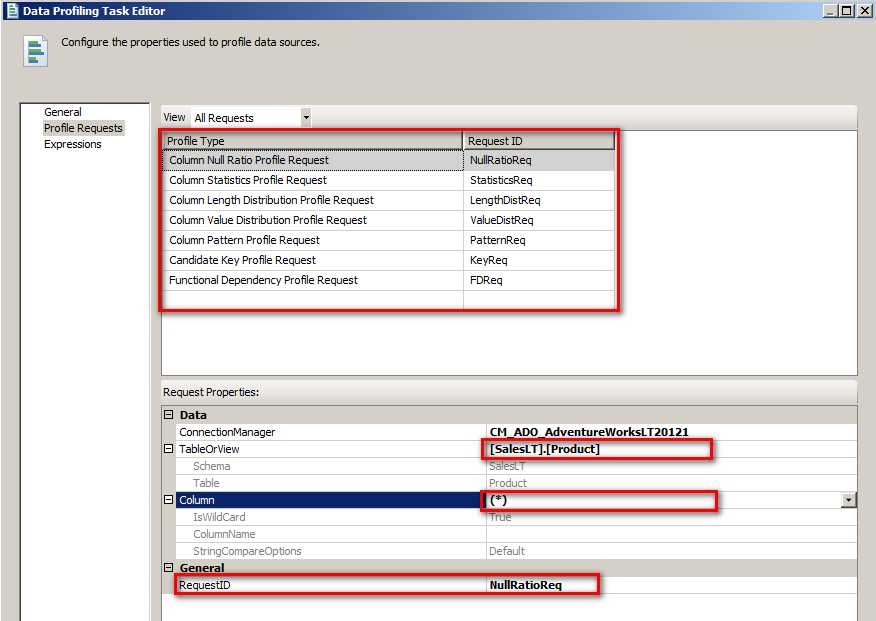
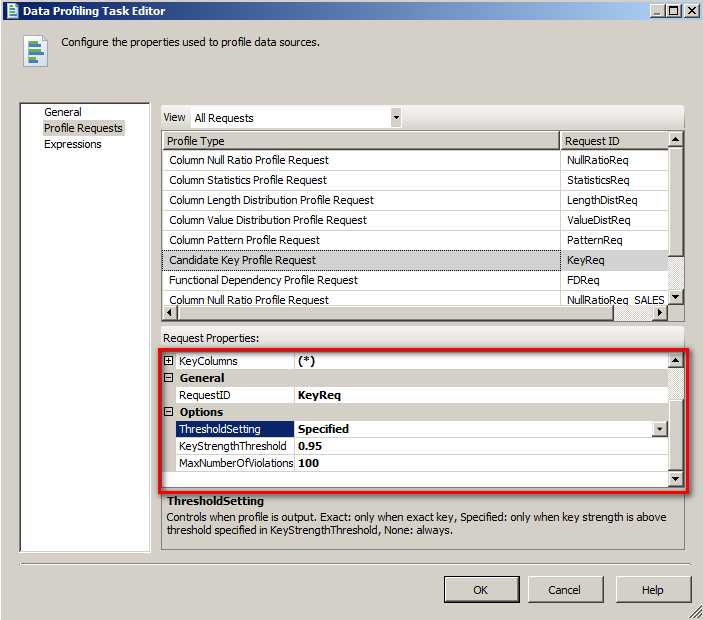
上面配置完成后,将跳转到 Profile Requests 处,在这里需要选中每一种 Profile,然后根据需要对每一张表的全部字段 (*) 或者某一个字段做 NULL 值检查。里面的每一项 Profile Type 都是进行差异化配置的,即不同的表,不同的列可以配置或者不配置,默认情况下都是 Product 表的配置。
这一点体验是不太好的,就是如果我需要重新添加一张新的表的话,我们需要创建新的 Profile Type - 在 Profile Type 下面点击空白的地方新创建一个 Profile Request。
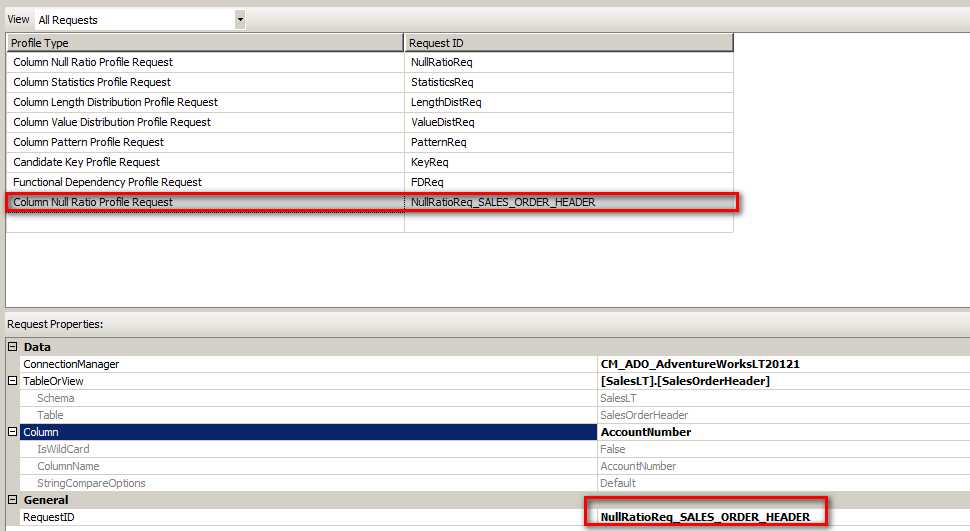
我们继续为 SalesOrderHeader 表的 AccountNumber 做出空值统计处理。
保存之后运行包,并打开生成之后的 XML 文件。
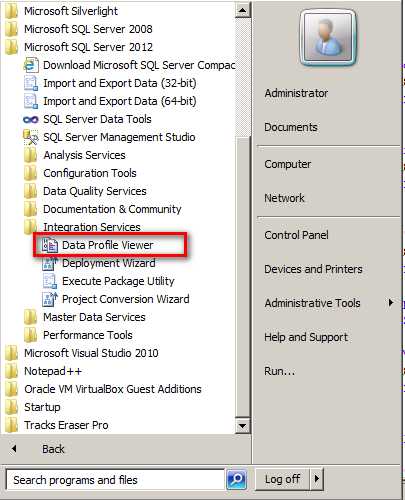
很明显,这个 XML 文件即使拿到手也是看不出来什么的,正确的打开方式应该是通过 SQL Server 2012 自带的 Data Profile Viewer 工具来查看。
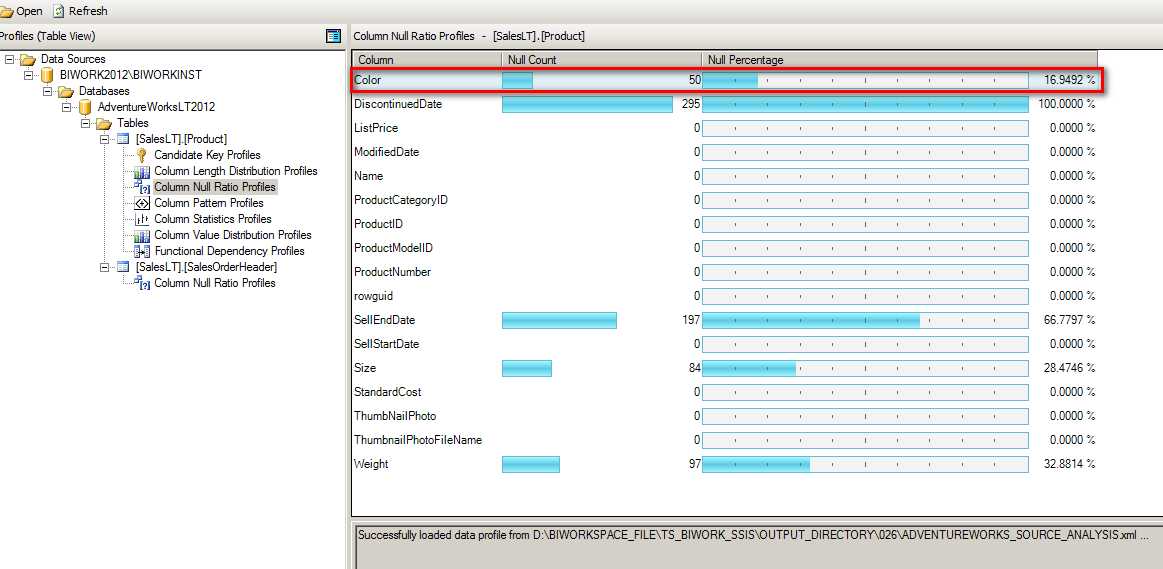
打开 Data Profile Viewer 之后加载包产出的 XML 文件,可以看到图形化的分析结果。
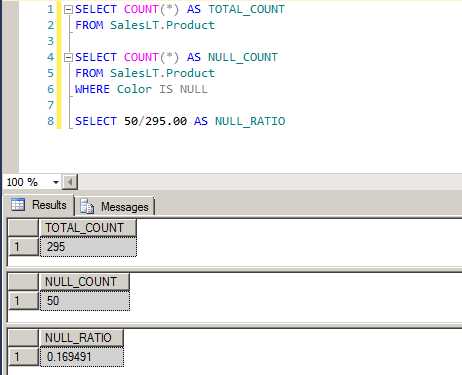
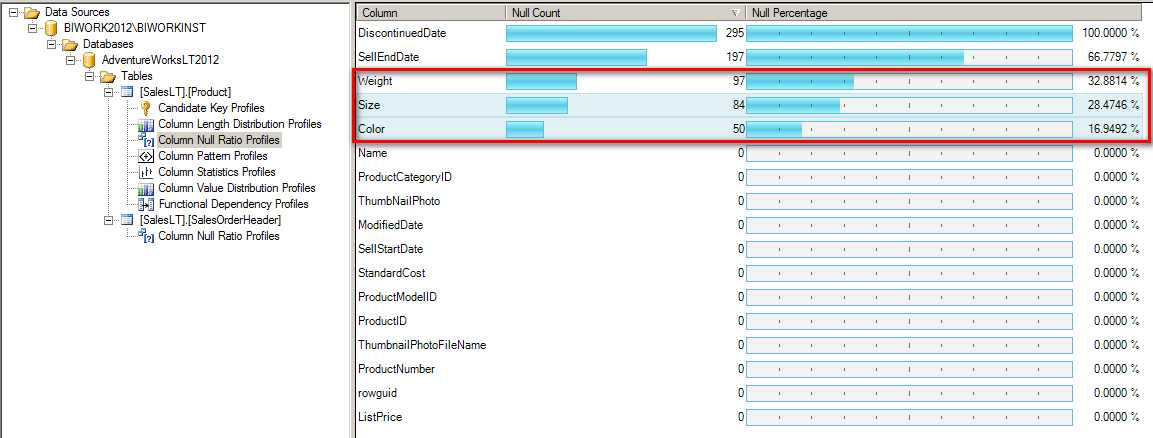
以 Product 表中 Color 为例,NULL 值的条数有50条,占了总行数的 16.94 %。
我们来验证一下结果,发现和上面的分析结果是一致的。
下面就对这几种 Profile Type 做一个详细的解释。
单列统计类型
Null Ratio Profile (NULL 比率统计)
一般用来检查在数据列中 NULL 值的所占比例,比如说通过分析的结果发现某一列的 NULL 值所占比较过高,可能超过了预期,那么这种情况下是不是数据不太正常,丢值太多。比如在客户关系管理系统中,作为非常重要的联系方式 - 手机号码,电子邮件,地址等。对于这三者来说 NULL 值所占的比例应该手机号码最小,地址和电子邮件其次,并且手机号码的 NULL 值比例应该非常非常小才是正常的。如果作为重要分析因素的手机号码的 NULL 值比例非常高,这时就说明我们的数据源数据存在一些问题,那么就需要引起注意。有可能是业务操作不规范,也有可能是数据源准备数据的时候出现问题。
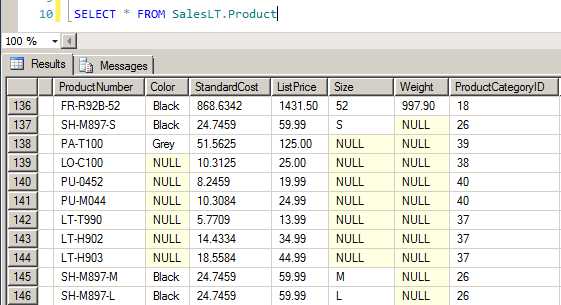
比如在下面的几个列中, Color, Size, Weight 就可以通过 SQL Profilling Task 获取到具体的 NULL Ratio 比例。
可以看出数据源中的 Weight, Size, Color NULL 值比较从高到低,Weight 列种有97条空值,所占比例 32.88%。至于这个数据是否合理就需要和业务人员来确定了,也就是说我们在设计我们的数据仓库时,做为数据分析的依据时这些信息是事先就应该要了解的。
Column Length Distribution Profiles ( 列长度分布统计数据 )
对于列中的数据长度去重并进行统计各长度所占全部数据行的个数与比例。这个 Profile 有助于帮助我们了解,第一是业务数据源中的数据长度定义是否是合理的,比如说业务数据源中的这一列在历史 5 - 10 年中的数据长度最长就是 35,但是定义了255 的长度。那么我们在数据抽取的时候,来定义我们表列的长度时这个就是依据,因为我们发现历史上所有的数据长度都没有超过 35。第二是可以查看到异常数据,比如身份证号码一般默认大概是 18 位,那么在这个图中就可以非常容易的看出来是否存在异常数据,比如说有大量的超过 18 位,或者小于 18 位的数据。
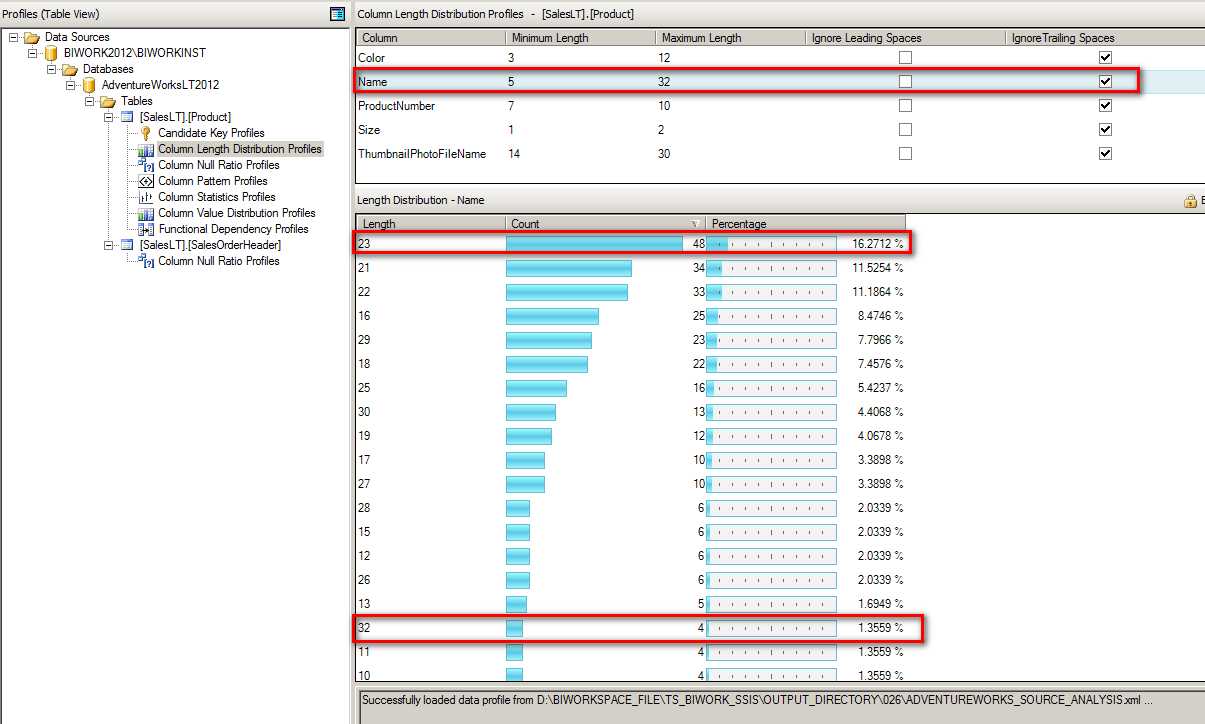
比如下图中,Name 列中最小长度是5,最大是 32,长度为 23 的数据占据比例最高。
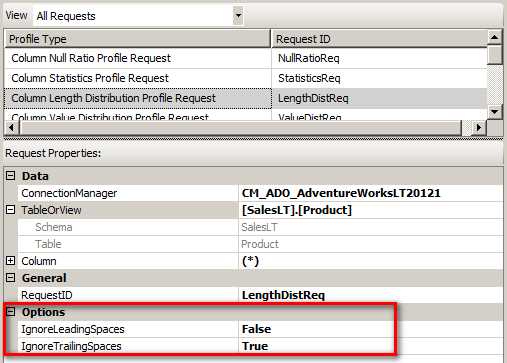
当然在设计长度检测时候,对于空格的处理也是非常方便的。IgnoreLeadingSpaces - 是否忽略开通的空格,IgnoreTrailingSpaces - 是否忽略结尾的空格。
Statistics Profiles (列统计信息)
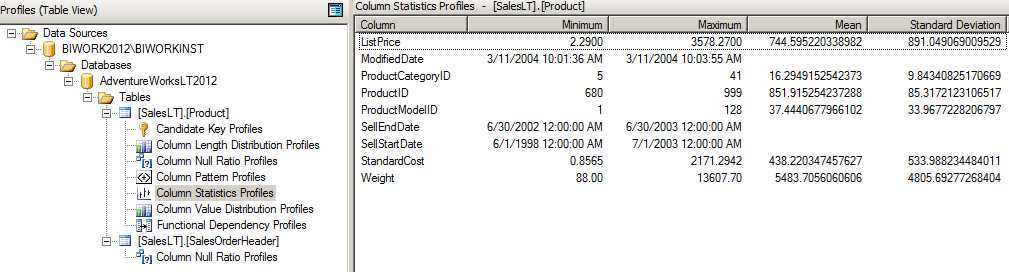
这种统计是非常有意义的,特别是对于数字,日期类型的字段,可以非常直观的看到它们的最大,最小,平均值,以及标准差值(时间只有最大,最小)。通过这些统计可以看到数据是否存在异常情况,比如价格的最大和最小值会不会出现负值,最大值是否偏离的离谱等等。
关于这里面的平均值 Mean 还有 Standard Deviation 请参考统计学中的平均值和标准差等计算方式。

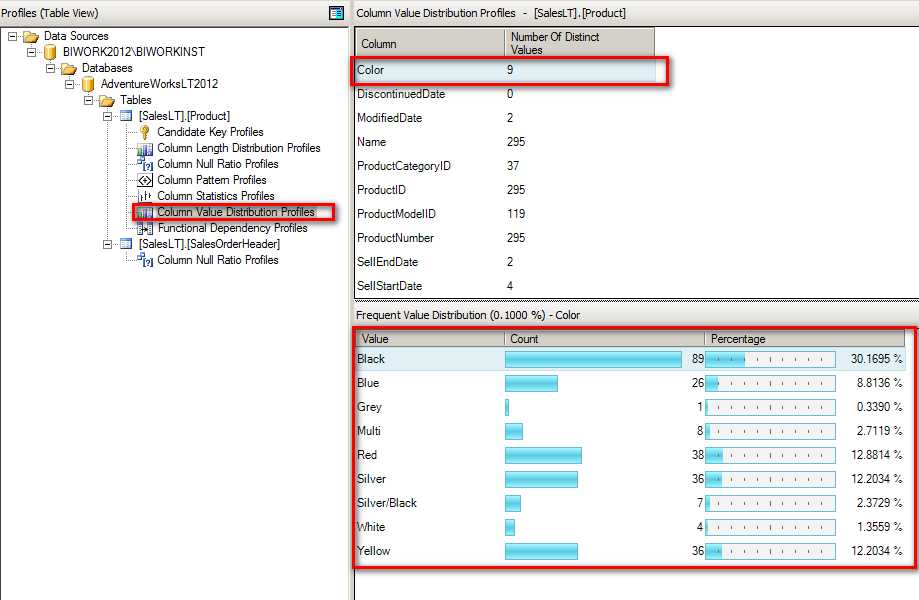
Value Distribution (列值分布统计)
去重之后列的值分布情况,那么这种统计一方面可以帮助了解源数据中有哪些数据可以作为分类出现,哪些数据基数很大不适合做这种分类。另外一个,这种统计也可以帮助我们鉴别列中数据的质量。比如说中国的省份经值分布统计之后发现多达上百个,那么这种数据是有问题的,会非常容易的看出来。
以下图为例,可以非常明显的看到各个列中值的分配情况,像 Color 这种列是非常适合作为维度的一个属性用来分析事实表中的数据的,但是像 ProductNumber 这种基数太大不适用用来分析事实数据。并且在 Color 列中也可以非常直观的看到哪一种颜色的产品目前最多,所占的比例是多少都非常清楚。
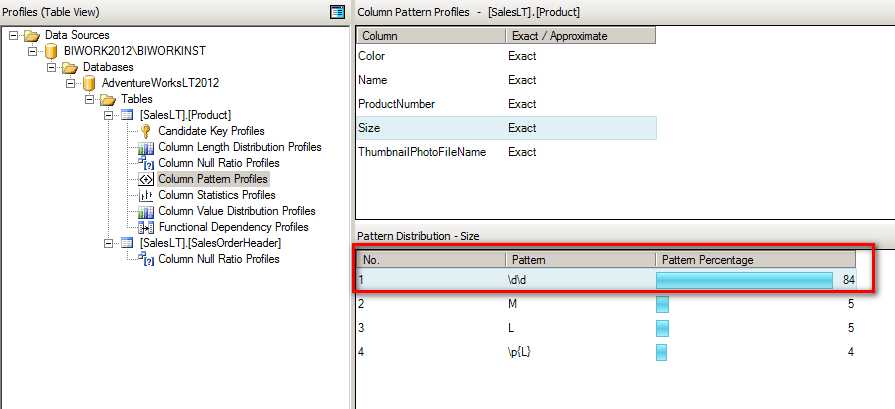
Pattern Profiles(列模式,正则表达式分配统计)
为字符串类型的数据提供正则统计,比如邮件地址的正则一般只有有一种正则表达式,如果看到的是其它的表达式有可能说明以前的验证是错误的。还有就是通过对统计数据的分析可以看到哪一种表达式所占据的比例多,高,越多越高的说明这种比例应该是正常的,可以考虑以后所有的验证按照这一种走。至于其它的可以考虑如果是业应用中修改,或者在抽取数据的时候认为这种数据是异常的,是需要处理的。
例如下图中产品 Size 大小的表达式正则为 \d\d,占据了 84% 的数据比,说明大多数 Size 的内容都是数字类型的,但是也有一些填写的值是 M, L 这种字符类型的;那么像这种数据再抽取到数据仓库之前就可以发现,所以才有时间来考虑这种少量的非规则的数据应该如何来处理了。
多列或表级别探测类型
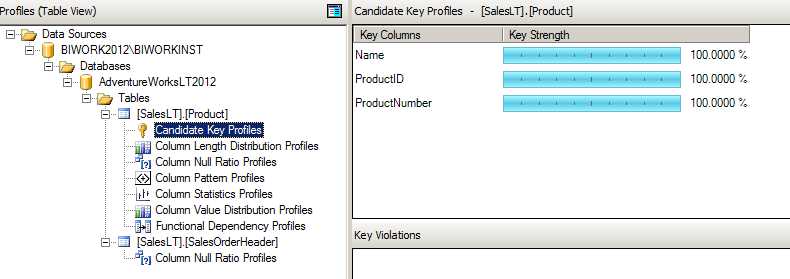
Candidate Key Profile (候选主键探查)
对于选择要探测统计的列进行统计,看看它是否符合主键的特征,或者近似主键。比如说,我们可能觉得某一列应该作为主键,但是最终统计下来发现因为存在重复值只能作为近似主键存在,那么在选择时候就要注意了。
比如在下图中的这三列都是非重复列,100%的符合了主键的特征,因此这几列可以作为主键候选列来考虑。当然最终如何选择,这个分析只能是一个参考,比如我们还需要考虑字段的类型,长度等因素,尽量选择整型数据;即使是字符串的话,也应该选择长度更短的列。
但是这个值是不是 100% 完全与实际相符的,不一定,这里的显示和配置 Candidate Key Profile 时有关。
比如在选择 Specified 的时候就可以列出所有的列 (*),当非重复率达到 95%以上的时候就应该认为是 100%了。
而在选择 None 的时候这时需要选择到固定的列,或者一个列两个列组合形成。
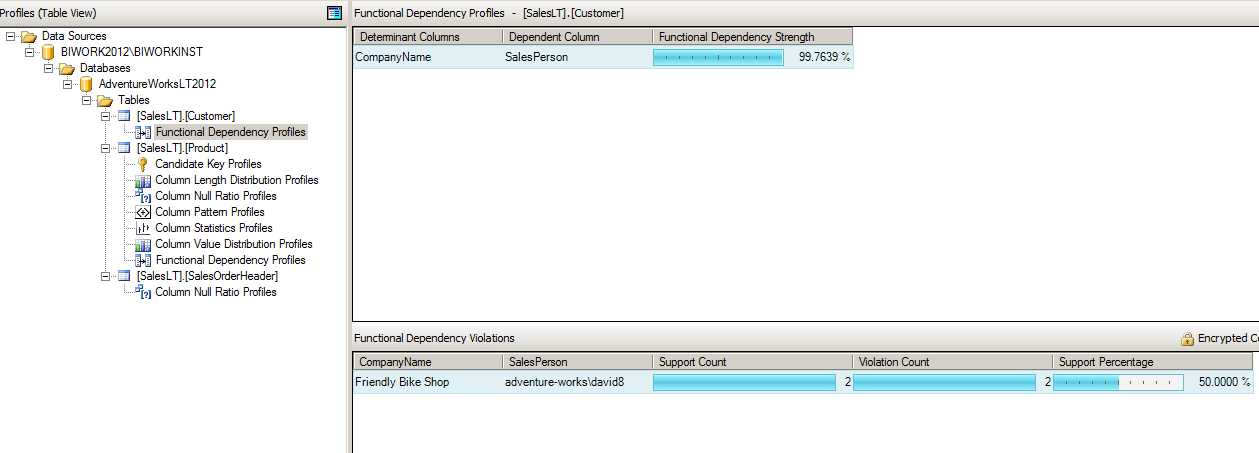
Functional Dependency Strength Profile (函数依赖关系统计)
可以这么来理解这个统计所做的事情,比如说在一个销售统计里,有国家,省份和城市,一个城市必定属于一个省份,而一个省份也必定属于一个国家。如果在数据中比如说我们发现了城市,例如杭州属于浙江的同时,它在另外的一条记录中也属于了省份江苏,那么很明显这个数据是有问题的。
函数依赖关系就可以检测这种依赖关系,比如在 1000 条带有杭州的数据中,有 999个杭州的数据对应的省份是浙江,有1个不是,那么杭州对浙江的依赖比率应该达到 90%以上了。
比如下面这幅图中,SalesPerson 对 CompanyName 的“依赖”,CompanyName 对 SalesPerson 的"决定性"达到了 99.76%。换句话说,只要知道了 Company Name 就有 99.76% 的可能能够确定它的 Sales Person 是谁? 只要知道了城市是杭州,那么就有百分之多少的可能知道省份是谁,当然城市与省份之间的决定应该达到 100%。
在 Friendly Bike Shop 中有 4 条数据,其中两条是能够决定 Sales Person 是 adventure-works\david8,另外两条不是的,因此这种依赖率是 50%,但是整体上所有的数据这种依赖率是 99.76%。
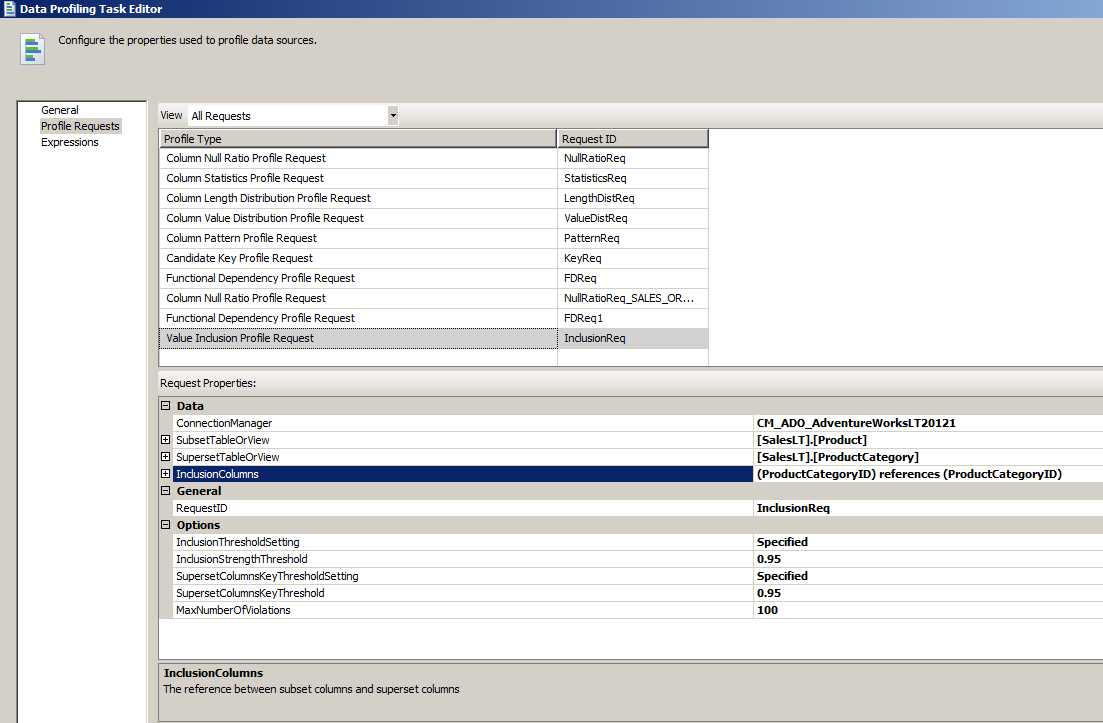
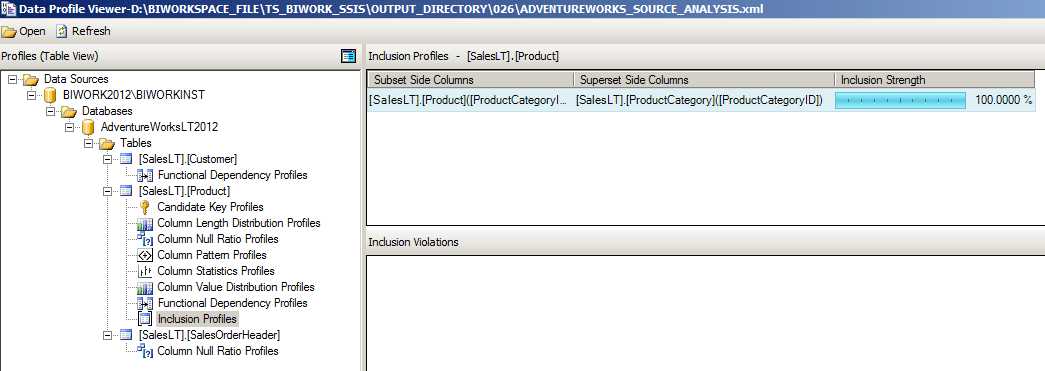
Value Inclusion Profile 值包含统计
主要用来计算两个列之间或者多个组合列之间列值的重合情况,通过 Value Inclusion 值统计可以大概决定比如两个表之间的列是否适合建立外键的引用关系。或者,从另外的一个角度来说,如果这一张表的某列引用了另外一张表,形成了理论上的这种外键关联;那么通过值包含统计就可以看出来这种关联是否正确,比如 B 表的某列的值都是来源于 A 表的某列,但是通过探测发现 B 表某列的值在 A 表中是找不到的。
因为在这里没有特别好的例子,在已经建立好外键关系的表中这种探测肯定是没有任何问题的,所以我们在这里只是来理解一下 Value Inclusion 的用法即可。
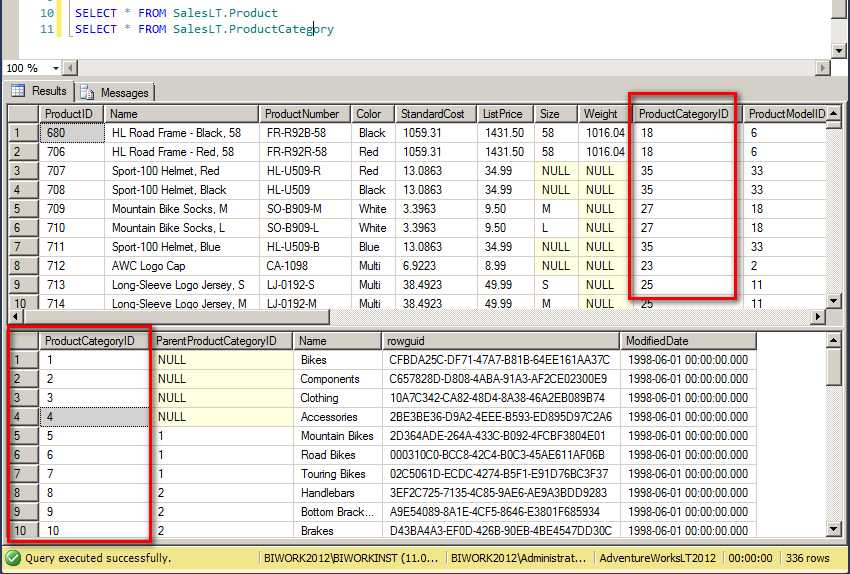
我们来看看 Product 表中的 ProductCategoryID 对 ProductCategory 表中的 ProductCategoryID 的引用情况(值包含情况)。
最后的结果不出意料基本上就是 100%的关联率。
总结
在 BI 系统中,最重要的一个环节莫过于 ETL 了,而数据源又与 ETL 的设计与开发息息相关。特别对于一些没有良好维护的数据源,其质量的好坏将在很大程度上影响 ETL 的设计。因此理解好数据源,分析好数据源的数据对后期的 ETL ,表的设计起着非常重要的作用。 我们可以通过 SQL Profilling Task 对我们的数据源有一个大致的了解,通过以上的这几种方式的分析,基本上可以满足绝大部分数据探测的需要。特别对于那种应用系统边升级,BI 系统边升级的的项目,应用系统本身并不健全的情况下,其数据的质量上也可能是存在很大问题的,这样就给我们的 BI 设计带来了很多不不好的影响。所以在一些 ETL 设计中,我们甚至可以采用在 SSIS 中通过邮件周期性的发送这种探测报告给 BI 系统维护人员,尽量地做到周期性的对源数据的预防性检查工作,提前避免一些不规范的数据带来的意外后果。
最后提一下,还有一件事情要做! 如果老是去分析这个 XML 是不应该的,因为这种数据都不能集中呈现历史数据的。因此最好的方式是解析 XML 文件,将数据解析的结果保存到数据库中,自己用报表的形式来呈现。这样不光可以看到当前的结果,而且还可以对比之前所有的历史结果,做到对数据源的探测管理 - 数据源的监控管理也是属于 BI 监控管理的一部分,关于这一部分就不详细展开了!
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSIS 系列 - 使用 SQL Profilling Task (数据探测) 检测数据源数据
标签:
原文地址:http://www.cnblogs.com/biwork/p/4423597.html