标签:
hashmap作为java中非常重要的数据结构,对于key-value类型的存储(缓存,临时映射表,。。。)等不可或缺,hashmap本身是非线程安全的,对于多线程条件下需要做竞争条件处理,可以通过Collections和ConcurrentHashmap来替代。
hashmap存储数据主要是通过数组+链表实现的,通过将key的hashcode映射到数组的不同元素(桶,hash中的叫法),然后冲突的元素放入链表中。
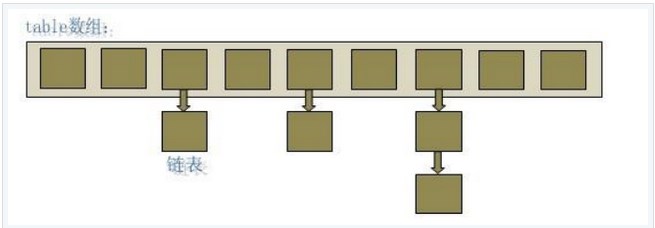
链表结构(Entry)

采用静态内部类

当存入的值为null的时候,操作会找到table[0],set key为null的值为新值
若果不是空值,则进行hash,

可以看到,算法进行了二次hash,使高位也参与到计算中,防止低位不变造成的hash冲突
注:这一切的目的实际上都是为了使value尽量分布到不同的
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把 hash 值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在 HashMap 中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:

这又要牵扯到hashmap的另外一个问题,关于length长度的定义
在put操作的开始,有判断table是否为空,如果为空则会初始化table,初始化的代码如下:
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
容量的提升都是以2的幂的方式
这段代码保证初始化时 HashMap 的容量总是 2 的 n 次方,即底层数组的长度总是为 2的 n 次方。当 length 总是 2 的 n 次方时,h& (length-1)运算等价于对 length 取模,也就是h%length,但是&比%具有更高的效率。
这看上去很简单,其实比较有玄机的,我们举个例子来说明:
假设数组长度分别为 15 和 16,优化后的 hash 码分别为 8 和 9,那么&运算后的结果如下:


读操作通过hash后的值,一样是调用indexFor方法找到对应的序号,然后遍历链表找到对应的value返回
resize只有在hashmap中元素的大小达到临界值的时候才会进行,而临界值和loadFactor 参数有关,只有数量达到loadFactor *table.length才会重新分配table,元素也将重新映射,这是非常耗性能的操作,所以最好一开始能确定元素的大概范围
HashMap 的性能参数(这段直接从参考文章引来):
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子
为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。HashMap 的基础构造器 HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量 initialCapacity 和加载因子 loadFactor。
initialCapacity:HashMap 的最大容量,即为底层数组的长度。
loadFactor:负载因子 loadFactor 定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap 的实现中,通过 threshold 字段来判断 HashMap 的最大容量:
Java 代码
threshold = (int)(capacity * loadFactor);
结合负载因子的定义公式可知, threshold 就是在此 loadFactor 和 capacity 对应下允许的最大元素数目,超过这个数目就重新 resize,以降低实际的负载因子。默认的的负载因子0.75 是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize 后的 HashMap容量是容量的两倍:
if (size++ >= threshold)
resize(2 * table.length);
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他
线程修改了 map,那么将抛出 ConcurrentModificationException,这就是所谓 fail-fast 策略。
这一策略在源码中的实现是通过 modCount 域, modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。
标签:
原文地址:http://my.oschina.net/zhenglingfei/blog/403146