标签:
说到Facet,我还真找不到一个合适的中文词汇来描述它,英文翻译是方面,感觉不够贴切,大家也不必纠结它的中文叫法是啥,你只需要知道使用Facet能解决什么类型的问题就行了,来看几个典型的应用案例:



看了上面几张图,大家应该知道Facet是用来干嘛的了,如果非要用语言描述Facet的用途,那Facet的用途就是根据域的域值进行分组统计,注意这 里的域必须是FacetField,你Facet域的域值有几个就会分几组,并统计在Query查询条件下各组的命中结果数量。但通常不需要显示所有分 组,就如图上面3张图,一般都是显示Top N 个分组即可。是不是觉得Facet和Group有点相似,对,看起来是有那么一点相似,那两者到底有什么区别呢?
Html代码 
They are two different lucene features:
Grouping was first released with Lucene 3.2, its related jira issue is LUCENE-1421: it allows to group search results by specified field. For example, if you group by the author field, then all documents with the same value in the author field fall into a single group. You will have a kind of tree as output. If you want to go deeper into using this lucene feature, this blog post should be useful.
Faceting was first released with Lucene 3.4, its related jira issue is LUCENE-3079: this feature doesn‘t group documents, it just tells you how many documents fall in a specific value of a facet. For example, if you have a facet based on the author field, you will receive a list of all your authors, and for each author you will know how many documents belong to that specific author. After, if you want to see those documents, you have to query one more time adding a specific filter (author=whatever). The faceted search is in fact based on browsing documents applying multiple filters to progressively reach the documents you‘re really interested in.
对不起,只有英文的说明,大意就是:Grouping分组功能是在跟随Lucene 3.2稳定版首次发布的,它允许你根据一个指定的域进行分组,举个例子,如果你根据一个author域进行分组,那么这个域的所有域值相同的索引文档进行 落入到这个分组中。Facet是在跟随Lucene3.4稳定版首次发布的,facet并不对文档进行分组,Facet只是告诉你某个Facet下每个域 值的命中数量,举个例子,如果你有个facet是基于author域的,那么facet会返回author域下的每个域值,以及每个author域值下的 命中结果总数。如果你想查看每个author域值下的命中结果,那么你可能需要再发起 一次请求,通过添加一个filter如author=xxxx. 其实Facet搜索就是通过应用多个filter来让用户浏览索引文档,使用户逐步找到自己感兴趣的索引文档,一句话:Facet分组统计的目的是通过 统计的数量诱发你点击的欲望,一般你看到数量多的,你会有点击欲望,点击进去了你自己会判断是不是你感兴趣的内容,如果不是,那么你会点击数据量次之的, 如此下去,逐步诱导你找到你感兴趣的内容,这就是Facet功能设计的目的。说白了就是利用羊群效应诱发你去点击。
首先来你需要创建FacetField域,在创建之前你需要了解FacetField的是否分词,存储,位置信息等。看看FacetField源码一切就知晓了。

FacetField的域名称都是dummy, 域类型都是默认的DOCS_AND_FREQS_AND_POSITIONS即需要记录Term频率和Document频率(即项向量)和位置信息。而 FieldType对于默认是Stored=false,而tokenized=true(即会进行分词处理转化为多个Term),了解这些很有必要。
然后FacetField跟普通的Field一样,需要添加到document中,然后document需要通过IndexWriter对象a调用addDocument写入索引,但此时document需要做一个转换过程,即
Java代码
FacetsConfig.build(DirectoryTaxonomyWriter writer,Document document);
我们来看看FacetsConfig的build方法背地里都干了些什么?

首先定义了3个Map分别对应了3种类型的FacetField:FacetField,SortedSetDocValuesFacetField,AssociationFacetField, FacetField就是普通的Facet域,SortedSetDocValuesFacetField就是可以用来排序的DocValuesField域,AssociationFacetField是用来自定义Facets的域,它可以关联任意的byte[]字节数组.把用户添加的域用3个map分开后,分别用了3个函数进行处理,如图: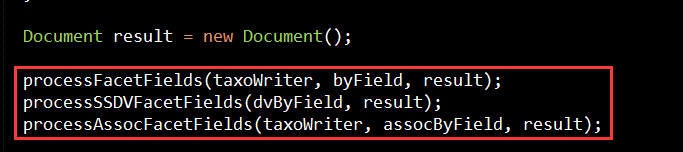
processFacetFields内部关键点代码就是:
pathToString就是把多个域值拼在一起,比如:
Java代码
new FacetField("Author", new String[] { "Bob" ,"Jack","Tom"})
那拼一起后就是BobJackTom,然后创建了一个StringField且Store.NO,意思就是我们add一个FacetField其实就是add了一个StringField,当然两者不能完全等同。注意是if里的条件:
ft.multiValued && (ft.hierarchical || ft.requireDimCount)即如果是多值域且(path有多个值或者需要统计facet总数),如果不是多值域,则会add一个BinaryDocValuesField域:
Java代码
doc.add(new BinaryDocValuesField(indexFieldName, dedupAndEncode(ordinals.get())));
然后我们通过IndexSearcher查询的时候需要传入FacetsCollector结果收集器,剩下的套路基本都是固定的,没什么好说的,如下:
Java代码
FacetsCollector fc = new FacetsCollector();
searcher.search(new MatchAllDocsQuery(), null, fc);
List<FacetResult> results = new ArrayList<FacetResult>();
Facets facets = new FastTaxonomyFacetCounts(taxoReader, this.config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
至于DrillDownQuery,他其实就是根据用户传入的path数组用BooleanQuery进行链接的:

先用BooleanQuery把多个TermQuery用Or链接起来,再用ConstantScoreQuery包装下,主要是为了禁用查询权重的。
至于DrillSideways更不需要被它的外表迷惑了,其实他内部其实还是根据传入的IndexSearch和Facet结果收集器去查询的:
内部就是为了包装得到一个DrillSidewaysQuery对象,最后还是调用的IndexSearcher的search方法。
下面是一个Facet使用简单示例:
Java代码
package com.yida.framework.lucene5.facet;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.facet.DrillDownQuery;
import org.apache.lucene.facet.DrillSideways;
import org.apache.lucene.facet.FacetField;
import org.apache.lucene.facet.FacetResult;
import org.apache.lucene.facet.Facets;
import org.apache.lucene.facet.FacetsCollector;
import org.apache.lucene.facet.FacetsConfig;
import org.apache.lucene.facet.taxonomy.FastTaxonomyFacetCounts;
import org.apache.lucene.facet.taxonomy.TaxonomyReader;
import org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyReader;
import org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
/**
* Facet简单示例
*
* @author Lanxiaowei
*
*/
public class SimpleFacetsExample {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
public SimpleFacetsExample() {
this.config.setHierarchical("Author", true);
this.config.setHierarchical("Publish Date", true);
}
/**
* 创建测试索引
*
* @throws IOException
*/
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(this.indexDir,
new IndexWriterConfig(new WhitespaceAnalyzer())
.setOpenMode(IndexWriterConfig.OpenMode.CREATE));
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(
this.taxoDir);
Document doc = new Document();
doc.add(new FacetField("Author", new String[] { "Bob" }));
doc.add(new FacetField("Publish Date", new String[] { "2010", "10",
"15" }));
indexWriter.addDocument(this.config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", new String[] { "Lisa" }));
doc.add(new FacetField("Publish Date", new String[] { "2010", "10",
"20" }));
indexWriter.addDocument(this.config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", new String[] { "Lisa" }));
doc.add(new FacetField("Publish Date",
new String[] { "2012", "1", "1" }));
indexWriter.addDocument(this.config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", new String[] { "Susan" }));
doc.add(new FacetField("Publish Date",
new String[] { "2012", "1", "7" }));
indexWriter.addDocument(this.config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", new String[] { "Frank" }));
doc.add(new FacetField("Publish Date",
new String[] { "1999", "5", "5" }));
indexWriter.addDocument(this.config.build(taxoWriter, doc));
indexWriter.close();
taxoWriter.close();
}
private List<FacetResult> facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(this.indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(this.taxoDir);
FacetsCollector fc = new FacetsCollector();
FacetsCollector.search(searcher, new MatchAllDocsQuery(), 10, fc);
List<FacetResult> results = new ArrayList<FacetResult>();
Facets facets = new FastTaxonomyFacetCounts(taxoReader, this.config, fc);
results.add(facets.getTopChildren(10, "Author", new String[0]));
results.add(facets.getTopChildren(10, "Publish Date", new String[0]));
indexReader.close();
taxoReader.close();
return results;
}
private List<FacetResult> facetsOnly() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(this.indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(this.taxoDir);
FacetsCollector fc = new FacetsCollector();
searcher.search(new MatchAllDocsQuery(), null, fc);
List<FacetResult> results = new ArrayList<FacetResult>();
Facets facets = new FastTaxonomyFacetCounts(taxoReader, this.config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
private FacetResult drillDown() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(this.indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(this.taxoDir);
DrillDownQuery q = new DrillDownQuery(this.config);
q.add("Publish Date", new String[] { "2010" });
FacetsCollector fc = new FacetsCollector();
FacetsCollector.search(searcher, q, 10, fc);
Facets facets = new FastTaxonomyFacetCounts(taxoReader, this.config, fc);
FacetResult result = facets.getTopChildren(10, "Author", new String[0]);
indexReader.close();
taxoReader.close();
return result;
}
private List<FacetResult> drillSideways() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(this.indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(this.taxoDir);
DrillDownQuery q = new DrillDownQuery(this.config);
q.add("Publish Date", new String[] { "2010" });
DrillSideways ds = new DrillSideways(searcher, this.config, taxoReader);
DrillSideways.DrillSidewaysResult result = ds.search(q, 10);
List<FacetResult> facets = result.facets.getAllDims(10);
indexReader.close();
taxoReader.close();
return facets;
}
public List<FacetResult> runFacetOnly() throws IOException {
index();
return facetsOnly();
}
public List<FacetResult> runSearch() throws IOException {
index();
return facetsWithSearch();
}
public FacetResult runDrillDown() throws IOException {
index();
return drillDown();
}
public List<FacetResult> runDrillSideways() throws IOException {
index();
return drillSideways();
}
public static void main(String[] args) throws Exception {
// one
System.out.println("Facet counting example:");
System.out.println("-----------------------");
SimpleFacetsExample example = new SimpleFacetsExample();
List<FacetResult> results1 = example.runFacetOnly();
System.out.println("Author: " + results1.get(0));
System.out.println("Publish Date: " + results1.get(1));
// two
System.out.println("Facet counting example (combined facets and search):");
System.out.println("-----------------------");
List<FacetResult> results = example.runSearch();
System.out.println("Author: " + results.get(0));
System.out.println("Publish Date: " + results.get(1));
// three
System.out.println("Facet drill-down example (Publish Date/2010):");
System.out.println("---------------------------------------------");
System.out.println("Author: " + example.runDrillDown());
// four
System.out.println("Facet drill-sideways example (Publish Date/2010):");
System.out.println("---------------------------------------------");
for (FacetResult result : example.runDrillSideways()) {
System.out.println(result);
}
}
}
标签:
原文地址:http://my.oschina.net/u/2273085/blog/403106