标签:
快速排序是排序算法之中的基本中的基本,虽然越来越多的接口函数将快速排序“完美的封装了起来”,比如C++中的qsort或者<algorithm>中的sort(与stable_sort相对应),但是深入思考,关于快速排序的优化你可曾想过?:-P
(一)经典快速排序
首先我们来看一下这个百度百科之中的快速排序版本
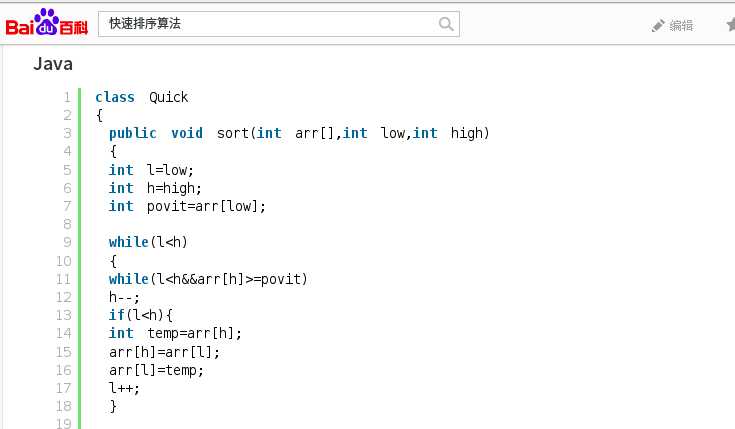
在上面这张图中,我们一边纠错一边复习下基本的快速排序,基本快速排序的函数体可以明确分为三个块:
1.调整块,根据对称轴pivot(一般选取第一个)从数组的前后两端向中间扫描,pivot作对称轴的同时也是一个哨兵,需要先把哨兵的值保存下来然后进行调换直到完成划分。每次循环注意到左端和右端只能有一次赋值的过程。
2.3.分别向前向后递归。
int tmpL=low;
int tmpR=high;
int tmpV=arr[low];
while(tmpL<tmpR){
while(tmpL<tmpR&&arr[tmpR]<=tmpV)tmpR--;
arr[tmpL]=arr[tmpR];
while(tmpL<tmpR&&arr[tmpL>=tmpV])tmpL++;
arr[tmpR]=arr[tmpL];
}
而在我给出的百度百科的算法中首先是把pivot耿直地写成了povit(可以忽略哈哈何厚铧),然后是一个很严肃的问题,关于代码的格式,要是百科编者不屑于写这种简单的代码的话可以不写嘛,或者再动一动写个花括号也就没事了,总而言之这段代码是不可能被新手/编译器看懂的!
在基本的几种算法之中,快速排序的运行速度是最快的,但是也是不稳定的,也许有的人会说堆排序运行速度理论上不比快速排序慢,但是其实不然,这和计算机部件中cache的命中率有关,堆排序需要在也许很广的地址空间里面不停地进行随机访问。
(二)三路快速排序
三路快速排序与经典快速排序不同之处在于划分部分,也就是函数的第一块。首先我们来看一下经典快速排序的划分过程的示意图:
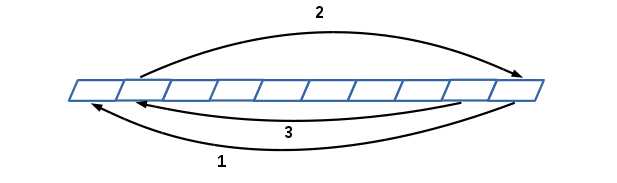
每一次循环的过程中会有前后两次扫描每次扫描后最多只能进行一次交换。再看三路快速排序的划分过程示意图:
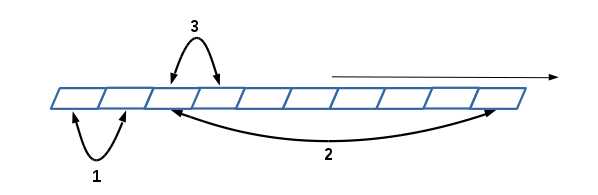
三路快速排序的过程实质上也是一次两端向扫描的过程,但这是一种稳定的排序方法,其核心思想依然是“DIVIDE & CONQUER”,但是和堆排序和选择排序一样整个排序的过程是个
"整理后区"的成长过程,每次的递归过程之中我们根据当前访问到的元素和对称轴的值的比对进行三路分支:
1.当当前元素小与对称轴时,将前端标志low和当前元素进行交换,两个索引值都自加1(前端标志之前的元素都是小于对称轴的元素)
2.当当前元素大于对称轴时,将当前元素和后端标志high进行交换,只将后端标志自减1(后端标志之后的元素都是大于对称轴的元素,当前索引不变以判断这个交换过来的值应划分在哪一部分)
3.当当前元素和对称轴相等的时候,当前索引自加1
代码如下:
1 template<typename T> ////Operator Overriding Concerned 2 void tri-qsort(int low,int high,vector<T> v){ 3 if(low>=high)return;////Recurrence Ending 4 else{ 5 int tmpL=low; 6 int tmpR=high; 7 int index=low+1; 8 int pivot=v[i] 9 while(index<=tmpR){ 10 if(index<pivot) swap(v[index++],v[tmpL++]); 11 else if(index>pivot) swap(v[index],v[tmpR--]); 12 else index++; 13 }////Partition Complete 14 tri-qsort(low,lt-1); 15 tri-qsort(gt+1,hight); 16 }
(三)双基准快速排序算法
这个双基准快速排序是我最推荐的,虽然双基准快速排序效率在理论上和其他版本的快速排序是基本一样的,但是在处理重复数据时双基准快速排序会有独特的优越性,但是时间复杂度的变化幅度会比较大。
双基准快速排序并不是简单意义上的将整个数据割为两端,交由两个不同的pivot去处理。双基准快速排序是在三路快速排序的基础之上进行的,如下图所示:
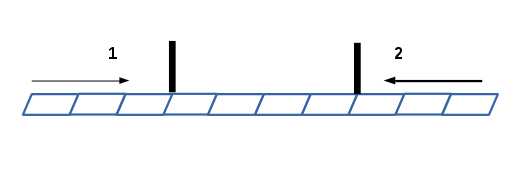
双基准排序要做的事情从宏观上来看有两个:(前提约束对称轴1小于对称轴2)
1.整理比对称轴1小的元素到前端标记之前
2.整理比对称轴2大的元素到后端标记之后
那么中间剩下的区域就是比对称轴1大而比对称轴2小的元素,所以我们要做的事情是每次递归之前改变这段数据的对称轴(最前最后两个元素),代码如下:
1 template<typename T> 2 void dual-qsort(int low,int high,vector<T> v){ 3 if(low>high)swap(low,high); 4 int pivotL=low; 5 int pivotR=high; 6 int tmpL=low; 7 int tmpR=high; 8 int index=low+1; 9 while(index<=tmpR){ 10 if(v[index]<pivotL)swap(v[index++],v[tmpL++]); 11 else if(v[index]>pivotR)swap(v[index],v[tmpR--]); 12 else index++; 13 } 14 swap(v[--tmpL],v[low]); 15 swap(v[++tmpR],v[high]); 16 dual-qsort(low,tmpL-1,v); 17 dual-qsort(tmpL+1,tmpR-1,v); 18 dual-qsort(tmpR+1,high,v); 19 }
<算法笔记>关于快速排序的算法优化排序(顺便给百度百科纠个错)
标签:
原文地址:http://www.cnblogs.com/guguli/p/4437248.html