我记得印象深刻的面试:面试者岁数大些,当时我面的时候也没出众,我准备给他一个一般的分,但他回去马上给我写了一篇长信,解释当时我问的问题,给出详细参考,我对他的回答非常佩服,至少态度很积极,也许是当场没有发挥好,我立马改变了印象,给他很高评价,但其中有个初级面试官居然给他1分,什么概念(if you hire him, I will go), 这样就把他平均分给拉下来,我觉得这样不公正,就在招聘会议上为他说话,最后他也拿到Offer顺利来到公司,事实证明这是一个挺优秀的技术人员。
董老师
因为自身对创业公司氛围的喜爱,决定去寻找其他的机会。决定离开LinkedIn觉得当时的工作被限制在广告领域,而个人对广告方面兴趣并不大。我认为广告行业是发展较成熟的行业,创新机会相对偏少。当时除了跳槽之外的另一选择是转换到其他的部门,但这样就是不够挑战,我一直希望自己Step out of your comfort zone,于是开始了自己的面试之旅,借面试这个渠道去了解LinkedIn外面的世界。
大数据相关技术,最紧密的就是云计算,主要是Amazon Web Service和Google Cloud Platform,在国内还有阿里云,金山云,百度云,腾讯云,小米云,360云,七牛。。每个里面都是大量技术文档和标准,从计算到存储,从数据库到消息,从监控到部署管理,从虚拟网络到CDN,把所有的一切用软件重新定义了一遍。
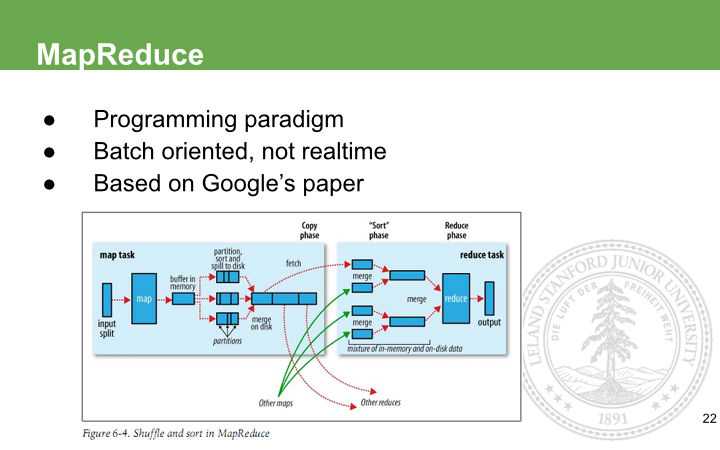
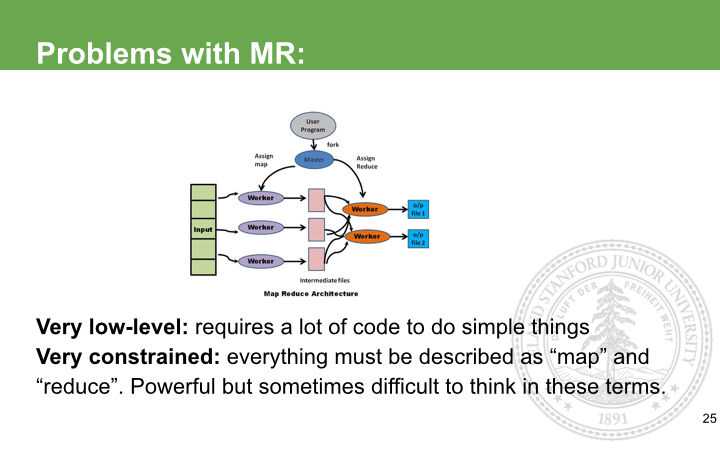
MapReduce,首先是个编程范式,它的思想是对批量处理的任务,分成两个阶段,所谓的Map阶段就是把数据生成key, value pair, 再排序,中间有一步叫shuffle,把同样的key运输到同一个reducer上面去,而在reducer上,因为同样key已经确保在同一个上,就直接可以做聚合,算出一些sum, 最后把结果输出到HDFS上。对应开发者来说,你需要做的就是编写Map和reduce函数,像中间的排序和shuffle网络传输,容错处理,框架已经帮你做好了。
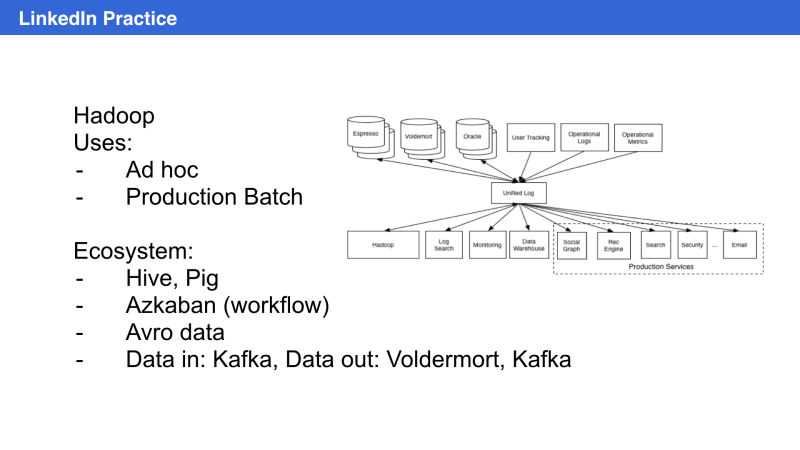
在Linkedin,有很多数据产品,比如People you may like, job you may be interested, 你的用户访问来源,甚至你的career path都可以挖掘出来。那么在Linkedin也是大量用到开源技术,我这里就说一个最成功的Kafka,它是一个分布式的消息队列,可以用在tracking,机器内部metrics,数据传输。