标签:
服务器开发中,为了充分利用多核甚至多个cpu,或者是简化逻辑编写的难度,会应用多进程(比如一个进程负责一种逻辑)多线程(将不同的用户分配到不同的进程)或者协程(不同的用户分配不同的协程,在需要时切换到其他协程),并且往往同时利用这些技术比如多进程多线程。
一个经典的服务器框架可以说如下的框架:
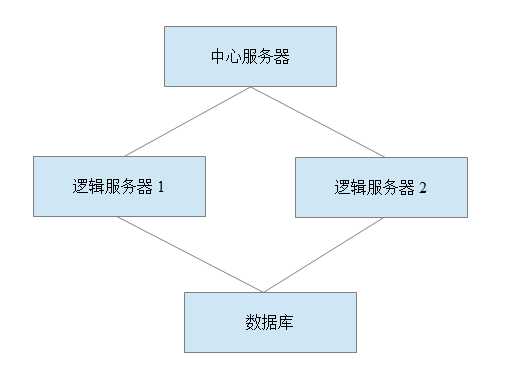
而这些服务器进程之间协同配合,为用户提供服务,其中中心服务器提供集群的调度工作,而逻辑服可以是逻辑服务器1提供登录服务、逻辑服务器2提供购买服务;也可以是2个服务器提供相同服务,然后视负载用户数将不同用户分配到不同服务器。
而这些服务器为了方便开发往往会采用到多线程的技术,一个经典的模式就是多个网络线程处理网络事件,然后一个线程处理用户逻辑;更进一步还可以是多线程处理用户逻辑,在多线程下比较麻烦的一点是不同线程访问同一个资源时需要加锁,不过众所周知锁上万恶之源,带来了难查的死锁和低下的问题。不过这些都有特殊的技巧可以解决,比如死锁,对同一线程重复获取同一把锁导致的死锁,我们可以采用可重入的计数锁,当一个线程获取了这把锁后,如果其他线程尝试lock这个mutex时会进入系统的调度队列,而本线程获取这把锁则会引用计数+1,本线程解锁则-1,如果引用计数为0则解锁,实现一个这样的锁,具体的算法的伪代码大致如下:
// int getthreadid() 获取线程ID // switchtothread() 切换线程 // wakeup(int id) 唤醒线程 // bool exchange(bool * m, bool v) 原子的修改一个类型为bool变量的值,并且返回原有的值 // bool load(bool * m) 原子的获取一个bool变量的值 struct mutex{ mutex(){ islock = false; lockid = -1; ref = 0; } bool islock; volatile int lockid; int ref; std::que<int> waitth; }; void lock(mutex & mu){ int id = getthreadid(); if (id != mu.lockid){ if (exchange(&mu.islock, true)){ waitth.push(id); switchtothread(); } else { lockid = id; } } else { ref++; } } void unlock(mutex & mu){ int id = getthreadid(); if (id == mu.lockid) { if (--ref == 0){ wakeup(mu.que.pop()); } } }
这样的一组伪代码,其中关于原子操作和线程调度的实现在windows大致如下:
int getthreadid(){ return (int)GetCurrentThread(); } int switchtothread(){ return SwitchToThread(); } int wakeup(int id){ return ResumeThread((HANDLE)id); }
boost中就提供了可重入的mutex: boost::recursive_mutex,windows中的Mutex和Critical Section就是可重入的,而linux的pthread_mutex_t就是不可重入的。
而因为同时访问2个资源导致的死锁,一个可以采用对资源的访问采用同一顺序访问,即可回避。
对于锁带来的性能问题,一个取巧的做法则每个用户数据独立,对公共资源的访问则采用一些高效的算法比如rcu、比如无锁算法
比如一个多读多写且读请求大于写请求的场合,我们就可以采用rcu算法。
rcu算法是在读的时候直接读数据,而写入则获取一份读拷贝在本地修改,并注册一个写入的回调函数,在读操作全部完成后调用回调函数完成写入。写操作之间则使用传统的同步机制。
而无锁算法,比较经典的则是一些无锁队列,比如ms-que,optimistic-que
ms-que的原理是利用原子操作,在写入的时候,先创建一个新的节点,完成数据的写入,然后在尾部利用cas操作,将尾节点的next指针指向新的节点,并将尾节点指向新节点。
在读的时候则是利用cas操作,将头节点指向头节点的next节点。
但是在利用这些,虽然充分利用了cpu的性能,但是编程也带来了极大的不便,比如多线程下不利于扩展以便充分利用集群提高性能的问题,多进程下则是复杂的异步调用。
一个理想的情况就是在跨进程通信的情况下,可以在发起一次远程的请求后,原地等待远端的相应,然后继续执行,比如在多线程的情况下,可以一个用户一个线程,然后在一次send之后,调用recv在请求返回后在继续执行,
但是多线程的调度会带来巨大的调度开销,这种情况下,更轻量级的协程成为了一个更好的选择,一个用户一个协程,然后在发起一次远程的请求后,切换到其他被唤醒的用户协程继续执行,在这个协程的请求返回后则唤醒这个协程继续执行逻辑代码。
协程带来的问题是协程是有用户控制调度的,所以用户需要自己实现调度算法,以及对应的锁算法(因为多协程虽然可以是单线程内执行,但是因为不同协程间的资源争用所以锁还是需要,而且是同步执行逻辑,如果使用spinlock则意味着整个系统阻塞,在异步网络id下即便是网络事件也不会被响应)。
协程的调度如下:
context::context* scheduling::onscheduling(){
context::context * _context = 0;
{
while (!time_wait_task_que.empty()){
uint64_t t = timer::clock();
time_wait_handle top = time_wait_task_que.top();
if(t > top.handle->waittime){
time_wait_task_que.pop();
uint32_t _state = top.handle->_state_queue.front();
top.handle->_state_queue.pop();
if (_state == time_running){
continue;
}
_context = top.handle->_context;
goto do_task;
}
}
}
{
while (!in_signal_context_list.empty()){
context::context * _context_ = in_signal_context_list.front();
in_signal_context_list.pop();
actuator * _actuator = context2actuator(_context_);
if (_actuator == 0){
continue;
}
task * _task = _actuator->current_task();
if (_task == 0){
continue;
}
if (_task->_state == time_wait_task){
_task->_state = running_task;
_task->_wait_context._state_queue.front() = time_running;
}
_context = _context_;
goto do_task;
}
}
{
if (!_fn_scheduling.empty()){
_context = _fn_scheduling();
goto do_task;
}
}
{
if (!low_priority_context_list.empty()){
_context = in_signal_context_list.front();
in_signal_context_list.pop();
goto do_task;
}
}
do_task:
{
if(_context == 0){
actuator * _actuator = _abstract_factory_actuator.create_product();
_context = _actuator->context();
_list_actuator.push_back(_actuator);
}
}
return _context;
}
锁算法原理recursive_mutex一样,当获取锁失败则将当前协程调度到其他用户协程,在解锁时唤醒等待协程
void mutex::lock(){
if (_mutex){
_mutex = true;
} else {
_service_handle->scheduler();
}
}
void mutex::unlock(){
if (_mutex){
if (!wait_context_list.empty()){
auto weak_up_ct = wait_context_list.back();
wait_context_list.pop_back();
_service_handle->wake_up_context(weak_up_ct);
}
_mutex = false;
}
}
标签:
原文地址:http://www.cnblogs.com/qianqians/p/4440507.html