标签:
作者:吴乐 山东师范大学
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
本实验目的:通过gdb在linux下对一个简单的命令行命令实现进程的过程进行跟踪,分析一般用户进程实现进程切换的过程,并进一步剖析进程调度的工作的原理。
一、实验过程
1、打开实验环境,并设置context_switch和pick_next_switch两个断点。
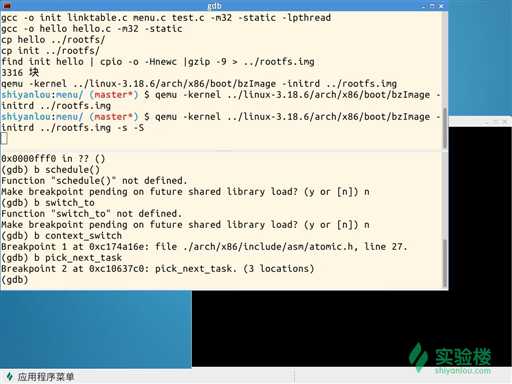
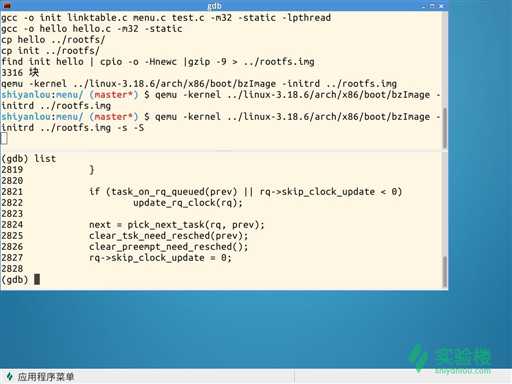
2、来到第二个断点处list(分析在第三部分)
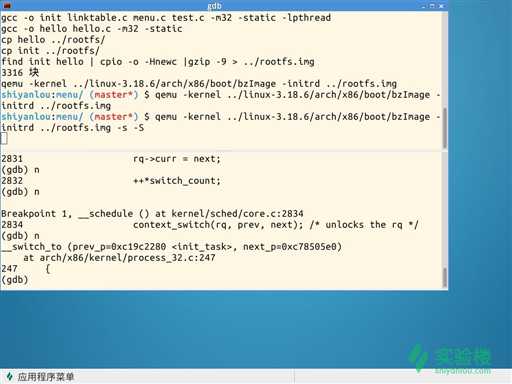
3、到第一个断点处,在这里进行进程的切换
4、找到schedule()函数的主体,可以按步入进入,后面的过程不再一一赘述。

二、schedule()部分关键代码分析
1、schedule()代码截取
prev->sched_class->put_prev_task(rq, prev);
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
sched_info_switch(prev, next);
rq->nr_switches++;
rq->curr = next;
++*switch_count;
context_switch(rq, prev, next); /* unlocks the rq */
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
spin_unlock_irq(&rq->lock);
其中不难发现第一句中的prev在之前被赋值为rq->curr,因此是当前运行队列正在运行的进程。从字面看是将当前进程放回队列。第二句是从队列中取出下一个可运行的进程,叫next。
下面是进程的上下文切换工作。首先判断prev和next是否是同一个进程,若是,则不必切换。否则统计信息,接着设置rq->curr为next,然后调用context_switch来进行实际的上下文切换。
理解进程的调度,核心是put_prev_task和pick_next_task;而理解进程的切换,核心是context_switch。下面就分两条线索,分别说明进程的切换和调度的流程。
2、下面来看pick_next_task函数主体。
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
class = sched_class_highest;
for ( ; ; ) { /* 对每一个调度类 */
/* 调用该调度类中的函数,找出下一个task */
p = class->pick_next_task(rq);
if (p)
return p;
/*
* Will never be NULL as the idle class always
* returns a non-NULL p:
*/
class = class->next; /* 访问下一个调度类 */
}
}
调用pick_next_task(),从运行队列中选择下一个要运行的进程。
3、接下来分析context_switch()实现的功能:
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
trace_sched_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (unlikely(!mm)) { /* 如果被切换进来的进程的mm为空 */
next->active_mm = oldmm; /* 将共享切换出去进程的active_mm */
atomic_inc(&oldmm->mm_count); /* 有一个进程共享,所有引用计数加一 */
/* 将per cpu变量cpu_tlbstate状态设为LAZY */
enter_lazy_tlb(oldmm, next);
} else /* 如果mm不为空,那么进行mm切换 */
switch_mm(oldmm, mm, next);
if (unlikely(!prev->mm)) { /* 如果切换出去的mm为空,从上面
可以看出本进程的active_mm为共享先前切换出去的进程
的active_mm,所有需要在这里置空 */
prev->active_mm = NULL;
rq->prev_mm = oldmm; /* 更新rq的前一个mm结构 */
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it‘s an obvious special-case), so we
* do an early lockdep release here:
*/
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
/* 这里切换寄存器状态和栈 */
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the ‘rq‘ on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}
schedule的核心函数,实现了切换到新的内存页、寄存器状态和栈,以及切换后的清理工作。其中调用switch_to()切换进程的寄存器状态和栈,我们重点看这一部分。
4、switch_to进行内核堆栈和CPU环境切换操作:
/*
* Saving eflags is important. It switches not only IOPL between tasks,
* it also protects other tasks from NT leaking through sysenter etc.
*/
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
/*将next_ip入栈,下面用jmp跳转,这样
返回到标号1时就切换过来了*/
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
/*切换到新进程的第一条指令*/
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
可见其步骤可分为两步:
①切换内核堆栈
这个宏首先在保存了ebx,ecx,edx,esi,edi,flags在当前内核堆栈上,然后进行关键的堆栈切换:
pushl %ebp movl %esp, %[prev_sp] mvol %[prev_sp], %esp
首先将栈帧ebp压栈,然后从prev->thread.sp中取出上个进程在上一次切换时的栈顶,放到esp中。此句过后,内核态的堆栈已经切换到了下一个进程的内核堆栈。由前面介绍的current_thread_info的特点,此时调用此函数,将得到next的thread_info。
接着开始切换控制流程:
movl $1f, %[prev_ip] pushl %[next_ip] jmp __switch_to 1: popl %ebp
首先将标号1,即该段最后一句的地址放入prev->thread.ip。可见下次prev运行时,将从pop %ebp开始。 然后,将next->thread.ip压栈,并跳转到__switch_to执行。
__switch_to返回时,会从堆栈弹出一项作为返回地址,由于调用__switch_to时不是通过call指令,而是手工压栈加跳转,所以不会返回到“这里”的标号1处,而是返回到next->thread.ip处。如果next进程不是新创建出来的,那么原来也是通过switch_to切换走的,则断点必定是“那里”的标号1,且此时next的内核堆栈上保存有那一次的ebp和flags,以及ebx等。
因此通过这一次函数调用,内核的控制流程也被成功转移到next,在next上次切换的标号1处,对上次保存的ebp和flags等内容进行恢复,这就完成了整个切换过程。
三、总结与反思
一次一般的进程切换过程,其中必须完成的关键操作是:切换地址空间、切换内核堆栈、切换内核控制流程,加上一些必要的寄存器保存和恢复。这里,除去地址空间的切换,其他操作要强调“内核”一词。这是因为,这些操作并非针对用户代码,切换完成后,也没有立即跑到next的用户空间中执行。用户上下文的保存和恢复是通过中断和异常机制,在内核态和用户态相互切换时才发生的。schedule()是内核和其他部分用于调用进程调度器的入口,选择哪个进程可以运行,何时将其投入运行。
标签:
原文地址:http://www.cnblogs.com/wule/p/4448456.html