标签:
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html
网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html
网站日志分析项目案例(三)统计分析:当前页面

为了能够借助Hive进行统计分析,首先我们需要将清洗后的数据存入Hive中,那么我们需要先建立一张表。这里我们选择分区表,以日期作为分区的指标,建表语句如下:(这里关键之处就在于确定映射的HDFS位置,我这里是/project/techbbs/cleaned即清洗后的数据存放的位置)
hive>CREATE EXTERNAL TABLE techbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ LOCATION ‘/project/techbbs/cleaned‘;
建立了分区表之后,就需要增加一个分区,增加分区的语句如下:(这里主要针对20150425这一天的日志进行分区)
hive>ALTER TABLE techbbs ADD PARTITION(logdate=‘2015_04_25‘) LOCATION ‘/project/techbbs/cleaned/2015_04_25‘;
有关分区表的详细介绍此处不再赘述,如有不明白之处可以参考本笔记系列之17-Hive框架学习一文。
(1)关键指标之一:PV量
页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次。这里,我们只需要统计日志中的记录个数即可,HQL代码如下:
hive>CREATE TABLE techbbs_pv_2015_04_25 AS SELECT COUNT(1) AS PV FROM techbbs WHERE logdate=‘2015_04_25‘;

(2)关键指标之二:注册用户数
该论坛的用户注册页面为member.php,而当用户点击注册时请求的又是member.php?mod=register的url。因此,这里我们只需要统计出日志中访问的URL是member.php?mod=register的即可,HQL代码如下:
hive>CREATE TABLE techbbs_reguser_2015_04_25 AS SELECT COUNT(1) AS REGUSER FROM techbbs WHERE logdate=‘2015_04_25‘ AND INSTR(url,‘member.php?mod=register‘)>0;

(3)关键指标之三:独立IP数
一天之内,访问网站的不同独立 IP 个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。因此,这里我们只需要统计日志中处理的独立IP数即可,在SQL中我们可以通过DISTINCT关键字,在HQL中也是通过这个关键字:
hive>CREATE TABLE techbbs_ip_2015_04_25 AS SELECT COUNT(DISTINCT ip) AS IP FROM techbbs WHERE logdate=‘2015_04_25‘;

(4)关键指标之四:跳出用户数
只浏览了一个页面便离开了网站的访问次数,即只浏览了一个页面便不再访问的访问次数。这里,我们可以通过用户的IP进行分组,如果分组后的记录数只有一条,那么即为跳出用户。将这些用户的数量相加,就得出了跳出用户数,HQL代码如下:
hive>CREATE TABLE techbbs_jumper_2015_04_25 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM techbbs WHERE logdate=‘2015_04_25‘ GROUP BY ip HAVING times=1) e;

PS:跳出率是指只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数 / 全部的访问次数汇总。这里,我们可以将这里得出的跳出用户数/PV数即可得到跳出率。
(5)将所有关键指标放入一张汇总表中以便于通过Sqoop导出到MySQL
为了方便通过Sqoop统一导出到MySQL,这里我们借助一张汇总表将刚刚统计到的结果整合起来,通过表连接结合,HQL代码如下:
hive>CREATE TABLE techbbs_2015_04_25 AS SELECT ‘2015_04_25‘, a.pv, b.reguser, c.ip, d.jumper FROM techbbs_pv_2015_04_25 a JOIN techbbs_reguser_2015_04_25 b ON 1=1 JOIN techbbs_ip_2015_04_25 c ON 1=1 JOIN techbbs_jumper_2015_04_25 d ON 1=1;

(1)Step1:创建一个新数据库:techbbs
mysql> create database techbbs;
Query OK, 1 row affected (0.00 sec)
(2)Step2:创建一张新数据表:techbbs_logs_stat
mysql> create table techbbs_logs_stat(
-> logdate varchar(10) primary key,
-> pv int,
-> reguser int,
-> ip int,
-> jumper int);
Query OK, 0 rows affected (0.01 sec)
(1)Step1:编写导出命令
sqoop export --connect jdbc:mysql://hadoop-master:3306/techbbs --username root --password admin --table techbbs_logs_stat --fields-terminated-by ‘\001‘ --export-dir ‘/hive/techbbs_2015_04_25‘
这里的--export-dir是指定的hive目录下的汇总表所在位置,我这里是/hive/techbbs_2015_04_25。
(2)Step2:查看导出结果
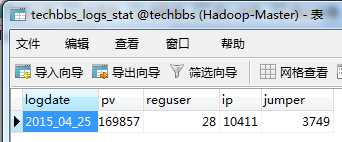
刚刚我们已经借助Hive进行了关键指标的统计分析,并且借助Sqoop导出到了MySQL,后续可以借助JSP或者ASP.NET开发指标浏览界面供决策者进行浏览分析。但是刚刚这些操作都是我们自己手工操作的,我们需要实现自动化的统计分析并导出,于是我们改写前一篇中提到的定时任务脚本文件。
重写techbbs_core.sh文件,内容如下,step4~step8为新增内容:
#!/bin/sh ...... #step4.alter hive table and then add partition hive -e "ALTER TABLE techbbs ADD PARTITION(logdate=‘${yesterday}‘) LOCATION ‘/project/techbbs/cleaned/${yesterday}‘;" #step5.create hive table everyday hive -e "CREATE TABLE hmbbs_pv_${yesterday} AS SELECT COUNT(1) AS PV FROM hmbbs WHERE logdate=‘${yesterday}‘;" hive -e "CREATE TABLE hmbbs_reguser_${yesterday} AS SELECT COUNT(1) AS REGUSER FROM hmbbs WHERE logdate=‘${yesterday}‘ AND INSTR(url,‘member.php?mod=register‘)>0;" hive -e "CREATE TABLE hmbbs_ip_${yesterday} AS SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate=‘${yesterday}‘;" hive -e "CREATE TABLE hmbbs_jumper_${yesterday} AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate=‘${yesterday}‘ GROUP BY ip HAVING times=1) e;" hive -e "CREATE TABLE hmbbs_${yesterday} AS SELECT ‘${yesterday}‘, a.pv, b.reguser, c.ip, d.jumper FROM hmbbs_pv_${yesterday} a JOIN hmbbs_reguser_${yesterday} b ON 1=1 JOIN hmbbs_ip_${yesterday} c ON 1=1 JOIN hmbbs_jumper_${yesterday} d ON 1=1;" #step6.delete hive tables hive -e "drop table hmbbs_pv_${yesterday};" hive -e "drop table hmbbs_reguser_${yesterday};" hive -e "drop table hmbbs_ip_${yesterday};" hive -e "drop table hmbbs_jumper_${yesterday};" #step7.export to mysql sqoop export --connect jdbc:mysql://hadoop-master:3306/techbbs --username root --password admin --table techbbs_logs_stat --fields-terminated-by ‘\001‘ --export-dir ‘/hive/hmbbs_${yesterday}‘ #step8.delete hive table hive -e "drop table techbbs_${yesterday};"
(1)改写techbbs_core.sh脚本文件:
#!/bin/sh #step1.get yesterday format string #yesterday=`date --date=‘1 days ago‘ +%Y_%m_%d` yesterday=$1
这里将日期字符串作为参数传入,将该步骤转移到了其他脚本文件中;
(2)新增techbbs_daily.sh脚本文件:
#!/bin/sh yesterday=`date --date=‘1 days ago‘ +%Y_%m_%d` hmbbs_core.sh $yesterday
这里获取日期并作为参数传递给techbbs_core.sh文件;
(3)改写crontab定时任务配置:crontab -e
* 1 * * * /usr/local/files/apache_logs/techbbs_daily.sh
这里每天凌晨1点自动执行的就变为techbbs_daily.sh脚本文件了;从此,我们只需定期查看mysql数据库中的汇总结果表进行浏览即可;
当一个网站已经生成了很多天的日志,而我们的日志分析系统却一直没上线,一直等到了某天才上线。这时,我们需要写一个初始化脚本任务,来对之前的每天的日志进行统计分析与导出结果。这里,我们新增一个techbbs_init.sh脚本文件,内容如下:
#!/bin/sh #step1.create external table in hive hive -e "CREATE EXTERNAL TABLE techbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ LOCATION ‘/project/techbbs/cleaned‘;" #step2.compute the days between start date and end date s1=`date --date="$1" +%s` s2=`date +%s` s3=$((($s2-$s1)/3600/24)) #step3.excute techbbs_core.sh $3 times for ((i=$s3; i>0; i--)) do logdate=`date --date="$i days ago" +%Y_%m_%d` techbbs_core.sh $logdate done
通过三部分的介绍,该网站的日志分析工作基本完成,当然还有很多没有完成的东西,但是大体上的思路已经明了,后续的工作只需要在此基础上稍加分析即可完成。当然,我们还可以通过JSP或ASP.NET读取MySQL或HBase中的分析结果表来开发关键指标查询系统,供网站运营决策者进行查看和分析。
Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
标签:
原文地址:http://www.cnblogs.com/edisonchou/p/4464349.html