标签:
我使用3台Centos虚拟机搭建了一个Hadoop2.6的集群。希望在windows7上面使用IDEA开发mapreduce程序,然后提交的远程的Hadoop集群上执行。经过不懈的google终于搞定
1:org.apache.hadoop.util.Shell$ExitCodeException: /bin/bash: line 0: fg: no job control
2:Stack trace: ExitCodeException exitCode=1:
3:Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
4:Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class WordCount$Map not found
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.remote.os</name> <value>Linux</value> </property> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /opt/hadoop-2.6.0/etc/hadoop, /opt/hadoop-2.6.0/share/hadoop/common/*, /opt/hadoop-2.6.0/share/hadoop/common/lib/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/lib/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/lib/*, /opt/hadoop-2.6.0/share/hadoop/yarn/*, /opt/hadoop-2.6.0/share/hadoop/yarn/lib/* </value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.application.classpath</name> <value> /opt/hadoop-2.6.0/etc/hadoop, /opt/hadoop-2.6.0/share/hadoop/common/*, /opt/hadoop-2.6.0/share/hadoop/common/lib/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/*, /opt/hadoop-2.6.0/share/hadoop/hdfs/lib/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/*, /opt/hadoop-2.6.0/share/hadoop/mapreduce/lib/*, /opt/hadoop-2.6.0/share/hadoop/yarn/*, /opt/hadoop-2.6.0/share/hadoop/yarn/lib/* </value> </property> </configuration>
package com.gaoxing.hadoop; import java.io.IOException; import java.security.PrivilegedExceptionAction; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.security.UserGroupInformation; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { //继承mapper接口,设置map的输入类型为<Object,Text> //输出类型为<Text,IntWritable> public static class Map extends Mapper<Object,Text,Text,IntWritable>{ //one表示单词出现一次 private static IntWritable one = new IntWritable(1); //word存储切下的单词 private Text word = new Text(); public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ //对输入的行切词 StringTokenizer st = new StringTokenizer(value.toString()); while(st.hasMoreTokens()){ word.set(st.nextToken());//切下的单词存入word context.write(word, one); } } } //继承reducer接口,设置reduce的输入类型<Text,IntWritable> //输出类型为<Text,IntWritable> public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{ //result记录单词的频数 private static IntWritable result = new IntWritable(); public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int sum = 0; //对获取的<key,value-list>计算value的和 for(IntWritable val:values){ sum += val.get(); } //将频数设置到result result.set(sum); //收集结果 context.write(key, result); } } /** * @param args */ public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); // conf.set("mapred.remote.os","Linux"); // conf.set("yarn.resourcemanager.address","master:8032"); // conf.set("mapreduce.framework.name","yarn"); conf.set("mapred.jar","D:\\IdeaProjects\\hadooplearn\\out\\artifacts\\hadoo.jar"); //conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); job.setJobName("test"); //配置作业各个类 job.setJarByClass(WordCount.class); job.setMapperClass(Map.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://master:9000/tmp/hbase-env.sh")); FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/tmp/out11")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
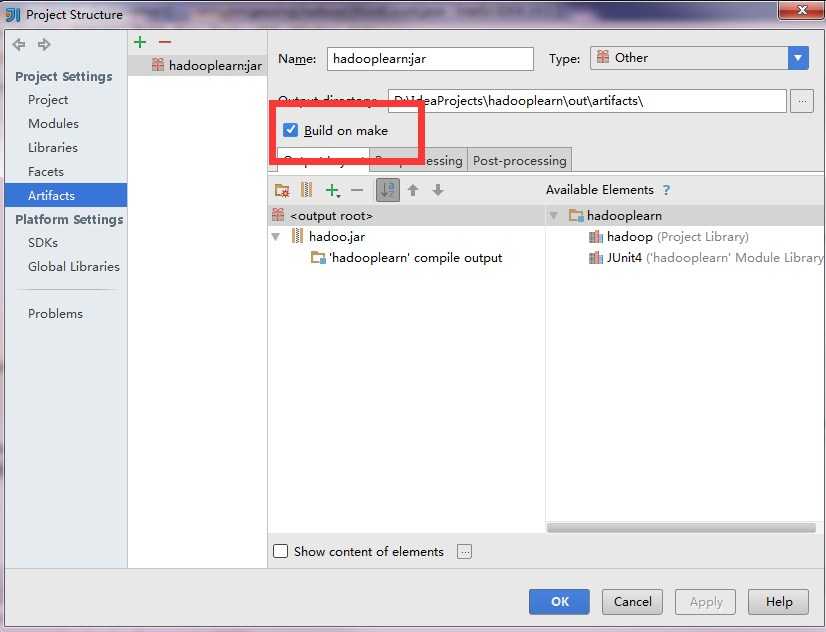
在windows远程提交任务给Hadoop集群(Hadoop 2.6)
标签:
原文地址:http://www.cnblogs.com/gaoxing/p/4466924.html