标签:
目录
1. 简介 2. 进程虚拟地址空间 3. 内存映射的原理 4. 数据结构 5. 对区域的操作 6. 地址空间 7. 内存映射 8. 反向映射 9.堆的管理 10. 缺页异常的处理 11. 用户空间缺页异常的校正 12. 内核缺页异常 13. 在内核和用户空间之间复制数据
1. 简介
用户层进程的虚拟地址空间是Linux的一个重要抽象,它向每个运行进程提供了同样的系统视图,这使得多个进程可以同时运行,而不会干扰到其他进程内存中的内容,此外,它容许使用各种高级的程序设计技术,如内存映射,学习虚拟内存,同样需要考察可用物理内存中的页帧与所有的进程虚拟地址空间中的页之间的关联: 逆向映射(reverse mapping)技术有助于从虚拟内存页中跟踪到对应的物理内存页,而缺页处理(page fault handling)则允许从块设备按需读取数据填充虚拟地址空间(本质上是从块设备中读取数据物理内存中,并重新建立物理内存到虚拟内存的映射关系)
相对于物理内存的组织,或者内核的虚拟地址空间的管理(内核的虚拟内存是直接线性物理内存映射的),虚拟内存的管理更加复杂
1. 每个应用程序都有自身的地址空间,与所有其他应用程序分隔开 2. 通常在巨大的线性地址空间中,只有很少的段可用于各个用户空间进程,这些段彼此之间有一定的距离,内核需要一些数据结构,来有效地管理这些"随机"分布的段 3. 地址空间只有极小一部分与物理内存页直接关联(建立页表映射),不经常使用的部分,则仅当必要时与页帧关联(基于缺页中断机制的内存换入换出机制) 4. 内核信任自身,但无法信任用户进程,因此,各个操作用户地址空间的操作都伴随有各种检查,以确保程序的权限不会超出应用的限制,进而危及系统的稳定性和安全性 5. fork-exec模型在UNIX操作系统下用于产生新进程,内核需要借助一些技巧,来尽可能高效地管理用户地址空间
0x1: MMU(memory management unit)
需要明白的是,我们接下来讨论的内容都似乎基于系统有一个内存管理单元MMU,该单元支持使用虚拟内存,大多数"正常"的处理器都包含这个组件
内存管理单元(memory management unit MMU),有时称作分页内存管理单元(paged memory management unit PMMU)。它是一种负责处理中央处理器(CPU)的内存访问请求的计算机硬件。它的功能包括
1. 虚拟地址到物理地址的转换(即虚拟内存管理) 2. 内存保护 3. 中央处理器高速缓存的控制 4. 在较为简单的计算机体系结构中,负责总线的仲裁以及存储体切换(bank switching,尤其是在8位的系统上)
现代的内存管理单元是以页的方式,分区虚拟地址空间(处理器使用的地址范围)的;页的大小是2的n次方,通常为几KB。地址尾部的n位(页大小的2的次方数)作为页内的偏移量保持不变。其余的地址位(address)为(虚拟)页号。内存管理单元通常借助一种叫做转译旁观缓冲器(Translation Lookaside Buffer TLB)的相联高速缓存(associative cache)来将虚拟页号转换为物理页号。当后备缓冲器中没有转换记录时,则使用一种较慢的机制,其中包括专用硬件(hardware-specific)的数据结构(Data structure)或软件辅助手段
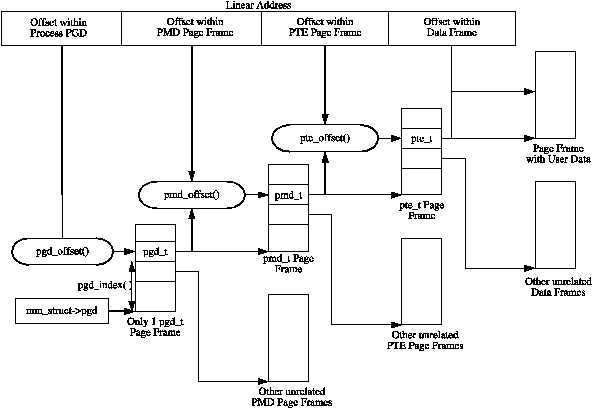
Each process a pointer (mm_struct→pgd) to its own Page Global Directory (PGD) which is a physical page frame. This frame contains an array of type pgd_t which is an architecture specific type defined in <asm/page.h>. The page tables are loaded differently depending on the architecture. On the x86, the process page table is loaded by copying mm_struct→pgd into the cr3 register which has the side effect of flushing the TLB. In fact this is how the function __flush_tlb() is implemented in the architecture dependent code.
Each active entry in the PGD table points to a page frame containing an array of Page Middle Directory (PMD) entries of type pmd_t which in turn points to page frames containing Page Table Entries (PTE) of type pte_t, which finally points to page frames containing the actual user data. In the event the page has been swapped out to backing storage, the swap entry is stored in the PTE and used by do_swap_page() during page fault to find the swap entry containing the page data. The page table layout is illustrated in Figure below
现代操作系统普遍采用多级(四级)页表的方式来组织虚拟内存和物理内存的映射关系,从虚拟地址内存到物理地址内存的翻译就是在进行多级页表的寻址过程
0x2: Describing a Page Table Entry
1. _PAGE_PRESENT: Page is resident in memory and not swapped out,该页是否应被高速缓冲的信息 2. _PAGE_PROTNONE: Page is resident but not accessable 3. _PAGE_RW: Set if the page may be written to 4. _PAGE_USER: Set if the page is accessible from user space,"特权位": 哪种进程可以读写该页的信息,例如用户模式(user mode)进程、还是特权模式(supervisor mode)进程 5. _PAGE_DIRTY: Set if the page is written to,"脏位"(页面重写标志位)(dirty bit): 表示该页是否被写过 6. _PAGE_ACCESSED: Set if the page is accessed,"访问位"(accessed bit): 表示该页最后使用于何时,以便于最近最少使用页面置换算法(least recently used page replacement algorithm)的实现
有时,TLB或PTE会禁止对虚拟页的访问,这可能是因为没有物理随机存取存储器(random access memory)与虚拟页相关联。如果是这种情况,MMU将向CPU发出页错误(page fault)的信号。操作系统将进行处理,也许会尝试寻找RAM的空白帧,同时创建一个新的PTE将之映射到所请求的虚拟地址。如果没有空闲的RAM,可能必须关闭一个已经存在的页面,使用一些替换算法,将之保存到磁盘中(这被称之为页面调度(paging))
Relevant Link:
http://zh.wikipedia.org/wiki/%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%E5%8D%95%E5%85%83 https://www.kernel.org/doc/gorman/html/understand/understand006.html
2. 进程虚拟地址空间
各个进程的虚拟地址空间范围为: [0 ~ TASK_SIZE - 1],再往"上"(栈高地址空间)是内核地址空间,在IA-32系统上地址空间的范围为: [0 ~ 2^32] = 4GB,总的地址空间通常按3:1划分
与系统完整性相关的非常重要的一个方面是,用户程序只能访问整个地址空间的下半部分,不能访问内核部分,如果没有预先达成"协议(即IPC机制)",用户进程也不能操作另一个进程的地址空间,因为不同进程的地址空间互相是不可见的
值得注意的是,无论当前哪个用户进程处于活动状态,虚拟地址空间内核部分的内容总是同样的,实现这个功能的技术取决于具体的硬件
1. 通过操作各个用户进程的页表,使得虚拟地址空间的上半部分(内核高地址段)看上去总是相同的 2. 指示处理器为内核提供一个独立的地址空间,映射在各个用户地址空间之上
虚拟地址空间由许多不同长度的段组成,用于不同的目的,必须分别处理,例如在大多数情况下,不允许修改.text段,但必须可以执行其中内容。另一方面,必须可以修改映射到地址空间中的文本文件内容,而不能允许执行其内容,文件内容只是数据,而并非机器代码
从这里我们也可以看到操作提供的安全机制本质上是一个自上而下的过程,每一级都对上游负责,并对下游提出要求
1. 进程ELF的节区中的属性标志指明了当前节区(段)具有哪些属性(R/W/RW/E),这需要操作系统在内存的PTE页表项中提供支持 2. PTE中的_PAGE_RW位表示该页具有哪些读写属性,而需要禁止某些内存页的二进制字节被CPU执行,需要底层CPU提供硬件支持 3. CPU的NX bit位提供了硬件级的禁止内存页数据执行支持,这也是DEP技术的基础
0x1: 进程地址空间的布局
虚拟地址空间中包含了若干区域,其分布方式是特定于体系结构的,但所有方法都有下列共同成分
1. 当前运行代码的二进制代码,该代码通常称之为.text,所处的虚拟内存区域称之为.text段 2. 程序使用的动态库的代码 3. 存储全局变量和动态产生的数据的堆 4. 用于保存局部变量和实现函数/过程调用的栈 5. 环境变量和命令行参数的段 6. 将文件内容映射到虚拟地址空间中的内存映射
我们知道,系统中的各个进程都具有一个struct mm_struct的实例,关于数据结构的相关知识,参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //0x1: struct mm_struct
各个体系结构可以通过几个配置选项影响虚拟地址空间的布局
1. 如果体系结构想要在不同mmap区域布局之间作出选择,则需要设置HAVE_ARCH_PICK_MMAP_LAYOUT,并提供arch_pick_mmap_layout函数 2. 在创建新的内存映射时,除非用户指定了具体的地址,否则内核需要找到一个适当的位置,如果体系结构自身想要选择合适的位置,则必须设置预处理器符号HAVE_ARCH_UNMAPPED_AREA,并相应地定义arch_get_unmapped_area函数 3. 在寻找新的内存映射低端内存位置时,通常从较低的内存位置开始,逐渐向较高的内存地址搜索,内核提供了默认的函数arch_get_unmapped_area_topdown用于搜索,但如果某个体系结构想要提供专门的实现,则需要设置预处理符号HAVE_ARCH_UNMAPPED_AREA 4. 通常,栈自顶向下增长,具有不同处理方式的体系结构需要设置配置选项CONFIG_STACK_GROWSUP
最后,我们需要考虑进程标志PF_RANDOMIZE,如果设置了该标志,则内核不会为栈和内存映射的起点选择固定位置,而是在每次新进程启动时随机改变这些值的设置,这引入了一些复杂性,例如使得缓冲区溢出攻击更加困难,如果攻击者无法依靠固定地址找到栈,那么想要构建恶意代码,通过缓冲区溢出获得栈内存区域的访问权从而恶意操纵栈的内容,将会困难得多
1. .text段
.text段如何映射到虚拟地址空间中由ELF标准确定,每个体系结构都指定了一个特定的起始地址
1. IA-32: 起始于0x08048000 //在text段的起始地址与最低的可用地址之间大约有128MB的间距,用于捕获NULL指针,其他体系结构也有类似的缺口 2. UltraSparc: 起始于0x100000000 3. AMD64: 0x0000000000400000
2. 堆
堆紧接着text段开始,向上增长
3. MMAP
用于内存映射的区域起始于mm_struct->mmap_base,通常设置为TASK_UNMAPPED_BASE,每个体系结构都需要定义,在几乎所有的情况下,其值都是TASK_SIZE / 3,值得注意的是,内核的默认配置,mmap区域的起始点不是随机的,即ASLR不是默认开启的,需要特定的内核配置
4. 栈
栈起始于STACK_TOP(栈是从高地址向低地址生长的,这里的起始指的最高的地址位置),如果设置了PF_RANDOMIZE,则起始点会减少一个小的随机量,每个体系结构都必须定义STACK_TOP,大多数都设置为TASK_SIZE,即用户地址空间中最高可用地址。进程的参数列表和环境变量都是栈的初始数据(即位于栈的最高地址区域)

如果计算机提供了巨大的虚拟地址空间,那么使用上述的地址空间布局会工作地非常好,但在32位计算机上可能会出现问题。考虑IA-32的情况,虚拟地址空间从0~0xC0000000,每个用户进程有3GB可用,TASK_UMMAPPED_BASE起始于0x4000000,即1GB处( TASK_UMMAPPED_BASE = TASK_SIZE / 3),这意味着堆只有1GB空间可供使用,继续增长会进入到mmap区域,这显然不可接受
这里的关键问题在于: 内存映射区域位于虚拟地址空间的中间
因此,在内核版本2.6.7开发期间为IA-32计算机引入了一个新的虚拟地址空间布局

新的布局的思想在于使用固定值限制栈的最大长度(简单来说是将原本栈和mmap共享增长的空间,转移到了mmap和堆共享增长空间)。由于栈是有界的,因此安置内存映射的区域可以在栈末端的下方立即开始,与经典方法相反,mmap区域是自顶向下扩展,由于堆仍然位于虚拟地址空间中较低的区域并向上增长,因此mmap区域和堆可以相对扩展,直至耗尽虚拟地址空间中剩余的区域。
为了确保栈与mmap区域不发生冲突,两者之间设置了一个安全隙
0x2: 建立布局
在do_execve()函数的准备阶段,已经从可执行文件头部读入128字节存放在bprm的缓冲区中,而且运行所需的参数和环境变量也已收集在bprm中
search_binary_handler()函数就是逐个扫描formats队列,直到找到一个匹配的可执行文件格式,运行的事就交给它
1. 如果在这个队列中没有找到相应的可执行文件格式,就要根据文件头部的信息来查找是否有为此种格式设计的可动态安装的模块 2. 如果找到对应的可执行文件格式,就把这个模块安装进内核,并挂入formats队列,然后再重新扫描
在linux_binfmt数据结构中,有三个函数指针
1. load_binary load_binary就是具体的ELF程序装载程序,不同的可执行文件其装载函数也不同 1) a.out格式的装载函数为: load_aout_binary() 2) elf的装载函数为: load_elf_binary() 3) .. 2. load_shlib 3. core_dump
对于ELF文件对应的linux_binfmt结构体来说,结构体如下
static struct linux_binfmt elf_format = { .module = THIS_MODULE, .load_binary = load_elf_binary, .load_shlib = load_elf_library, .core_dump = elf_core_dump, .min_coredump = ELF_EXEC_PAGESIZE, .hasvdso = 1 };
在使用load_elf_binary装载一个ELF二进制文件时,将创建进程的地址空间

如果进程在ELF文件中明确指出需要ASLR机制(即PF_RANDOMIZE被置位)、且全局变量randomize_va_space设置为1,则启动地址空间随机化机制。此外,用户可以通过/proc/sys/kernel/randomize_va_space停用内核对该特性的支持
static int load_elf_binary(struct linux_binprm *bprm, struct pt_regs *regs) { .. if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space) current->flags |= PF_RANDOMIZE; setup_new_exec(bprm); /* Do this so that we can load the interpreter, if need be. We will change some of these later */ current->mm->free_area_cache = current->mm->mmap_base; current->mm->cached_hole_size = 0; retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), executable_stack); if (retval < 0) { send_sig(SIGKILL, current, 0); goto out_free_dentry; } current->mm->start_stack = bprm->p; .. }
这再次说明了ASLR这种安全机制是需要操作系统内核支持,并且编译器需要显示指出需要开启指定功能的互相配合的这种模式
static int load_elf_binary(struct linux_binprm *bprm, struct pt_regs *regs) { .. /* Flush all traces of the currently running executable */ retval = flush_old_exec(bprm); if (retval) goto out_free_dentry; } int flush_old_exec(struct linux_binprm * bprm) { .. retval = exec_mmap(bprm->mm); if (retval) goto out; .. } EXPORT_SYMBOL(flush_old_exec); static int exec_mmap(struct mm_struct *mm) { .. arch_pick_mmap_layout(mm); .. }
选择布局的工作由arch_pick_mmap_layout完成,如果对应的体系结构没有提供一个具体的函数,则使用内核的默认例程,我们额外关注一下IA-32如何在经典布局和新的布局之间选择
\linux-2.6.32.63\arch\x86\mm\mmap.c
/* 如果设置了personality比特位,或栈的增长不受限制,则回退到标准布局 */ static int mmap_is_legacy(void) { if (current->personality & ADDR_COMPAT_LAYOUT) return 1; if (current->signal->rlim[RLIMIT_STACK].rlim_cur == RLIM_INFINITY) return 1; //否则,使用新的布局方式 return sysctl_legacy_va_layout; } /* * This function, called very early during the creation of a new * process VM image, sets up which VM layout function to use: */ void arch_pick_mmap_layout(struct mm_struct *mm) { if (mmap_is_legacy()) { mm->mmap_base = mmap_legacy_base(); mm->get_unmapped_area = arch_get_unmapped_area; mm->unmap_area = arch_unmap_area; } else { mm->mmap_base = mmap_base(); mm->get_unmapped_area = arch_get_unmapped_area_topdown; mm->unmap_area = arch_unmap_area_topdown; } }
在经典的配置下,mmap区域的起始点是TASK_UNMAPPED_BASE(0x4000000),而标准函数arch_get_unmapped_area用于自下而上地创建新的映射
在使用新布局时,内存映射自顶向下下增长,标准函数arch_get_unmapped_area_topdown负责该工作,我们着重关注一下如何选择内存映射的基地址
\linux-2.6.32.63\arch\x86\mm\mmap.c
static unsigned long mmap_base(void) { unsigned long gap = current->signal->rlim[RLIMIT_STACK].rlim_cur; /* 在新的进程布局中,可以根据栈的最大长度,来计算栈最低的可能位置,用作mmap区域的起始点,但内核会确保栈至少可以跨越128MB的空间(即栈最小要有128MB的空间) 另外,如果指定的栈界限非常巨大,那么内核会保证至少有一小部分地址空间不被栈占据 */ if (gap < MIN_GAP) gap = MIN_GAP; else if (gap > MAX_GAP) gap = MAX_GAP; //如果要求使用地址空间随机化机制,则栈的 起始位置会减去一个随机的偏移量,最大为1MB,另外,内核会确保该区域对齐到页帧,这是体系结构的要求 return PAGE_ALIGN(TASK_SIZE - gap - mmap_rnd()); }
从某种程度上来说,64位体系结构的情况会好一点,因为不需要在不同的地址空间布局中进行选择,在64位体系结构下,虚拟地址空间如此巨大,以至于堆和mmap区域的碰撞几乎不可能,所以依然可以使用老的进程布局空间,AMD64系统上对虚拟地址空间总是使用经典布局,因此无需区分各种选项,如果设置了PF_RANDOMIZE标志,则进行地址空间随机化,变动原本固定的mmap_base
我们回到最初对load_elf_binary函数的讨论上来,该函数最后需要在适当的位置创建栈
static int load_elf_binary(struct linux_binprm *bprm, struct pt_regs *regs) { .. retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP), executable_stack); if (retval < 0) { send_sig(SIGKILL, current, 0); goto out_free_dentry; } .. }
标准函数setup_arg_pages即用于建立在适当的位置创建栈,该函数需要栈顶的位置作为参数,栈顶由特定于体系结构的常数STACK_TOP给出,而后调用randomize_stack_top,确保在启用地址空间随机化的情况下,对该地址进行随机偏移
3. 内存映射的原理
由于所有用户进程总的虚拟地址空间比可用的物理内存大得多,因此只有最常用的部分才会与物理页帧关联,大部多程序只占用实际内存的一小部分。内核必须提供数据结构,以建立虚拟地址空间的区域和相关数据所在位置之间的关联,例如在映射文本文件时,映射的虚拟内存区必须关联到文件系统在硬盘上存储文件内容的区域

需要明白的是,文件数据在硬盘上的存储通常并不是连续的,而是分布到若干小的区域,内核利用address_space数据结构,提供一组方法从"后备存储器"读取数据,例如从文件系统读取,因此address_space形成了一个辅助层,将映射的数据表示为连续的线性区域,提供给内存管理子系统
按需分配和填充页称之为"按需调页法(demand paging)",它基于处理器和内核之间的交互

1. 进程试图访问用户地址空间中的一个内存地址,但使用页表无法确定物理地址(即物理内存中没有关联页) 2. 处理器接下来触发一个缺页异常,发送到内核 3. 内核会检查负责缺页区域的进程地址空间的数据结构,找到适当的后备存储器,或者确认该访问实际上是不正确的 4. 分配物理内存页,并从后备存储器读取所需数据进行填充 5. 借助于页表将物理内存页并入到用户进程的地址空间(即建立映射),回到发生缺页中断的那行代码位置,应用程序恢复执行
这一系列操作对用户进程是透明的,即进程不会注意到页是实际上在物理内存中(即建立了虚拟内存和物理内存的映射),还是需要通过按需调页加载(映射未建立)
4. 数据结构
我们知道struct mm_struct是进程虚拟内存管理中一个很重要的数据结构,该结构提供了进程在内存布局中所有必要信息,我们着重讨论下下列成员,用于管理用户进程在虚拟地址空间中的所有内存区域
struct mm_struct { .. //虚拟内存区域列表 struct vm_area_struct * mmap; struct rb_root mm_rb; //上一次find_vma的结果 struct vm_area_struct * mmap_cache; .. }
0x1: 树和链表
进程的每个虚拟内存区域都通过一个struct vm_area_struct实例描述,进程的各区域按两种方式排序
1. 在一个单链表上(开始于mm_strcut->mmap) 用户虚拟地址空间中的每个区域由开始和结束地址描述,现存的区域按起始地址以递增次序被归入链表中,扫描链表找到与特定地址关联的区域,在有大量区域时是非常低效的操作(数据密集型的应用程序就是这样),因此vm_area_struct的各个实例还通过红黑树进行管理,可以显著加快扫描速度 2. 在一个红黑树中,根节点位于mm_rb 红黑树是一种二叉查找树,其结点标记有颜色(红或黑),它们具有普通查找树的所有性质(因此扫描特定的结点非常高效),结点的红黑标记也可以简化重新平衡树的过程
增加新区域时(载入新模块、映射新文件等),内核首先搜索红黑树,找到刚好在新区域之前的区域,因此,内核可以向树和线性链表添加新的区域,而无需扫描链表
0x2: 虚拟内存区域的表示
进程虚拟内存的每个区域表示为struct vm_area_struct的一个实例
关于struct vm_area_struct的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x2: struct vm_area_struct
0x3: 优先查找树
优先查找树(priority search tree)用于建立文件中的一个区域与该区域映射到所有虚拟地址空间之间的关联(例如一个进程文件被多个用户打开)
1. 附加的数据结构
每个打开文件(和每个块设备,因为块设备也可以通过设备文件进行内存映射)都表示为struct file的一个实例,该结构包含了一个指向文件地址空间对象struct address_space的指针
关于struct file的相关知识,请参阅另一篇文章 http://www.cnblogs.com/LittleHann/p/3865490.html //0x1: struct file
该对象(struct address_space)是优先查找树(prio tree)的基础,文件区间与其映射到的地址空间之间的关联即通过优先树建立
\linux-2.6.32.63\include\linux\fs.h
struct address_space { struct inode *host; .. struct prio_tree_root i_mmap; struct list_head i_mmap_nonlinear; .. } struct file { .. struct address_space *f_mapping; .. }
此外,每个文件和块设备都表示为strcut inode的一个实例,struct file是通过open系统调用打开的文件的抽象,与此相反的是,inode则表示系统自身中的对象
\linux-2.6.32.63\include\linux\fs.h
struct inode { .. struct address_space *i_mapping; .. }

需要明白的是,虽然我们一直讨论文件区间的映射,但实际上也可以映射不同的东西,例如
1. 直接映射裸(raw)块设备上的区间,而不通过文件系统迂回 2. 在打开文件时,内核将file->f_mapping设置到inode->i_mapping 3. 这使得多个进程可以访问同一个文件,而不会干扰到其他进程 //inode是一个特定于文件的数据结构,而file则是特定于给定进程的

给出struct address_space的实例,内核可以推断相关的inode,而inode可用于访问实际存储文件数据的后备存储器(通常是块设备)
1. 地址空间是优先树的基本要素,而优先树包含了所有相关的vm_area_strcut实例,描述了与inode关联的文件区间到一些虚拟地址空间的映射 2. 由于每个struct vm_area的实例都包含了一个指向所属进程的mm_struct的指针,因此建立了关联 3. vm_area_struct还可以通过i_mmap_nonlinear为表头的双链表与一个地址空间关联,这是非线性映射(nonlinear mapping) 4. 一个给定的strcut vm_area实例,可以包含在两个数据结构中 1) 一个建立进程虚拟地址空间中的区域与潜在的文件数据之间的关联 2) 一个用于查找映射了给定文件区间的所有地址空间
2. 优先树的表示
优先树用来管理表示给定文件中特定区间的所有vm_area_struct实例,这要求该数据结构不仅可以处理重叠,还要能够处理相同的文件区间

重叠区间的管理并不复杂,区间的边界提供了一个唯一索引,可用于将各个区间存储在一个唯一的树节点中,这与基数树的思想非常相似,即如果B、C、D完全包含在另一个区间A中,那么A将是B、C、D的父节点
如果多个相同区间被归入优先树,各个优先树结点表示为一个"struct vm_area_struct->struct prio_tree_node prio_tree_node"实例,该实例与一个vm_set实例在同一个联合中,这可以将一个vm_set(进而vm_area_struct)的链表与一个优先树结点关联起来

在区间插入到优先树时,内核进行如下操作
1. 在vm_area_struct实例链接到优先树中作为结点时,prio_tree_node用于建立必要的关联。为检查是否树中已经有同样的vm_area_struct,内核利用了以下事实 1) vm_set的parent成员与prio_tree_node结构的最后一个成员是相同的,这些数据结构可据此进行协调 2) 由于parent在vm_set中并不使用,内核可以使用parent != NULL来检查当前的vm_area_struct实例是否已经在树中 3) prio_tree_node的定义还确保了在share联合内核的内存布局中,vm_set的head成员与prio_tree_node不重叠,因此二者尽管在同一个联合中,也可以同时使用 4) 因此内核使用vm_set.head指向属于一个共享映射的vm_area_struct实例列表中的第一个实例 2. 如果共享映射的链表包含一个vm_area_struct,则vm_set.list用作表头,链表包含所有涉及的虚拟内存区域
5. 对区域的操作
内核提供了各种函数来操作进程的虚拟内存区域,在建立或删除映射、创建、删除区域、查找用于新区域的适当的内存位置是所需要的标准操作,内核还负责在管理这些数据结构时进行优化

1. 如果一个新区域紧接着现存区域前后直接添加(也包括在两个现存区域之间的情况),内核将涉及的数据结构合并为一个,前提是涉及的"所有"区域的访问权限是相同的,而且是从同一个后备存储器映射的连续数据 2. 如果在区域的开始或结束处进行删除,则必须据此截断现存的数据结构 3. 如果要删除两个区域之间的一个区域,那么一方面需要减小现存数据结构的长度,另一方面需要为形成的新区域创建一个新的数据结构
我们接下来讨论如何搜索与用户空间中一个特定虚拟地址相关的区域
0x1: 将虚拟地址关联到区域
通过虚拟地址,find_vma可以查找用户地址空间中结束地址在给定地址之后的第一个区域,即满足addr < vm_area_struct->vm_end条件的第一个区域
\linux-2.6.32.63\mm\mmap.c
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. 1. struct mm_struct *mm: 指明扫描哪个进程的地址空间 2. unsigned long addr: 虚拟地址 */ struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr) { struct vm_area_struct *vma = NULL; if (mm) { /* Check the cache first. 首先检查缓存 */ /* (Cache hit rate is typically around 35%.) 缓存命中率大约是35% */ vma = mm->mmap_cache; /* 内核首先检查上次处理的区域(mm->mmap_cache)中是否"包含"嗽诩的地址,如果命中,则立即返回指针 */ if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) { struct rb_node * rb_node; rb_node = mm->mm_rb.rb_node; vma = NULL; //逐步搜索红黑树,rb_node是用于表示树中各个结点的数据结构 while (rb_node) { struct vm_area_struct * vma_tmp; //rb_entry用于从结点取出"有用数据(这里是vm_area_struct实例)" vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb); //如果当前找到的区域结束地址大于目标地址、且起始地址小于目标地址,内核就找到了一个适当的结点 if (vma_tmp->vm_end > addr) { vma = vma_tmp; if (vma_tmp->vm_start <= addr) break; //如果当前区域结束地址大于目标地址,则从左子结点开始 rb_node = rb_node->rb_left; } else //如果当前区域的结束地址小于等于目标地址,则从右子节点开始 rb_node = rb_node->rb_right; } if (vma) //如果找到适当的区域,则将其指针保存在mmap_cache中,因为下一次find_vma调用搜索同一个区域中临近地址的可能性很高 mm->mmap_cache = vma; } } return vma; } EXPORT_SYMBOL(find_vma);
find_vma_intersection是另一个辅助函数,用于确认边界为start_addr和end_addr的区间是否完全包含在一个现存区域内部,它基于find_vma
\linux-2.6.32.63\include\linux\mm.h
/* Look up the first VMA which intersects the interval start_addr..end_addr-1, NULL if none. Assume start_addr < end_addr. */ static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr) { struct vm_area_struct * vma = find_vma(mm,start_addr); if (vma && end_addr <= vma->vm_start) vma = NULL; return vma; }
0x2: 区域合并
在新区域被加到进程的地址空间时,内核会检查它是否可以与一个或多个现存区域合并,vma_merge在可能的情况下,将一个新区域与周边区域合并,它需要很多参数
\linux-2.6.32.63\mm\mmap.c
/* 1. struct mm_struct *mm: 相关进程的地址空间实例 2. struct vm_area_struct *prev: 紧接着新区域之前的区域 3. unsigned long addr: 新区域的开始地址 4. unsigned long end: 新区域的结束地址 5. unsigned long vm_flags: 新区域的标志 6. struct anon_vma *anon_vma 7. struct file *file: 如果该区域属于一个文件映射(mmap映射并不一定是文件映射),则file是一个指向表示该文件的file实例的指针 8. pgoff_t pgoff: pgoff指定了映射在文件数据内的偏移量 9. struct mempolicy *policy: 只在NUMA系统上需要 */ struct vm_area_struct *vma_merge( struct mm_struct *mm, struct vm_area_struct *prev, unsigned long addr, unsigned long end, unsigned long vm_flags, struct anon_vma *anon_vma, struct file *file, pgoff_t pgoff, struct mempolicy *policy ) { pgoff_t pglen = (end - addr) >> PAGE_SHIFT; struct vm_area_struct *area, *next; /* * We later require that vma->vm_flags == vm_flags, * so this tests vma->vm_flags & VM_SPECIAL, too. */ if (vm_flags & VM_SPECIAL) return NULL; if (prev) next = prev->vm_next; else next = mm->mmap; area = next; if (next && next->vm_end == end) /* cases 6, 7, 8 */ next = next->vm_next; /* Can it merge with the predecessor? 首先检查前一个区域的结束地址是否等于新区域的起始地址(这样才能刚好对接合并起来)(否则不具备合并的条件) */ if (prev && prev->vm_end == addr && mpol_equal(vma_policy(prev), policy) && can_vma_merge_after(prev, vm_flags, anon_vma, file, pgoff)) { /* OK, it can. Can we now merge in the successor as well? 如果是,则内核接下来必须检查两个区域 1. 确认二者的标志和映射的文件相同 2. 文件映射内部的偏移量符合连续区域的要求 3. 两个区域都不包含匿名映射 4. 而且两个区域彼此兼容 */ if (next && end == next->vm_start && mpol_equal(policy, vma_policy(next)) && /* 通过之前调用的can_vma_merge_after、之后调用can_vma_merge_before检查两个区域是否可以合并 如果前一个和后一个区域都可以与当前区域合并,还必须确认前一个和后一个区域的匿名映射可以合并,然后才能创建包含这3个区域的一个单一区域 */ can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen) && is_mergeable_anon_vma(prev->anon_vma, next->anon_vma)) { /* cases 1, 6 */ //调用vma_adjust执行最后的合并,它会适当地修改涉及的所有数据结构,包括优先树和vm_area_struct实例,还包括释放不再需要的结构实例 vma_adjust(prev, prev->vm_start, next->vm_end, prev->vm_pgoff, NULL); } else /* cases 2, 5, 7 */ vma_adjust(prev, prev->vm_start, end, prev->vm_pgoff, NULL); return prev; } /* * Can this new request be merged in front of next? */ if (next && end == next->vm_start && mpol_equal(policy, vma_policy(next)) && can_vma_merge_before(next, vm_flags, anon_vma, file, pgoff+pglen)) { if (prev && addr < prev->vm_end) /* case 4 */ vma_adjust(prev, prev->vm_start, addr, prev->vm_pgoff, NULL); else /* cases 3, 8 */ vma_adjust(area, addr, next->vm_end, next->vm_pgoff - pglen, NULL); return area; } return NULL; }
0x3: 插入区域
insert_vm_struct是内核用于插入新区域的标准函数,实际工作委托给两个辅助函数

/* Insert vm structure into process list sorted by address * and into the inode‘s i_mmap tree. If vm_file is non-NULL * then i_mmap_lock is taken here. */ int insert_vm_struct(struct mm_struct * mm, struct vm_area_struct * vma) { struct vm_area_struct * __vma, * prev; struct rb_node ** rb_link, * rb_parent; /* * The vm_pgoff of a purely anonymous vma should be irrelevant * until its first write fault, when page‘s anon_vma and index * are set. But now set the vm_pgoff it will almost certainly * end up with (unless mremap moves it elsewhere before that * first wfault), so /proc/pid/maps tells a consistent story. * * By setting it to reflect the virtual start address of the * vma, merges and splits can happen in a seamless way, just * using the existing file pgoff checks and manipulations. * Similarly in do_mmap_pgoff and in do_brk. */ if (!vma->vm_file) { BUG_ON(vma->anon_vma); vma->vm_pgoff = vma->vm_start >> PAGE_SHIFT; } /* 首先调用find_vma_prepare,通过新区域的起始地址和涉及的地址空间(mm_struct),获取下列信息 1. 前一个区域的vm_area_struct实例 2. 红黑树中保存新区域结点的父节点 3. 包含该区域自身的红黑树叶结点 C语言中函数只允许返回一个值,因此find_vma_prepare只返回一个指向前一个区域的指针作为结果,剩余的信息通过指针参数提供 */ __vma = find_vma_prepare(mm,vma->vm_start,&prev,&rb_link,&rb_parent); if (__vma && __vma->vm_start < vma->vm_end) return -ENOMEM; if ((vma->vm_flags & VM_ACCOUNT) && security_vm_enough_memory_mm(mm, vma_pages(vma))) return -ENOMEM; /* 查找到的信息通过vma_link将新区域合并到该进程现存的数据结构中,在经过一些准备工作之后,该函数将实际工作委托给其他函数,完成实际的工作 1. __vma_link_list: 将新区域放置到进程管理区域的线性链表上,完成该工作,需要提供使用find_vma_prepare找到的前一个和后一个区域 2. __vma_link_rb: 将新区域连接到红黑树 3. __anon_vma_link: 将vm_area_struct实例添加到匿名映射的链表上 4. __vma_link_file: 将相关的address_space和映射(如果是文件映射)关联起来,并使用vma_prio_tree_insert将该区域添加到优先树中,对多个相同区域的处理如上处理 */ vma_link(mm, vma, prev, rb_link, rb_parent); return 0; }
0x4: 创建区域
在向数据结构插入新的内存区域之前,内核必须确认虚拟地址空间中有足够的空闲空间,可用于给定长度的区域,该工作由get_unmapped_area辅助函数完成
我们知道,根据进程虚拟地址空间的布局,会选择不同的映射函数,我们着重讨论在大多数系统上采用的标准函数arch_get_unmapped_area
/* Get an address range which is currently unmapped. * For shmat() with addr=0. * * Ugly calling convention alert: * Return value with the low bits set means error value, * ie * if (ret & ~PAGE_MASK) * error = ret; * * This function "knows" that -ENOMEM has the bits set. */ #ifndef HAVE_ARCH_UNMAPPED_AREA unsigned long arch_get_unmapped_area(struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags) { struct mm_struct *mm = current->mm; struct vm_area_struct *vma; unsigned long start_addr; //检查是否超过了进程虚拟地址空间的上界 if (len > TASK_SIZE) return -ENOMEM; //检查是否设置了MAP_FIXED标志,该标志表示映射将在固定地址创建,如果是,内核只会确保该地址满足对齐要求(按页对齐),而且所要求的区间完全在可用地址空间中 if (flags & MAP_FIXED) return addr; if (addr) { addr = PAGE_ALIGN(addr); vma = find_vma(mm, addr); //如果指定了ige特定的优先选用(非固定地址)地址,内核会检查该区域是否与现存区域重叠,如果不重叠,则将该地址作为目标返回 if (TASK_SIZE - len >= addr && (!vma || addr + len <= vma->vm_start)) return addr; } if (len > mm->cached_hole_size) { start_addr = addr = mm->free_area_cache; } else { start_addr = addr = TASK_UNMAPPED_BASE; mm->cached_hole_size = 0; } full_search: /* 否则,内核必须遍历进程中可用的区域,设法找到一个大小适当的空闲区域 实际的遍历,或者开始于虚拟地址空间中最后一个"空洞"的地址 或者开始于全局的起始地址TASK_UNMAPPED_BASE */ for (vma = find_vma(mm, addr); ; vma = vma->vm_next) { /* At this point: (!vma || addr < vma->vm_end). */ if (TASK_SIZE - len < addr) { /* * Start a new search - just in case we missed * some holes. */ if (start_addr != TASK_UNMAPPED_BASE) { addr = TASK_UNMAPPED_BASE; start_addr = addr; mm->cached_hole_size = 0; goto full_search; } /* 如果搜索持续到用户地址空间的末端(TASK_SIZE)。仍然没有找到适当的区域,则内核返回一个-ENOMEM错误,错误必须发送到用户空间,且由相关的应用程序来处理 错误码表示虚拟内存中可用内存不足,无法满足应用程序的请求 */ return -ENOMEM; } if (!vma || addr + len <= vma->vm_start) { /* * Remember the place where we stopped the search: */ mm->free_area_cache = addr + len; return addr; } if (addr + mm->cached_hole_size < vma->vm_start) mm->cached_hole_size = vma->vm_start - addr; addr = vma->vm_end; } } #endif void arch_unmap_area(struct mm_struct *mm, unsigned long addr) { /* * Is this a new hole at the lowest possible address? */ if (addr >= TASK_UNMAPPED_BASE && addr < mm->free_area_cache) { mm->free_area_cache = addr; mm->cached_hole_size = ~0UL; } }
6. 地址空间
文件的内存映射可以认为是两个不同的地址空间之间的映射,即用户进程的虚拟地址空间和文件系统所在的地址空间。在内核创建一个映射时,必须建立两个地址之间的关联,以支持二者以读写请求的形式通信,vm_operations_struct结构即用于完成该工作,它提供了一个操作,来读取已经映射到虚拟地址空间、但其内容尚未进入物理内存的页
struct vm_area_struct { .. struct vm_operations_struct *vm_ops; .. }
但该操作不了解映射类型或其性质的相关信息,由于存在许多种类的文件映射(不同类型文件系统上的普通文件、设备文件等),因此需要更多的信息,即内核需要更详细地说明数据源所在的地址空间
address_space结构,即为该目的定义,包含了有关映射的附加信息,每一个文件映射都有一个先关的address_space实例,每个地址空间都有一组相关的操作,以函数指针的形式保存在如下结构中
\linux-2.6.32.63\include\linux\fs.h
struct address_space_operations { //writepage将一页的内容从物理内存写回到块设备上对应的位置,以便永久保存更改的内容 int (*writepage)(struct page *page, struct writeback_control *wbc); //readpage从潜在的块设备读取一页到物理内存中 int (*readpage)(struct file *, struct page *); void (*sync_page)(struct page *); /* Write back some dirty pages from this mapping. */ int (*writepages)(struct address_space *, struct writeback_control *); /* Set a page dirty. Return true if this dirtied it set_page_dirty表示一页的内容已经改变,即与块设备上的原始内容不再匹配 */ int (*set_page_dirty)(struct page *page); int (*readpages)(struct file *filp, struct address_space *mapping, struct list_head *pages, unsigned nr_pages); int (*write_begin)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata); int (*write_end)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata); /* Unfortunately this kludge is needed for FIBMAP. Don‘t use it */ sector_t (*bmap)(struct address_space *, sector_t); void (*invalidatepage) (struct page *, unsigned long); int (*releasepage) (struct page *, gfp_t); ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov, loff_t offset, unsigned long nr_segs); int (*get_xip_mem)(struct address_space *, pgoff_t, int, void **, unsigned long *); /* migrate the contents of a page to the specified target */ int (*migratepage) (struct address_space *, struct page *, struct page *); int (*launder_page) (struct page *); int (*is_partially_uptodate) (struct page *, read_descriptor_t *, unsigned long); int (*error_remove_page)(struct address_space *, struct page *); };
vm_operations_struct和address_space之间的联系如何建立,这里不存在将一个结构的实例分配到另一个结构的静态连接,而是这两个结构仍然使用内核为vm_operations_struct提供的标准实现连接起来,几乎所有的文件系统都使用了这种方式
\linux-2.6.32.63\mm\filemap.c
const struct vm_operations_struct generic_file_vm_ops = { .fault = filemap_fault, };
filemap_fault的实现使用了相关映射的readpage方法,因此也采用了上述的address_space
7. 内存映射
我们继续讨论在建立映射时,内核和应用程序之间的交互,我们知道C标准库提供了mmap函数建立映射,在内核一端,提供了两个系统调用mmap、mmap2。某些体系结构实现了两个版本(例如IA64、Sparc(64)),其他的只实现了第一个(AMD64)或第二个(IA-32),两个函数的参数相同
asmlinkage long sys_mmap(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long);
这两个调用都会在用户虚拟地址空间中的pos位置,建立一个长度为len的映射,其访问权限通过prot定义,flags是一个标志集用于设置一些参数,相关的文件通过其文件描述符fs标识
mmap和mmap2之间的差别在于偏移量的予以(off)
1. mmap: 位置的单位是字节 2. mmap2: 位置的单位是页(PAGE_SIZE) //它们都表示映射在文件中开始的位置,即使文件本身比可用空间大,也可以映射文件的一部分
通常C标准库只提供一个函数,由应用程序来创建内存映射,接下来该函数调用在内部转换为适合于体系结构的系统调用
在使用munmap系统调用删除映射时,因为不需要文件偏移量,因此不需要munmap2,只需要提供映射的虚拟地址即可
0x1: 创建映射
#include <sys/mman.h> /* 1. start:映射区的开始地址,设置为0时表示由系统决定映射区的起始地址 2. length:映射区的长度。//长度单位是 以字节为单位,不足一内存页按一内存页处理 3. prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起 1) PROT_EXEC //页内容可以被执行 2) PROT_READ //页内容可以被读取 3) PROT_WRITE //页可以被写入 4) PROT_NONE //页不可访问 4. flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体 1) MAP_FIXED //使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。如果没有设置该标志,内核可以在受阻时随意改变目标地址 2) MAP_SHARED //与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。如果一个对象(通常是文件)在几个进程之间共享时,则必须使用MAP_SHARED 3) MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。 4) MAP_DENYWRITE //这个标志被忽略 5) MAP_EXECUTABLE //同上 6) MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。 7) MAP_LOCKED //锁定映射区的页面,从而防止页面被交换出内存 8) MAP_GROWSDOWN //用于堆栈,告诉内核VM系统,映射区可以向下扩展。 9) MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联,fd和off参数被忽略,此类映射可用于为应用程序分配类似malloc所用的内存 10) MAP_ANON //MAP_ANONYMOUS的别称,不再被使用 11) MAP_FILE //兼容标志,被忽略 12) MAP_32BIT //将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。 13) MAP_POPULATE //为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。 14) MAP_NONBLOCK //仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。 5. fd:有效的文件描述词。一般是由open()函数返回,其值也可以设置为-1,此时需要指定flags参数中的MAP_ANON,表明进行的是匿名映射。 6. off_toffset:被映射对象内容的起点 */ void* mmap(void* start, size_t length, int prot, int flags, int fd, off_t offset);
prot指定了映射内存的访问权限,但并非所有处理器都实现了所有组合,因而区域实际授予的权限可能比指定的要多,尽管内核尽力设置指定的权限,但它只能保证实际设置的访问权限不会比指定的权限有更多的限制
sys_mmap、sys_mmap2最终会将工作委托给do_mmap_pgoff
\linux-2.6.32.63\mm\mmap.c

/* * The caller must hold down_write(¤t->mm->mmap_sem). */ unsigned long do_mmap_pgoff(struct file *file, unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, unsigned long pgoff) { struct mm_struct * mm = current->mm; struct inode *inode; unsigned int vm_flags; int error; unsigned long reqprot = prot; /* * Does the application expect PROT_READ to imply PROT_EXEC? * * (the exception is when the underlying filesystem is noexec * mounted, in which case we dont add PROT_EXEC.) */ if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC)) if (!(file && (file->f_path.mnt->mnt_flags & MNT_NOEXEC))) prot |= PROT_EXEC; if (!len) return -EINVAL; if (!(flags & MAP_FIXED)) addr = round_hint_to_min(addr); /* Careful about overflows.. */ len = PAGE_ALIGN(len); if (!len) return -ENOMEM; /* offset overflow? */ if ((pgoff + (len >> PAGE_SHIFT)) < pgoff) return -EOVERFLOW; /* Too many mappings? */ if (mm->map_count > sysctl_max_map_count) return -ENOMEM; /* Obtain the address to map to. we verify (or select) it and ensure * that it represents a valid section of the address space. 首先调用get_unmapped_area函数,在虚拟地址空间中找到一个适当的区域用于映射 1. 应用程序可以对映射指定固定地址 2. 建议一个地址 3. 由内核选择地址 */ addr = get_unmapped_area(file, addr, len, pgoff, flags); if (addr & ~PAGE_MASK) return addr; /* Do simple checking here so the lower-level routines won‘t have * to. we assume access permissions have been handled by the open * of the memory object, so we don‘t do any here. calc_vm_prot_bits、calc_vm_flag_bits将系统调用中指定的标志和访问权限常数合并到一个共同的标志集中 在后续的操作中比较易于处理(MAP_、PROT_表示转换为VM_前缀的标志) 最有趣的是,内核在从当前运行进程的mm_struct实例获得def_flags之后,又将其包含到标志集中,def_flags的值可以以下 1. 0: 不会改变结果标志集 2. VM_LOCK: 意味着随后映射的页无法换出 为了设置def_flags的值,进程必须发出mlockall系统调用 */ vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC; if (flags & MAP_LOCKED) if (!can_do_mlock()) return -EPERM; /* mlock MCL_FUTURE? */ if (vm_flags & VM_LOCKED) { unsigned long locked, lock_limit; locked = len >> PAGE_SHIFT; locked += mm->locked_vm; lock_limit = current->signal->rlim[RLIMIT_MEMLOCK].rlim_cur; lock_limit >>= PAGE_SHIFT; if (locked > lock_limit && !capable(CAP_IPC_LOCK)) return -EAGAIN; } inode = file ? file->f_path.dentry->d_inode : NULL; if (file) { switch (flags & MAP_TYPE) { case MAP_SHARED: if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE)) return -EACCES; /* * Make sure we don‘t allow writing to an append-only * file.. */ if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE)) return -EACCES; /* * Make sure there are no mandatory locks on the file. */ if (locks_verify_locked(inode)) return -EAGAIN; vm_flags |= VM_SHARED | VM_MAYSHARE; if (!(file->f_mode & FMODE_WRITE)) vm_flags &= ~(VM_MAYWRITE | VM_SHARED); /* fall through */ case MAP_PRIVATE: if (!(file->f_mode & FMODE_READ)) return -EACCES; if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) { if (vm_flags & VM_EXEC) return -EPERM; vm_flags &= ~VM_MAYEXEC; } if (!file->f_op || !file->f_op->mmap) return -ENODEV; break; default: return -EINVAL; } } else { switch (flags & MAP_TYPE) { case MAP_SHARED: /* * Ignore pgoff. */ pgoff = 0; vm_flags |= VM_SHARED | VM_MAYSHARE; break; case MAP_PRIVATE: /* * Set pgoff according to addr for anon_vma. */ pgoff = addr >> PAGE_SHIFT; break; default: return -EINVAL; } } error = security_file_mmap(file, reqprot, prot, flags, addr, 0); if (error) return error; error = ima_file_mmap(file, prot); if (error) return error; //在检查过参数并设置好所有需要的标志之后,剩余的工作委托给mmap_region return mmap_region(file, addr, len, flags, vm_flags, pgoff); } EXPORT_SYMBOL(do_mmap_pgoff);
\linux-2.6.32.63\mm\mmap.c
unsigned long mmap_region(struct file *file, unsigned long addr, unsigned long len, unsigned long flags, unsigned int vm_flags, unsigned long pgoff) { struct mm_struct *mm = current->mm; struct vm_area_struct *vma, *prev; int correct_wcount = 0; int error; struct rb_node **rb_link, *rb_parent; unsigned long charged = 0; struct inode *inode = file ? file->f_path.dentry->d_inode : NULL; /* Clear old maps */ error = -ENOMEM; munmap_back: //调用find_vma_prepare函数,来查找前一个和后一个区域的vm_area_struct实例,以及红黑树中结点对应的数据 vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent); //如果在指定的映射位置已经存在一个映射,则通过do_munmap删除它 if (vma && vma->vm_start < addr + len) { if (do_munmap(mm, addr, len)) return -ENOMEM; goto munmap_back; } /* Check against address space limit. */ if (!may_expand_vm(mm, len >> PAGE_SHIFT)) return -ENOMEM; /* * Set ‘VM_NORESERVE‘ if we should not account for the * memory use of this mapping. 如果没有设置MAP_NORESERVE标志或内核参数sysctl_overcommit_memory设置为OVERCOMMIT_NEVER(即不允许过量使用) */ if ((flags & MAP_NORESERVE)) { /* We honor MAP_NORESERVE if allowed to overcommit */ if (sysctl_overcommit_memory != OVERCOMMIT_NEVER) vm_flags |= VM_NORESERVE; /* hugetlb applies strict overcommit unless MAP_NORESERVE */ if (file && is_file_hugepages(file)) vm_flags |= VM_NORESERVE; } .. }
在内核分配了所需的内存之后,会执行下列步骤
1. 分配并初始化一个新的vm_area_struct实例,并插入到进程的链表/树数据结构中 2. 用特定于文件的函数file->f_op->mmap创建映射,大都数文件系统将generic_file_mmap用于该目的,它所作的所有工作,就是将映射的vm_ops成员设置为generic_file_vm_ops vma->vm_ops = &generic_file_vm_ops; \linux-2.6.32.63\mm\filemap.c const struct vm_operations_struct generic_file_vm_ops = { .fault = filemap_fault, };
filemap_fault在应用程序访问映射区域但对应数据不再物理内存时调用,filemap_fault借助于潜在文件系统的底层例程取得所需数据,并读取到物理内存,这些对应用程序是透明的,即映射数据不是在建立映射时立即读入内存,只有实际需要相应数据时才进行读取
这也是虚拟内存的一个核心思想,即对应用程序看到的"platform memory"来说,大部多或者说进程刚启动的时候都只一个空的东西,底层并没有实际的基础数据支撑,只有到了正常需要的时候才会去建立这个联系,这是一种典型的"延迟绑定"思想
如果设置了VM_LOCKED,或者通过系统调用的标志参数显示传递进来,或者通过mlockall机制隐式设置,内核都会调用make_pages_present依次扫描映射中每一页,对每一页触发缺页异常以便读入其数据,这同时意味着失去了延迟读取带来的性能提高,但内核可以确保在映射建立后所涉及的页总是在物理内存中,即VM_LOCKED标志用来防止从内存换出页,因此这些页必须先读进来
0x2: 删除映射
从虚拟地址空间删除现存映射,必须使用munmap系统调用,它需要两个参数
#include<sys/mman.h> /* 1. start: 解除映射区域的起始地址 2. length长度 */ int munmap(void *start, size_t length);

/* Munmap is split into 2 main parts -- this part which finds * what needs doing, and the areas themselves, which do the * work. This now handles partial unmappings. * Jeremy Fitzhardinge <jeremy@goop.org> */ int do_munmap(struct mm_struct *mm, unsigned long start, size_t len) { unsigned long end; struct vm_area_struct *vma, *prev, *last; if ((start & ~PAGE_MASK) || start > TASK_SIZE || len > TASK_SIZE-start) return -EINVAL; if ((len = PAGE_ALIGN(len)) == 0) return -EINVAL; /* Find the first overlapping VMA 内核首先必须调用find_vma_prev,以找到解除映射区域的vm_area_struct实例 */ vma = find_vma_prev(mm, start, &prev); if (!vma) return 0; /* we have start < vma->vm_end */ /* if it doesn‘t overlap, we have nothing.. */ end = start + len; if (vma->vm_start >= end) return 0; /* * If we need to split any vma, do it now to save pain later. * * Note: mremap‘s move_vma VM_ACCOUNT handling assumes a partially * unmapped vm_area_struct will remain in use: so lower split_vma * places tmp vma above, and higher split_vma places tmp vma below. 如果解除映射区域的起始地址与find_vma_prev找到的区域起始地址不同,则只解除部分映射,而不是解除整个映射区域 */ if (start > vma->vm_start) { //内核首先将现存的映射划分为几个部分,映射的前一部分不需要解除映射 int error = split_vma(mm, vma, start, 0); if (error) return error; prev = vma; } /* Does it split the last one? */ last = find_vma(mm, end); //如果解除映射的部分区域的末端与愿区域末端不重合,那么原区域后部仍然有一部分未解除映射,因此需要再进行一次映射切割 if (last && end > last->vm_start) { int error = split_vma(mm, last, end, 1); if (error) return error; } vma = prev? prev->vm_next: mm->mmap; /* * unlock any mlock()ed ranges before detaching vmas */ if (mm->locked_vm) { struct vm_area_struct *tmp = vma; while (tmp && tmp->vm_start < end) { if (tmp->vm_flags & VM_LOCKED) { mm->locked_vm -= vma_pages(tmp); munlock_vma_pages_all(tmp); } tmp = tmp->vm_next; } } /* * Remove the vma‘s, and unmap the actual pages 内核调用detach_vmas_to_be_unmapped列出所有需要解除映射的区域,由于解除映射操作可能涉及地址空间中的任何区域,很可能影响连续几个区域 内核可能拆分这一系列区域中首尾两端的区域,以确保只影响到完整的区域 */ detach_vmas_to_be_unmapped(mm, vma, prev, end); //调用unmap_region从页表删除与映射相关的所有项,完成后,内核还必须确保将相关的项从TLB移除或者使之无效 unmap_region(mm, vma, prev, start, end); /* Fix up all other VM information 用remove_vma_list释放vm_area_strcut实例占用的空间,完成从内核中删除映射的工作 */ remove_vma_list(mm, vma); return 0; }
0x3: 非线性映射
普通的映射将文件中一个连续的部分映射到虚拟内存中一个同样连续的部分,如果需要将文件的不同部分以不同顺序映射到虚拟内存的连续区域中,实现的一个简单有效的方法是使用非线性映射,内核提供了一个独立的系统调用,专门用于该目的
\linux-2.6.32.63\mm\fremap.c
/** * sys_remap_file_pages - remap arbitrary pages of an existing VM_SHARED vma * @start: start of the remapped virtual memory range * @size: size of the remapped virtual memory range * @prot: new protection bits of the range (see NOTE) * @pgoff: to-be-mapped page of the backing store file * @flags: 0 or MAP_NONBLOCKED - the later will cause no IO. * * sys_remap_file_pages remaps arbitrary pages of an existing VM_SHARED vma * (shared backing store file). * * This syscall works purely via pagetables, so it‘s the most efficient * way to map the same (large) file into a given virtual window. Unlike * mmap()/mremap() it does not create any new vmas. The new mappings are * also safe across swapout. * * NOTE: the @prot parameter right now is ignored (but must be zero), * and the vma‘s default protection is used. Arbitrary protections * might be implemented in the future. */ SYSCALL_DEFINE5(remap_file_pages, unsigned long, start, unsigned long, size, unsigned long, prot, unsigned long, pgoff, unsigned long, flags) { struct mm_struct *mm = current->mm; struct address_space *mapping; unsigned long end = start + size; struct vm_area_struct *vma; int err = -EINVAL; int has_write_lock = 0; if (prot) return err; /* * Sanitize the syscall parameters: */ start = start & PAGE_MASK; size = size & PAGE_MASK; /* Does the address range wrap, or is the span zero-sized? */ if (start + size <= start) return err; /* Can we represent this offset inside this architecture‘s pte‘s? */ #if PTE_FILE_MAX_BITS < BITS_PER_LONG if (pgoff + (size >> PAGE_SHIFT) >= (1UL << PTE_FILE_MAX_BITS)) return err; #endif /* We need down_write() to change vma->vm_flags. */ down_read(&mm->mmap_sem); retry: vma = find_vma(mm, start); /* * Make sure the vma is shared, that it supports prefaulting, * and that the remapped range is valid and fully within * the single existing vma. vm_private_data is used as a * swapout cursor in a VM_NONLINEAR vma. */ if (!vma || !(vma->vm_flags & VM_SHARED)) goto out; if (vma->vm_private_data && !(vma->vm_flags & VM_NONLINEAR)) goto out; if (!(vma->vm_flags & VM_CAN_NONLINEAR)) goto out; if (end <= start || start < vma->vm_start || end > vma->vm_end) goto out; /* Must set VM_NONLINEAR before any pages are populated. */ if (!(vma->vm_flags & VM_NONLINEAR)) { /* Don‘t need a nonlinear mapping, exit success */ if (pgoff == linear_page_index(vma, start)) { err = 0; goto out; } if (!has_write_lock) { up_read(&mm->mmap_sem); down_write(&mm->mmap_sem); has_write_lock = 1; goto retry; } mapping = vma->vm_file->f_mapping; /* * page_mkclean doesn‘t work on nonlinear vmas, so if * dirty pages need to be accounted, emulate with linear * vmas. */ if (mapping_cap_account_dirty(mapping)) { unsigned long addr; struct file *file = vma->vm_file; flags &= MAP_NONBLOCK; get_file(file); addr = mmap_region(file, start, size, flags, vma->vm_flags, pgoff); fput(file); if (IS_ERR_VALUE(addr)) { err = addr; } else { BUG_ON(addr != start); err = 0; } goto out; } spin_lock(&mapping->i_mmap_lock); flush_dcache_mmap_lock(mapping); vma->vm_flags |= VM_NONLINEAR; vma_prio_tree_remove(vma, &mapping->i_mmap); vma_nonlinear_insert(vma, &mapping->i_mmap_nonlinear); flush_dcache_mmap_unlock(mapping); spin_unlock(&mapping->i_mmap_lock); } if (vma->vm_flags & VM_LOCKED) { /* * drop PG_Mlocked flag for over-mapped range */ unsigned int saved_flags = vma->vm_flags; munlock_vma_pages_range(vma, start, start + size); vma->vm_flags = saved_flags; } mmu_notifier_invalidate_range_start(mm, start, start + size); err = populate_range(mm, vma, start, size, pgoff); mmu_notifier_invalidate_range_end(mm, start, start + size); if (!err && !(flags & MAP_NONBLOCK)) { if (vma->vm_flags & VM_LOCKED) { /* * might be mapping previously unmapped range of file */ mlock_vma_pages_range(vma, start, start + size); } else { if (unlikely(has_write_lock)) { downgrade_write(&mm->mmap_sem); has_write_lock = 0; } make_pages_present(start, start+size); } } /* * We can‘t clear VM_NONLINEAR because we‘d have to do * it after ->populate completes, and that would prevent * downgrading the lock. (Locks can‘t be upgraded). */ out: if (likely(!has_write_lock)) up_read(&mm->mmap_sem); else up_write(&mm->mmap_sem); return err; }
sys_remap_file_pages系统调用允许重排映射中的页,使得内存与文件中的顺序不再等价,实现该特性无需移动内存中的数据,而是通过操作进程的页表实现
sys_remap_file_pages可以将现存映射(位置pgoff、长度size)移动到虚拟内存中的一个新位置,start标识了移动的目标映射,因而必须落入某个现存映射的地址范围中,它还指定了由pgoff和size标识的页移动的目标位置
8. 反向映射
内核通过页表,可以建立虚拟和物理地址之间的联系,以及进程的一个内存映 射区域与其虚拟内存页地址之间的关联,我们接下来讨论最后一个联系: 物理内存页和该页所属进程(准确地说去所有使用该页的进程的对应页表项)之间的联系。在换出页时需要该关联,以便更新所有涉及的进程,因为页已经换出,必 须在页表中标明,以便在这些进程访问对相应页的时候产生缺页中断的时候能够知道需要进行页换入
1. 在映射一页时,它关联到一个进程,但不一定处于使用中 2. 对页的引用次数表明页使用的活跃程度,为确定该数目,内核首先必须建立页和所有使用者之间的关联,还必须借助一些技巧来计算出页使用的活跃程度
因此第一个任务需要建立页和所有映射了该页的位置之间的关联,为此内核使用一些附加的数据结构和函数,采用一种逆向映射方法
0x1: 数据结构
内核使用饿了简洁的数据结构,以最小化逆向映射的管理开销,struct page结构包含了一个用于实现逆向映射的成员
struct page { .. /* 内存管理子系统中映射的页表项计数,用于表示页是否已经映射,还用于限制逆向映射搜索 */ atomic_t _mapcount; .. }
_mapcount表明共享该页的位置的数目,计数器的初始值为-1,在页插入到逆向映射数据结构时,计数器赋值为0,页每次增加一个使用者时,计数器加1,这使得内核能够快速检查在所有者之外,该页有多少使用者
但是要完成逆向映射的目的: 给定page实例,找到所有映射了该物理内存页的位置,还需要两个其他的数据机构发挥作用
1. 优先查找树中嵌入了属于非匿名映射的每个区域 2. 指向内存中同一页的匿名区域的链表 struct vm_area_struct { .. union { /* links to address_space->i_mmap or i_mmap_nonlinear */ struct { struct list_head list; void *parent; struct vm_area_struct *head; } vm_set; struct prio_tree_node prio_tree_node; } shared; /* 在文件的某一页经过写时复制之后,文件的MAP_PRIVATE虚拟内存区域可能同时在i_mmap树和anon_vma链表中,MAP_SHARED虚拟内存区域只能在i_mmap树中 匿名的MAP_PRIVATE、栈或brk虚拟内存区域(file指针为NULL)只能处于anon_vma链表中 */ struct list_head anon_vma_node; /* anon_vma entry 对该成员的访问通过anon_vma->lock串行化 */ struct anon_vma *anon_vma; /* anonymous VMA object 对该成员的 .. }
内核在实现逆向映射时采用的技巧是,不直接保存页和相关的使用者之间的关联,而只保存页和页所在区域的关联,包含该页的所有其他区域(进而所有的使用者)都可以通过这以上数据机构找到。该方法又名"基于对象的逆向映射(object-based reverse mapping)",因为没有存储页和使用者之间的直接关联,相反,在两者之间插入了另一个对象(该页所在的区域)
0x2: 建立逆向映射
在创建逆向映射时,有必要区分两个备选项: 匿名页和基于文件映射的页,因为用于管理这两种选项的数据机构不同
1. 匿名页 将匿名页插入到逆向映射数据结构中有两种方法 1) 对新的匿名页必须调用page_add_new_anon_rmap: 将映射计数器page->_mapcount设置为0 2) 已经有引用计数的页,则使用page_add_anon_rmap: 将计数器加1 2. 基于文件映射的页 所需要的只是对_mapcount变量加1(原子操作)并更新各内存域的统计量
0x3: 使用逆向映射
page_referenced是一个重要的函数,很好地使用了逆向映射方案所涉及的数据结构,它统计了最近活跃地使用(即访问)了某个共享页的进程的数目,这不同于该页映射到的区域数目,后者大多数情况下是静态的,而如果处于使用中,前者(访问频率)会很快发生改变
该函数相当于一个多路复用器
1. 对匿名页调用page_referenced_anon 2. 对于基于文件映射的页调用page_referenced_file //分别调用的两个函数,其目的都是确定有多少地方在使用一个页,但由于底层数据结构的不同,二者采用了不同的方法
1. 匿名页函数
\linux-2.6.32.63\mm\rmap.c
static int page_referenced_anon(struct page *page, struct mem_cgroup *mem_cont, unsigned long *vm_flags) { unsigned int mapcount; struct anon_vma *anon_vma; struct vm_area_struct *vma; int referenced = 0; //调用page_lock_anon_vma辅助函数,找到引用了某个特定page实例的区域的列表 anon_vma = page_lock_anon_vma(page); if (!anon_vma) return referenced; mapcount = page_mapcount(page); //在找到匹配的anon_vma实例之后,内核遍历链表中的所有区域,分别调用page_referenced_one,计算使用该页的次数(在系统换入/换出页时,需要一些校正) list_for_each_entry(vma, &anon_vma->head, anon_vma_node) { /* * If we are reclaiming on behalf of a cgroup, skip * counting on behalf of references from different * cgroups */ if (mem_cont && !mm_match_cgroup(vma->vm_mm, mem_cont)) continue; referenced += page_referenced_one(page, vma, &mapcount, vm_flags); if (!mapcount) break; } page_unlock_anon_vma(anon_vma); return referenced; }
page_referenced_one分为两个步骤执行其任务
1. 找到指向该页的页表项 2. 检查页表项是否设置了_PAGE_ACCESSED标志位,然后清除该标志位,每次访问该页时,硬件会设置该标志(如果特定体系结构有需要,内核也会提供额外的支持),如果设置了该标志位,则引用计数器加1,否则不变,因此经常使用的页引用计数较高,而很少使用页相反,因此内核会根据引用计数,立即就能判断某一页似乎否重要
2. 基于文件映射的函数
在检查基于文件映射的页的引用次数时,采用的方法类似
static int page_referenced_file(struct page *page, struct mem_cgroup *mem_cont, unsigned long *vm_flags) { unsigned int mapcount; struct address_space *mapping = page->mapping; pgoff_t pgoff = page->index << (PAGE_CACHE_SHIFT - PAGE_SHIFT); struct vm_area_struct *vma; struct prio_tree_iter iter; int referenced = 0; /* * The caller‘s checks on page->mapping and !PageAnon have made * sure that this is a file page: the check for page->mapping * excludes the case just before it gets set on an anon page. */ BUG_ON(PageAnon(page)); /* * The page lock not only makes sure that page->mapping cannot * suddenly be NULLified by truncation, it makes sure that the * structure at mapping cannot be freed and reused yet, * so we can safely take mapping->i_mmap_lock. */ BUG_ON(!PageLocked(page)); spin_lock(&mapping->i_mmap_lock); /* * i_mmap_lock does not stabilize mapcount at all, but mapcount * is more likely to be accurate if we note it after spinning. */ mapcount = page_mapcount(page); vma_prio_tree_foreach(vma, &iter, &mapping->i_mmap, pgoff, pgoff) { /* * If we are reclaiming on behalf of a cgroup, skip * counting on behalf of references from different * cgroups */ if (mem_cont && !mm_match_cgroup(vma->vm_mm, mem_cont)) continue; referenced += page_referenced_one(page, vma, &mapcount, vm_flags); if (!mapcount) break; } spin_unlock(&mapping->i_mmap_lock); return referenced; }
9.堆的管理
堆是进程中用于动态分配变量和数据的内存区域,堆的管理对应用程序员来说不是直接可见的,它依赖标准库提供的各个辅助函数来分配任意长度的内存区
关于Glibc库如何接管Linux下堆内存的管理的相关知识,请参阅另一篇文章 http://www.cnblogs.com/LittleHann/p/4012086.html //搜索:16. 堆与内存管理
堆是一个连续的内存区域,在扩展时自下至上(经典布局)增长,我们之前讨论的mm_strcut结构,包含了堆在虚拟地址空间中的起始和当前结束地址
struct mm_struct { .. unsigned long start_brk, brk; .. }
Glibc和内核使用mmap、brk作为堆管理的接口,而其中brk是一种经典的系统调用,负责扩展/收缩堆,最新的GNU malloc实现,使用了一种组合的方法,使用brk和匿名映射,该方法提供了更好的性能,而且在分配较大内存区时具有更好的性能
#include <unistd.h> //brk系统调用只需要一个参数,用于指定堆在虚拟地址空间中新的结束地址(如果堆将要收缩,可以小于当前值) int brk(void *addr);

brk机制不是一个独立的内核概念,而是基于匿名映射实现,以减少内部的开销
SYSCALL_DEFINE1(brk, unsigned long, brk) { unsigned long rlim, retval; unsigned long newbrk, oldbrk; struct mm_struct *mm = current->mm; unsigned long min_brk; down_write(&mm->mmap_sem); #ifdef CONFIG_COMPAT_BRK min_brk = mm->end_code; #else min_brk = mm->start_brk; #endif if (brk < min_brk) goto out; /* * Check against rlimit here. If this check is done later after the test * of oldbrk with newbrk then it can escape the test and let the data * segment grow beyond its set limit the in case where the limit is * not page aligned -Ram Gupta 检查用作brk值的新地址是否超出堆的限制 */ rlim = current->signal->rlim[RLIMIT_DATA].rlim_cur; if (rlim < RLIM_INFINITY && (brk - mm->start_brk) + (mm->end_data - mm->start_data) > rlim) goto out; //将请求的地址按页长度对齐,以确保brk的新值(原值也同样)是系统页长度的倍数,一页是brk能分配的最小内存区域 newbrk = PAGE_ALIGN(brk); oldbrk = PAGE_ALIGN(mm->brk); if (oldbrk == newbrk) goto set_brk; /* Always allow shrinking brk. */ if (brk <= mm->brk) { if (!do_munmap(mm, newbrk, oldbrk-newbrk)) goto set_brk; goto out; } /* Check against existing mmap mappings. find_vma_intersection接下来检查扩大的堆是否与进程中现存的映射重叠(因为堆生长的方向是不断靠近映射所在的虚拟内存区域) */ if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE)) goto out; /* Ok, looks good - let it rip. 扩大堆的实际工作委托给do_brk,函数总是返回mm->brk的新值,无论是扩大,还是缩小 do_brk实际上在用户地址空间创建了一个匿名映射,但省去了一些安全检查和用于提高代码性能的对特殊情况的处理 */ if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk) goto out; set_brk: mm->brk = brk; out: retval = mm->brk; up_write(&mm->mmap_sem); return retval; }
10. 缺页异常的处理
在实际需要某个虚拟内存区域的数据之前,虚拟和物理内存之间的关联不会建立,如果进程访问老的虚拟地址空间部分尚未与页帧关联,处理器自动自动地触发一个缺页异常,内核必须处理此异常,这是内存中最重要、最复杂的方面之一,因为还需要考虑其他的细节,包括
1. 缺页异常是由于访问用户地址空间中的有效地址而引起的,还是应用程序试图访问内核的受保护区域 2. 目标地址对应于某个现存的映射吗 3. 获取该区域的数据,需要使用何种机制
下图给出了内核在处理缺页异常时,可能使用的各种代码途径的一个大致的流程

缺页处理的实现因处理器的不同而有所不同,由于CPU采用了不同的内存管理概念,生成缺页异常的细节也不太相同,因此,缺页异常的处理例程在内核代码中处于特定于体系结构的部分,我们着重讨论IA-32体系结构上采用的方法,因为在最低限度上,大多数其他CPU的实现是类似的
缺页中断属于系统软中断的一种
\linux-2.6.32.63\arch\x86\kernel\entry_32.S中的一个汇编例程用作用作缺页异常的入口
ENTRY(page_fault) RING0_EC_FRAME pushl $do_page_fault CFI_ADJUST_CFA_OFFSET 4 ALIGN error_code: .. END(page_fault)
其立即调用了\linux-2.6.32.63\arch\x86\mm\fault.c中的C例程do_page_fault

/* * This routine handles page faults. It determines the address, * and the problem, and then passes it off to one of the appropriate * routines. 1. struct pt_regs *regs: 发生异常时使用中的寄存器集合 2. unsigned long error_code: 提供异常原因的错误代码,error_code目前只使用了前5个比特位(0、1、2、3、4),语义如下 1) 0 bit: 1.1) 置位1: 缺页 1.2) 置位0: 保护异常(没有足够的访问权限) 2) 1 bit: 2.1) 置位1: 读访问 2.2) 置位0: 写访问 3) 2 bit: 3.1) 置位1: 核心态 3.2) 置位0: 用户态 4) 3 bit: 4.1) 置位1: 检测到使用了保留位 4.2) 置位0: 5) 4 bit: 5.1) 置位1: 缺页异常是在取指令时出现的 5.2) 置位0: */ dotraplinkage void __kprobes do_page_fault(struct pt_regs *regs, unsigned long error_code) { struct vm_area_struct *vma; struct task_struct *tsk; unsigned long address; struct mm_struct *mm; int write; int fault; tsk = current; mm = tsk->mm; /* Get the faulting address: 内核在address中保存饿了触发异常的地址 */ address = read_cr2(); /* * Detect and handle instructions that would cause a page fault for * both a tracked kernel page and a userspace page. */ if (kmemcheck_active(regs)) kmemcheck_hide(regs); prefetchw(&mm->mmap_sem); if (unlikely(kmmio_fault(regs, address))) return; /* * We fault-in kernel-space virtual memory on-demand. The reference‘ page table is init_mm.pgd * 我们因为异常而进入到内核虚拟内存空间,参考页表为init_mm.pgd * * NOTE! We MUST NOT take any locks for this case. We may be in an interrupt or a critical region, * and should only copy the information from the master page table, nothing more. * 要注意!在这种情况下我们不能获取任何锁,因为我们可能是在中断或者临界区中 * 只应该从主页表中复制信息,不允许其他操作 * * This verifies that the fault happens in kernel space (error_code & 4) == 0, * and that the fault was not a protection error (error_code & 9) == 0. * 下述代码验证了异常发生于内核空间(error_code & 4) == 0, 而且异常不是保护错误(error_code & 9) == 0. */ /* * 缺页地址位于内核空间。并不代表异常发生于内核空间,有可能是用户态访问了内核空间的地址 */ if (unlikely(fault_in_kernel_space(address))) { if (!(error_code & (PF_RSVD | PF_USER | PF_PROT))) { /* * 检查发生缺页的地址是否在vmalloc区,是则进行相应的处理主要是从内核主页表向进程页表同步数据 * 该函数只是从init的页表(在IA-32系统上,这是内核的主页表)复制相关的项到当前页表, * 如果其中没有找到匹配项,则内核调用fixup_exception,作为试图从异常恢复的最后尝试 */ if (vmalloc_fault(address) >= 0) return; if (kmemcheck_fault(regs, address, error_code)) return; } /* Can handle a stale RO->RW TLB: */ /* * 检查是否是由于陈旧的TLB导致的假的pagefault(由于TLB的延迟flush导致, * 因为提前flush会有比较大的性能代价)。 */ if (spurious_fault(error_code, address)) return; /* kprobes don‘t want to hook the spurious faults: */ if (notify_page_fault(regs)) return; /* * Don‘t take the mm semaphore here. If we fixup a prefetch fault we could otherwise deadlock: 不要在这里获取mm信号量,如果修复了取指令造成的缺页异常,则会进入死锁 */ bad_area_nosemaphore(regs, error_code, address); return; } // 进入到这里,说明异常地址位于用户态 /* kprobes don‘t want to hook the spurious faults: */ if (unlikely(notify_page_fault(regs))) return; /* * It‘s safe to allow irq‘s after cr2 has been saved and the * vmalloc fault has been handled. * * User-mode registers count as a user access even for any * potential system fault or CPU buglet: */ /* * 开中断,这种情况下,是安全的,可以缩短因缺页异常导致的关中断时长 */ if (user_mode_vm(regs)) { local_irq_enable(); error_code |= PF_USER; } else { if (regs->flags & X86_EFLAGS_IF) local_irq_enable(); } if (unlikely(error_code & PF_RSVD)) pgtable_bad(regs, error_code, address); perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, 0, regs, address); /* * If we‘re in an interrupt, have no user context or are running * in an atomic region then we must not take the fault: */ /* * 当缺页异常发生于中断或其它atomic上下文中时,则产生异常,这种情况下,不应该再产生page fault * 典型的,利用kprobe这种基于int3中断模式的Hook架构,Hook代码运行在中断上下文中,如果Hook代码量过多,则有很大几率发生缺页中断 * 这种情况下,page fault无法得到正确处理,很容易使kernel处于异常状态 */ if (unlikely(in_atomic() || !mm)) { bad_area_nosemaphore(regs, error_code, address); return; } /* * When running in the kernel we expect faults to occur only to * addresses in user space. All other faults represent errors in * the kernel and should generate an OOPS. Unfortunately, in the * case of an erroneous fault occurring in a code path which already * holds mmap_sem we will deadlock attempting to validate the fault * against the address space. Luckily the kernel only validly * references user space from well defined areas of code, which are * listed in the exceptions table. * * As the vast majority of faults will be valid we will only perform * the source reference check when there is a possibility of a * deadlock. Attempt to lock the address space, if we cannot we then * validate the source. If this is invalid we can skip the address * space check, thus avoiding the deadlock: */ if (unlikely(!down_read_trylock(&mm->mmap_sem))) { /* * 缺页发生在内核上下文,这种情况发生缺页的地址只能位于用户态地址空间 * 这种情况下,也只能为exceptions table中预先定义好的异常,如果exceptions * table中没有预先定义的处理,或者缺页的地址位于内核态地址空间,则表示 * 错误,进入oops流程。 */ if ((error_code & PF_USER) == 0 && !search_exception_tables(regs->ip)) { bad_area_nosemaphore(regs, error_code, address); return; } // 如果发生在用户态或者有exception table,说明不是内核异常 down_read(&mm->mmap_sem); } else { /* * The above down_read_trylock() might have succeeded in * which case we‘ll have missed the might_sleep() from * down_read(): */ might_sleep(); } //如果异常并非出现在中断期间,也有相关的上下文,则内核在当前进程的地址空间中寻找发生异常的地址对应的VMA vma = find_vma(mm, address); // 如果没找到VMA,则释放mem_sem信号量后,进入__bad_area_nosemaphore处理 if (unlikely(!vma)) { bad_area(regs, error_code, address); return; } /* 搜索可能得到下面各种不同的结果 1. 没有找到结束地址在address之后的区域,即这种情况下访问是无效的 2. 找到VMA,且发生异常的虚拟地址位于vma的有效范围内,则为正常的缺页异常,则缺页异常由内核负责恢复,请求调页,分配物理内存 */ if (likely(vma->vm_start <= address)) goto good_area; /* 3. 找到了一个结束地址在异常地址之后的区域,但异常地址不在该区域内,这可能有下面两种原因 1) 该区域的VM_GROWSDOWN标志置位,这意味着区域是栈,自顶向下增长,接下来调用expand_stack适当地扩大栈,如果成功,则返回0,内核在good_area标号恢复执行,否则认为访问吴晓 2) 找到的区域不是栈,异常地址不是位于紧挨着堆栈区的那个区域,同时又没有相应VMA,则进程访问了非法地址,进入bad_area处理,访问无效 */ if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) { bad_area(regs, error_code, address); return; } if (error_code & PF_USER) { /* * Accessing the stack below %sp is always a bug. * The large cushion allows instructions like enter * and pusha to work. ("enter $65535, $31" pushes * 32 pointers and then decrements %sp by 65535.) */ /* * 压栈操作时,操作的地址最大的偏移为65536+32*sizeof(unsigned long), * 该操作由pusha命令触发(老版本中,pusha命令最大只能操作32字节,即 * 同时压栈8个寄存器)。如果访问的地址距栈顶的距离超过了,则肯定是非法 * 地址访问了。 */ if (unlikely(address + 65536 + 32 * sizeof(unsigned long) < regs->sp)) { bad_area(regs, error_code, address); return; } } /* * 运行到这里,说明设置了VM_GROWSDOWN标记,表示缺页异常地址位于堆栈区 * 需要扩展堆栈。需要明白的是,堆栈区的虚拟地址空间也是动态分配和扩展的,不是 * 一开始就分配好的。 */ if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; } /* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ /* * 运行到这里,说明是正常的缺页异常,则进行请求调页,分配物理内存 */ good_area: write = error_code & PF_WRITE; if (unlikely(access_error(error_code, write, vma))) { bad_area_access_error(regs, error_code, address); return; } /* * If for any reason at all we couldn‘t handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault: */ /* * 分配物理内存,缺页异常的正常处理主函数 * 可能的情况有: 1. 请求调页/按需分配 2. COW 3. 缺的页位于交换分区,需要换入 */ /* handle_mm_fault是一个体系结构无关的例程,用于选择适当的异常恢复方法 1. 按需调页 2. 换入 3. .. */ fault = handle_mm_fault(mm, vma, address, write ? FAULT_FLAG_WRITE : 0); if (unlikely(fault & VM_FAULT_ERROR)) { mm_fault_error(regs, error_code, address, fault); return; } //如果页建立成功 if (fault & VM_FAULT_MAJOR) { tsk->maj_flt++; //例程返回PERF_COUNT_SW_PAGE_FAULTS_MAJ: 数据需要从块设备读取 perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, 0, regs, address); } else { tsk->min_flt++; //例程返回PERF_COUNT_SW_PAGE_FAULTS_MIN: 数据已经在内存中 perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, 0, regs, address); } check_v8086_mode(regs, address, tsk); up_read(&mm->mmap_sem); }
Relevant Link:
http://blog.chinaunix.net/uid-14528823-id-4336332.html
11. 用户空间缺页异常的校正
我们之前讨论了对缺页异常的特定于体系结构的代码,确认异常是在允许的地址触发,内核必须确定将所需数据读取到物理内存的释放方法,该任务委托给handle_mm_fault,它不依赖于底层体系结构,而是在内存管理的框架下、独立于系统而实现,该函数确认在各级页目录中,通向对应于异常地址的页表项的各个页目录都存在
handle_pte_fault函数分析缺页异常的原因,pte是指向相关页表项(pte_t)的指针
\linux-2.6.32.63\mm\memory.c
/* * These routines also need to handle stuff like marking pages dirty * and/or accessed for architectures that don‘t do it in hardware (most * RISC architectures). The early dirtying is also good on the i386. * * There is also a hook called "update_mmu_cache()" that architectures * with external mmu caches can use to update those (ie the Sparc or * PowerPC hashed page tables that act as extended TLBs). * * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults), and pte mapped but not yet locked. * We return with mmap_sem still held, but pte unmapped and unlocked. */ static inline int handle_pte_fault( struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *pte, pmd_t *pmd, unsigned int flags ) { pte_t entry; spinlock_t *ptl; entry = *pte; /* 如果页不在物理内存中,即!pte_present(entry),则必须区分下面3种情况 1. 如果没有对应的页表项(page_none),则内核必须从头开始加载该页 1) 对匿名映射称之为按需分配(demand allocation) 2) 对基于文件的映射,称之为按需调页(demand paging) 如果vm_ops中没有注册vm_operations_struct,则不适合用以上2个方法,在这种情况下,内核必须使用do_anonymous_page返回一个匿名页 2. 如果该页标记为不存在,而页表中保存了相关的信息,在这种情况下,内核必须从系统的某个交换区换入(换入/按需调页) 3. 非线性映射已经换出的部分不能像普通页那样换入,因为必须正确地恢复非线性关联,pte_file函数可以检查页表项是否属于非线性映射,do_nonlinear_fault在这种情况下可用于处理异常 */ if (!pte_present(entry)) { if (pte_none(entry)) { if (vma->vm_ops) { if (likely(vma->vm_ops->fault)) return do_linear_fault(mm, vma, address, pte, pmd, flags, entry); } return do_anonymous_page(mm, vma, address, pte, pmd, flags); } if (pte_file(entry)) return do_nonlinear_fault(mm, vma, address, pte, pmd, flags, entry); return do_swap_page(mm, vma, address, pte, pmd, flags, entry); } ptl = pte_lockptr(mm, pmd); spin_lock(ptl); if (unlikely(!pte_same(*pte, entry))) goto unlock; /* 如果该区域对页授予了写权限,而硬件的存取机制没有授予(因此触发异常),则会发生另一种潜在的情况,但此时对应的页已经在内存中 */ if (flags & FAULT_FLAG_WRITE) { if (!pte_write(entry)) /* do_wp_page负责创建该页的副本,并插入到进程的页表中(在硬件层具备写权限),该机制称为写时复制(copy on write COW) 在进程发生分支时(fork),页并不是立即复制的,而是映射到进程的地址空间中作为"只读"副本,以免在复制信息时花费太多时间 在实际发生写访问之前,都不会为进程创建页的独立副本 */ return do_wp_page(mm, vma, address, pte, pmd, ptl, entry); entry = pte_mkdirty(entry); } entry = pte_mkyoung(entry); if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) { update_mmu_cache(vma, address, entry); } else { /* * This is needed only for protection faults but the arch code * is not yet telling us if this is a protection fault or not. * This still avoids useless tlb flushes for .text page faults * with threads. */ if (flags & FAULT_FLAG_WRITE) flush_tlb_page(vma, address); } unlock: pte_unmap_unlock(pte, ptl); return 0; }
我们接下来分别讨论handle_pte_fault中针对不同缺页校正方式的处理
0x1: 按需分配/调页
按需分配的工位委托给了do_linear_fault
\linux-2.6.32.63\mm\memory.c
static inline int handle_pte_fault( struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *pte, pmd_t *pmd, unsigned int flags ) { .. /* 首先,内核必须确保将所需的数据读入到发生异常的页,具体的处理依赖于映射到发生异常的地址空间中的文件,因此需要调用特定于文件的方法来获取数据 1. 通常该方法保存在vma->vm_ops->fault 2. 由于较早的内核版本使用的方法调用约定不同,内核必须考虑到某些代码尚未更新到新的调用约定,因此如果没有注册fault方法,则调用旧的vm->vm_ops->nopage */ if (vma->vm_ops) { if (likely(vma->vm_ops->fault)) return do_linear_fault(mm, vma, address, pte, pmd, flags, entry); } .. } static int do_linear_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *page_table, pmd_t *pmd, unsigned int flags, pte_t orig_pte) { pgoff_t pgoff = (((address & PAGE_MASK) - vma->vm_start) >> PAGE_SHIFT) + vma->vm_pgoff; pte_unmap(page_table); return __do_fault(mm, vma, address, pmd, pgoff, flags, orig_pte); }
大多数文件都使用filemap_fault读入所需数据,该函数不仅读入所需数据,还实现了预读功能,即提前读入在未来很可能需要的页(..)。总之,我们要重点记住的是,内核使用address_space对象中的信息,从后备存储器读取到物理内存页

给定涉及区域的vm_area_strcut,内核将选择使用何种方法读取页
1. 使用vm_area_struct->vm_file找到映射的file对象 2. 在file->f_mapping中找到指向映射自身的指针 3. 每个地址空间都有特定的地址空间操作,从中选择readpage方法,使用mapping->a_ops->readpage(file, page)从文件中将数据传输到物理内存
如果需要写访问,内核必须区分共享和私有映射,对私有映射,必须准备页的一份副本
/* * __do_fault() tries to create a new page mapping. It aggressively * tries to share with existing pages, but makes a separate copy if * the FAULT_FLAG_WRITE is set in the flags parameter in order to avoid * the next page fault. * * As this is called only for pages that do not currently exist, we * do not need to flush old virtual caches or the TLB. * * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults), and pte neither mapped nor locked. * We return with mmap_sem still held, but pte unmapped and unlocked. */ static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pmd_t *pmd, pgoff_t pgoff, unsigned int flags, pte_t orig_pte) { pte_t *page_table; spinlock_t *ptl; struct page *page; pte_t entry; int anon = 0; int charged = 0; struct page *dirty_page = NULL; struct vm_fault vmf; int ret; int page_mkwrite = 0; vmf.virtual_address = (void __user *)(address & PAGE_MASK); vmf.pgoff = pgoff; vmf.flags = flags; vmf.page = NULL; ret = vma->vm_ops->fault(vma, &vmf); if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE))) return ret; if (unlikely(PageHWPoison(vmf.page))) { if (ret & VM_FAULT_LOCKED) unlock_page(vmf.page); return VM_FAULT_HWPOISON; } /* * For consistency in subsequent calls, make the faulted page always * locked. */ if (unlikely(!(ret & VM_FAULT_LOCKED))) lock_page(vmf.page); else VM_BUG_ON(!PageLocked(vmf.page)); /* * Should we do an early C-O-W break? 应该进行写时复制吗 */ page = vmf.page; if (flags & FAULT_FLAG_WRITE) { if (!(vma->vm_flags & VM_SHARED)) { anon = 1; /* 在用anon_vma_prepare(指向原区域的指针,在anon_vma_prepare中会重定向到新的区域)为区域建立一个新的anon_vma实例之后,必须分配一个新的页 这里会优先使用高端内存域,因为该内存域对用户空间页是没有问题的 */ if (unlikely(anon_vma_prepare(vma))) { ret = VM_FAULT_OOM; goto out; } page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!page) { ret = VM_FAULT_OOM; goto out; } if (mem_cgroup_newpage_charge(page, mm, GFP_KERNEL)) { ret = VM_FAULT_OOM; page_cache_release(page); goto out; } charged = 1; /* * Don‘t let another task, with possibly unlocked vma, * keep the mlocked page. */ if (vma->vm_flags & VM_LOCKED) clear_page_mlock(vmf.page); //copy_user_highpage接下来创建数据的一份副本 copy_user_highpage(page, vmf.page, address, vma); __SetPageUptodate(page); } else { /* * If the page will be shareable, see if the backing * address space wants to know that the page is about * to become writable */ if (vma->vm_ops->page_mkwrite) { int tmp; unlock_page(page); vmf.flags = FAULT_FLAG_WRITE|FAULT_FLAG_MKWRITE; tmp = vma->vm_ops->page_mkwrite(vma, &vmf); if (unlikely(tmp & (VM_FAULT_ERROR | VM_FAULT_NOPAGE))) { ret = tmp; goto unwritable_page; } if (unlikely(!(tmp & VM_FAULT_LOCKED))) { lock_page(page); if (!page->mapping) { ret = 0; /* retry the fault */ unlock_page(page); goto unwritable_page; } } else VM_BUG_ON(!PageLocked(page)); page_mkwrite = 1; } } } page_table = pte_offset_map_lock(mm, pmd, address, &ptl); /* * This silly early PAGE_DIRTY setting removes a race * due to the bad i386 page protection. But it‘s valid * for other architectures too. * * Note that if FAULT_FLAG_WRITE is set, we either now have * an exclusive copy of the page, or this is a shared mapping, * so we can make it writable and dirty to avoid having to * handle that later. */ /* Only go through if we didn‘t race with anybody else... */ if (likely(pte_same(*page_table, orig_pte))) { /* 在知道了页的位置之后,需要将其加入进程的页表,再合并到逆向映射数据结构中 在完成这些之前,需要用flush_icache_page更新缓存,确保页的内容在用户空间可见 */ flush_icache_page(vma, page); //指向只读页的页表项通常使用mk_pte函数产生 entry = mk_pte(page, vma->vm_page_prot); if (flags & FAULT_FLAG_WRITE) //如果建立具有写权限的页,内核必须用pte_mkdirty显示设置写权限 entry = maybe_mkwrite(pte_mkdirty(entry), vma); /* 页集成到逆向映射的具体方式,取决于其类型 1. 如果在处理写访问权限时生成的页是匿名的,则用page_add_new_anon_rmap集成到逆向映射中 2. 所有其他与基于文件的映射关联的页,则调用page_add_file_rmap */ if (anon) { inc_mm_counter(mm, anon_rss); page_add_new_anon_rmap(page, vma, address); } else { inc_mm_counter(mm, file_rss); page_add_file_rmap(page); if (flags & FAULT_FLAG_WRITE) { dirty_page = page; get_page(dirty_page); } } set_pte_at(mm, address, page_table, entry); /* no need to invalidate: a not-present page won‘t be cached 最后,必须更新处理器的MMU缓存,因为页表已经修改 */ update_mmu_cache(vma, address, entry); } else { if (charged) mem_cgroup_uncharge_page(page); if (anon) page_cache_release(page); else anon = 1; /* no anon but release faulted_page */ } pte_unmap_unlock(page_table, ptl); out: if (dirty_page) { struct address_space *mapping = page->mapping; if (set_page_dirty(dirty_page)) page_mkwrite = 1; unlock_page(dirty_page); put_page(dirty_page); if (page_mkwrite && mapping) { /* * Some device drivers do not set page.mapping but still * dirty their pages */ balance_dirty_pages_ratelimited(mapping); } /* file_update_time outside page_lock */ if (vma->vm_file) file_update_time(vma->vm_file); } else { unlock_page(vmf.page); if (anon) page_cache_release(vmf.page); } return ret; unwritable_page: page_cache_release(page); return ret; }
0x2: 匿名页
对于没有关联到文件作为后备存储器的页,需要调用do_anonymous_page进行映射,除了无需向页读入数据之外,该过程几乎与映射基于文件的数据没有什么区别,在highmem内存域建立一个新页,并清空其内容,接下来将页加入到进程的页表并更新高速缓存或者MMU
0x3: 写时复制
写时复制在do_wp_page中处理
\linux-2.6.32.63\mm\memory.c

/* * This routine handles present pages, when users try to write * to a shared page. It is done by copying the page to a new address * and decrementing the shared-page counter for the old page. * * Note that this routine assumes that the protection checks have been * done by the caller (the low-level page fault routine in most cases). * Thus we can safely just mark it writable once we‘ve done any necessary * COW. * * We also mark the page dirty at this point even though the page will * change only once the write actually happens. This avoids a few races, * and potentially makes it more efficient. * * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults), with pte both mapped and locked. * We return with mmap_sem still held, but pte unmapped and unlocked. 写时复制 这个函数处理present pages, 当用户试图写共享页面时。 它复制内容到新页,减少旧页面的共享计数 */ static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *page_table, pmd_t *pmd, spinlock_t *ptl, pte_t orig_pte) { struct page *old_page, *new_page; pte_t entry; int reuse = 0, ret = 0; int page_mkwrite = 0; struct page *dirty_page = NULL; /* 内核首先调用vm_normal_page,通过页表项找到页的struct page实例,本质上这个函数基于 1. pte_pfn: 查找与页表项相关的页号 2. pfn_to_page: 确定与页号相关的page实例 这两个函数是所有体系结构都必须定义的,需要明白的是,写时复制机制只对内存中实际存在的页调用,否则首先需要通过缺页异常机制自动加载 */ old_page = vm_normal_page(vma, address, orig_pte); if (!old_page) { /* * VM_MIXEDMAP !pfn_valid() case * * We should not cow pages in a shared writeable mapping. * Just mark the pages writable as we can‘t do any dirty * accounting on raw pfn maps. */ if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) == (VM_WRITE|VM_SHARED)) goto reuse; goto gotten; } /* * Take out anonymous pages first, anonymous shared vmas are * not dirty accountable. */ if (PageAnon(old_page) && !PageKsm(old_page)) { if (!trylock_page(old_page)) { //在page_cache_get获取页之后,接下来 page_cache_get(old_page); pte_unmap_unlock(page_table, ptl); lock_page(old_page); page_table = pte_offset_map_lock(mm, pmd, address, &ptl); if (!pte_same(*page_table, orig_pte)) { unlock_page(old_page); page_cache_release(old_page); goto unlock; } page_cache_release(old_page); } reuse = reuse_swap_page(old_page); unlock_page(old_page); } else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) == (VM_WRITE|VM_SHARED))) { /* * Only catch write-faults on shared writable pages, * read-only shared pages can get COWed by * get_user_pages(.write=1, .force=1). */ if (vma->vm_ops && vma->vm_ops->page_mkwrite) { struct vm_fault vmf; int tmp; vmf.virtual_address = (void __user *)(address & PAGE_MASK); vmf.pgoff = old_page->index; vmf.flags = FAULT_FLAG_WRITE|FAULT_FLAG_MKWRITE; vmf.page = old_page; /* * Notify the address space that the page is about to * become writable so that it can prohibit this or wait * for the page to get into an appropriate state. * * We do this without the lock held, so that it can * sleep if it needs to. */ page_cache_get(old_page); pte_unmap_unlock(page_table, ptl); tmp = vma->vm_ops->page_mkwrite(vma, &vmf); if (unlikely(tmp & (VM_FAULT_ERROR | VM_FAULT_NOPAGE))) { ret = tmp; goto unwritable_page; } if (unlikely(!(tmp & VM_FAULT_LOCKED))) { lock_page(old_page); if (!old_page->mapping) { ret = 0; /* retry the fault */ unlock_page(old_page); goto unwritable_page; } } else VM_BUG_ON(!PageLocked(old_page)); /* * Since we dropped the lock we need to revalidate * the PTE as someone else may have changed it. If * they did, we just return, as we can count on the * MMU to tell us if they didn‘t also make it writable. */ page_table = pte_offset_map_lock(mm, pmd, address, &ptl); if (!pte_same(*page_table, orig_pte)) { unlock_page(old_page); page_cache_release(old_page); goto unlock; } page_mkwrite = 1; } dirty_page = old_page; get_page(dirty_page); reuse = 1; } if (reuse) { reuse: flush_cache_page(vma, address, pte_pfn(orig_pte)); entry = pte_mkyoung(orig_pte); entry = maybe_mkwrite(pte_mkdirty(entry), vma); if (ptep_set_access_flags(vma, address, page_table, entry,1)) update_mmu_cache(vma, address, entry); ret |= VM_FAULT_WRITE; goto unlock; } /* * Ok, we need to copy. Oh, well.. 在用page_cache_get获取页之后,接下来anon_vma_prepare准备好逆向映射机制的数据结构,以接受一个新的匿名区域 */ page_cache_get(old_page); gotten: pte_unmap_unlock(page_table, ptl); if (unlikely(anon_vma_prepare(vma))) goto oom; if (is_zero_pfn(pte_pfn(orig_pte))) { new_page = alloc_zeroed_user_highpage_movable(vma, address); if (!new_page) goto oom; } else { //由于异常的来源是需要将一个充满有用数据的页复制到新页,因此内核调用alloc_page_vma分配一个新野 new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!new_page) goto oom; //cow_user_page接下来将异常页的数据复制到新页,进程随后可以对新页进行写操作 cow_user_page(new_page, old_page, address, vma); } __SetPageUptodate(new_page); /* * Don‘t let another task, with possibly unlocked vma, * keep the mlocked page. */ if ((vma->vm_flags & VM_LOCKED) && old_page) { lock_page(old_page); /* for LRU manipulation */ clear_page_mlock(old_page); unlock_page(old_page); } if (mem_cgroup_newpage_charge(new_page, mm, GFP_KERNEL)) goto oom_free_new; /* * Re-check the pte - we dropped the lock */ page_table = pte_offset_map_lock(mm, pmd, address, &ptl); if (likely(pte_same(*page_table, orig_pte))) { if (old_page) { if (!PageAnon(old_page)) { dec_mm_counter(mm, file_rss); inc_mm_counter(mm, anon_rss); } } else inc_mm_counter(mm, anon_rss); flush_cache_page(vma, address, pte_pfn(orig_pte)); entry = mk_pte(new_page, vma->vm_page_prot); entry = maybe_mkwrite(pte_mkdirty(entry), vma); /* * Clear the pte entry and flush it first, before updating the * pte with the new entry. This will avoid a race condition * seen in the presence of one thread doing SMC and another * thread doing COW. */ ptep_clear_flush(vma, address, page_table); //通过page_add_new_anon_rmap将新页插入到逆向映射数据结构,此后。用户空间进程可以向页写入数据 page_add_new_anon_rmap(new_page, vma, address); /* * We call the notify macro here because, when using secondary * mmu page tables (such as kvm shadow page tables), we want the * new page to be mapped directly into the secondary page table. */ set_pte_at_notify(mm, address, page_table, entry); update_mmu_cache(vma, address, entry); if (old_page) { /* * Only after switching the pte to the new page may * we remove the mapcount here. Otherwise another * process may come and find the rmap count decremented * before the pte is switched to the new page, and * "reuse" the old page writing into it while our pte * here still points into it and can be read by other * threads. * * The critical issue is to order this * page_remove_rmap with the ptp_clear_flush above. * Those stores are ordered by (if nothing else,) * the barrier present in the atomic_add_negative * in page_remove_rmap. * * Then the TLB flush in ptep_clear_flush ensures that * no process can access the old page before the * decremented mapcount is visible. And the old page * cannot be reused until after the decremented * mapcount is visible. So transitively, TLBs to * old page will be flushed before it can be reused. */ //使用page_remove_rmap删除到原来的只读页的逆向映射(fork出的子进程和父进程的页映射完全分离开来),新页添加到页表,此时也必须更新CPU高速缓存 page_remove_rmap(old_page); } /* Free the old page.. */ new_page = old_page; ret |= VM_FAULT_WRITE; } else mem_cgroup_uncharge_page(new_page); if (new_page) page_cache_release(new_page); if (old_page) page_cache_release(old_page); unlock: pte_unmap_unlock(page_table, ptl); if (dirty_page) { /* * Yes, Virginia, this is actually required to prevent a race * with clear_page_dirty_for_io() from clearing the page dirty * bit after it clear all dirty ptes, but before a racing * do_wp_page installs a dirty pte. * * do_no_page is protected similarly. */ if (!page_mkwrite) { wait_on_page_locked(dirty_page); set_page_dirty_balance(dirty_page, page_mkwrite); } put_page(dirty_page); if (page_mkwrite) { struct address_space *mapping = dirty_page->mapping; set_page_dirty(dirty_page); unlock_page(dirty_page); page_cache_release(dirty_page); if (mapping) { /* * Some device drivers do not set page.mapping * but still dirty their pages */ balance_dirty_pages_ratelimited(mapping); } } /* file_update_time outside page_lock */ if (vma->vm_file) file_update_time(vma->vm_file); } return ret; oom_free_new: page_cache_release(new_page); oom: if (old_page) { if (page_mkwrite) { unlock_page(old_page); page_cache_release(old_page); } page_cache_release(old_page); } return VM_FAULT_OOM; unwritable_page: page_cache_release(old_page); return ret; }
0x4: 获取非线性映射
与按需调页/写时复制相比,非线性映射的缺页处理要短得多
/* * Fault of a previously existing named mapping. Repopulate the pte * from the encoded file_pte if possible. This enables swappable * nonlinear vmas. * * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults), and pte mapped but not yet locked. * We return with mmap_sem still held, but pte unmapped and unlocked. */ static int do_nonlinear_fault( struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *page_table, pmd_t *pmd, unsigned int flags, pte_t orig_pte ) { pgoff_t pgoff; flags |= FAULT_FLAG_NONLINEAR; if (!pte_unmap_same(mm, pmd, page_table, orig_pte)) return 0; if (unlikely(!(vma->vm_flags & VM_NONLINEAR))) { /* * Page table corrupted: show pte and kill process. */ print_bad_pte(vma, address, orig_pte, NULL); return VM_FAULT_SIGBUS; } /* 由于异常地址与映射文件的内容并非线性相关,因此必须从先前用pfoff_to_pte编码的页表项中,获取所需位置的信息。现在就需要获取并使用该信息 pte_to_pgoff分析页表项并获取所需的文件中的偏移量(以页为单位) */ pgoff = pte_to_pgoff(orig_pte); //在获得了文件内部的地址之后,读取所需数据类似于普通的缺页异常,因此内核将工作移交给__do_fault,处理到此为止 return __do_fault(mm, vma, address, pmd, pgoff, flags, orig_pte); }
12. 内核缺页异常
在访问内核地址空间时,缺页异常可能被各种条件触发,例如
1. 内核中的程序设计错误导致访问不正确的地址,这是真正的程序错误 2. 内核通过用户空间传递的系统调用参数,访问了无效地址 //前两种情况是真正的错误,内核必须对此进行额外的检查 3. 访问使用vmalloc分配的区域,触发缺页异常 //vmalloc的情况是导致缺页异常的合理原因,必须加以校正,直至对应的缺页异常发生之前,vmalloc区域中的修改都不会传递到进程的页表,必须从主页表复制适当的访问权限信息
在处理不是由于访问vmalloc区域导致的缺页异常时,异常修正(exception fixup)机制是一个最后手段,在某些时候,内核有很好的理由准备截取不正确的访问,例如从用户空间地址复制作为系统调用参数的地址数据时
复制可能由各种函数执行,例如copy_from_user,在向或从用户空间复制数据时,如果访问的地址在虚拟地址空间中不与物理内存页关联,则会发生缺页异常,对用户态发生的该情况,我们已经在上文讨论过了(在应用程序访问一个虚拟地址时,内核将使用按需调页机制,自动并透明地返回一个物理内存页)。如果访问发生在和心态,异常同样必须校正,但使用的方法稍有不同
每次发生缺页异常时,将输出异常的原因和当前执行代码的地址,这使得内核可以编译一个列表,列出所有可能执行未授权内存访问操作的危险代码,这个"异常表"在链接内核映像时创建,在二进制文件中位于__start_exception_table、__end_exception_table之间,每个表项对应于一个struct exception_table实例,该结构尽管是体系结构相关的,但通常是如下定义
\linux-2.6.32.63\include\asm-generic\uaccess.h
/* * The exception table consists of pairs of addresses: the first is the * address of an instruction that is allowed to fault, and the second is * the address at which the program should continue. No registers are * modified, so it is entirely up to the continuation code to figure out * what to do. * * All the routines below use bits of fixup code that are out of line * with the main instruction path. This means when everything is well, * we don‘t even have to jump over them. Further, they do not intrude * on our cache or tlb entries. */ struct exception_table_entry { //insn指定了内核预期在虚拟地址空间中发生异常的位置 unsigned long insn; //fixup指定了发生异常时执行恢复到哪个代码地址 unsigned long fixup; };
fixup_exception用于搜索异常表,在IA-32系统上如下定义
\linux-2.6.32.63\arch\x86\mm\extable.c
int fixup_exception(struct pt_regs *regs) { const struct exception_table_entry *fixup; #ifdef CONFIG_PNPBIOS if (unlikely(SEGMENT_IS_PNP_CODE(regs->cs))) { extern u32 pnp_bios_fault_eip, pnp_bios_fault_esp; extern u32 pnp_bios_is_utter_crap; pnp_bios_is_utter_crap = 1; printk(KERN_CRIT "PNPBIOS fault.. attempting recovery.\n"); __asm__ volatile( "movl %0, %%esp\n\t" "jmp *%1\n\t" : : "g" (pnp_bios_fault_esp), "g" (pnp_bios_fault_eip)); panic("do_trap: can‘t hit this"); } #endif //search_exception_tables扫描异常表,查找适当的匹配项 fixup = search_exception_tables(regs->ip); if (fixup) { /* If fixup is less than 16, it means uaccess error */ if (fixup->fixup < 16) { current_thread_info()->uaccess_err = -EFAULT; regs->ip += fixup->fixup; return 1; } //regs->ip指向EIP寄存器,在IA-32处理器上是包含了触发异常的代码段地址 regs->ip = fixup->fixup; //在找到修正例程后,将CPU指令指针设置到对应的内存地址,在fixup_exception通过return返回后,内核将执行找到的例程 return 1; } return 0; }
如果没有修正例程,这表明出现了一个真正的内核异常,在对search_exception_tables(不成功的)调用之后,将调用do_page_fault来处理该异常,最终导致内核进入oops状态
13. 在内核和用户空间之间复制数据
内核经常需要从用户空间向内核空间复制数据,例如,在系统调用中通过指针间接地传递了冗长的数据结构时,反过来,也有从内核空间向用户空间写数据的需要。要注意的是,有两个原因,使得不能只是传递并反引用指针
1. 用户空间程序不能访问内核地址 2. 无法保证用户空间中指针指向的虚拟内存页确实与物理内存页关联
因此,内核需要提供几个标准函数,以处理内核空间和用户空间之间的数据交换
1. unsigned long copy_to_user(void __user *to, const void *from, unsigned long n) 从from(用户空间)到to(内核空间)复制一个长度为n字节的字符串 2. get_user (type *to, type* ptr); 从ptr读取一个简单类型变量(char、long、...),写入to,根据指针的类型,内核自动判断需要传输的字节数 3. long strncpy_from_user ( char *dst, const char __user * src, long count); 将0结尾字符串(最长为n个字符)从from(用户空间)复制到to(内核空间) 4. put_user (type *from, type* to); 将一个简单值从from(内核空间)复制到to(用户空间),相应的值根据指针类型自动判断 5. unsigned long copy_to_user ( void __user * to, const void *from, unsigned long n); 从from(内核空间)到to(用户空间)复制一个长度为n字节的字符串 6. unsigned long clear_user ( void __user *to, unsigned long n); 用0填充to之后的n个字节 7. strlen_user ( str ); 获取用户空间中的一个0结尾字符串的长度(包括结束字符) 8. long strnlen_user ( const char __user * s, long n); 获取一个0结尾的字符串长度,但搜索限制为不超过n个字符 /* get_user、put_user函数只能正确处理指向简单数据类型的指针,如char、int等等。它们不支持复合数据类型或数组,因为需要指针运算(和实现优化方面的必要性),在用户空间和内核空间之间能够交换struct之前,复制数据后,必须通过类型转换,转为正确的类型 */
这些函数主要使用汇编语言实现的,由于调用非常频繁,对性能要求极高,另外还必须使用GNU C用于嵌入汇编的复杂构造和代码中的链接指令
在新版本的内核中,编译过程增加了一个检查工具,该工具分析源代码,检查用户空间的指针是否能直接反引用,源自用户空间的指针必须用关键字__user标记,以便工具分辨所需检查的指针
Relevant Link:
《深入Linux内核架构》
Copyright (c) 2015 LittleHann All rights reserved
标签:
原文地址:http://www.cnblogs.com/LittleHann/p/4399236.html