标签:
最近研究了一下最近公共祖先算法,根据效率和实现方式不同可以分为基本算法、在线算法和离线算法。下面将结合hihocoder上的题目分别讲解这三种算法。
1、基本算法
对于最近公共祖先问题,最容易想到的算法就是从根开始遍历到两个查询的节点,然后记录下这两条路径,两条路径中距离根节点最远的节点就是所要求的公共祖先。
题目参见 #1062 : 最近公共祖先·一
附上AC代码,由于记录的方式采取的是儿子对应父亲,所以实现的时候有点小技巧,就是对第一个节点的路径进行标记,查找第二个节点的路径时一旦发现访问到第一个被标记的节点,即为公共祖先。时间复杂度为QlogN,Q为查询的次数。
#include <stdio.h> #include <stdlib.h> #include <string> #include <vector> #include <iostream> #include <map> using namespace std; map<string, string> sonToFather;//record son and it‘s father map<string, int> visit;//record the visited node void findAnscetor(string str1, string str2){ visit.clear(); map<string, int> visit; string ans = str1; while (!ans.empty()){ visit[ans] = 1; ans = sonToFather[ans]; } ans = str2; while (!ans.empty()){ if (visit[ans]){ break; } ans = sonToFather[ans]; } if (ans.empty()){ printf("%d\n", -1); } else{ cout << ans<<endl; } } int main(){ int N; scanf("%d", &N); int step = 0; while (step < N){ step++; string father, son; cin >> father >> son; sonToFather[son] = father; } step = 0; int M; scanf("%d", &M); while (step < M){ step++; string str1, str2; cin >> str1 >> str2; findAnscetor(str1, str2); } system("pause"); return 0; }
2、离线算法
离线算法称为“tarjan”算法,实现思想是以“并查集”+深搜。即首先从根节点开始进行深度搜索,搜索的时候标记每个节点的集合属于自己,当回溯的时候,把每个儿子节点的集合并到父亲节点。回溯是tarjan的核心思想之一。当对某个节点node的子树全部遍历结束后,对这颗子树内的所有节点通过可以通过并查集的并操作,一定是可以保证其集合为node所在的集合,而不会到node的父亲集合(因为node的父亲节点还未进行回溯操作,没有改变node的指向)。先假设需要查询的节点为x和y,如果发现遍历到y的时候,x已经遍历,可以推出,x一定是在y的左边,这时候找到x所在的集合,即为x和y的最近公共祖先。可能说的比较抽象,下面画图说明。
假设要查询A和C节点,当访问到A节点的时候,可以发现C节点已经被访问。此时用并查集的并操作得到C节点的集合为D,由于D还没有回溯到D的父亲,所以对于D的子树都并到了D的集合中。最终可以得到A和C的最近公共祖先为D。
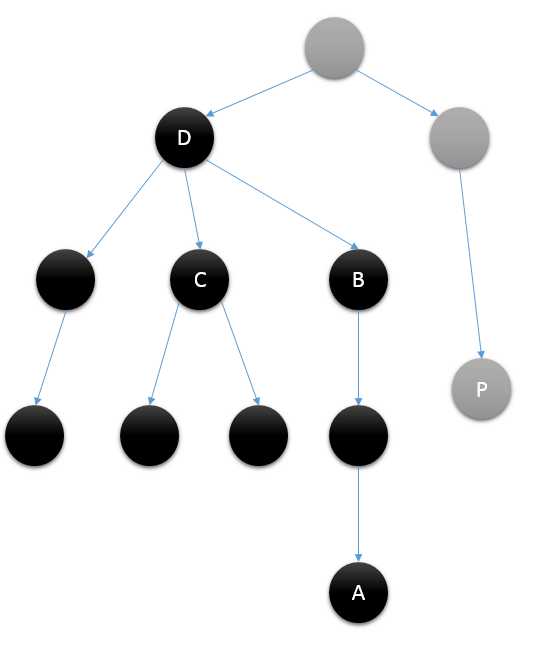
tarjan算法的时间复杂度为O(N+Q),其中Q为查询的次数,比基本算法好,但是需要一次性输入所有的查询数据。下面附上AC代码,题目详见#1067 : 最近公共祖先·二
#include <stdio.h> #include <stdlib.h> #include <string> #include <fstream> #include <map> #include <vector> #include <iostream> using namespace std; const int N = 1e5 + 10; vector<int> vecArray[N];//the map of father and son map<string, int> indexNode;//the index of each node vector<pair<int, int>> indexQuery[N];//the qeury collection int fa[N],result[N]; string Name[N]; int findX(int x){//find and union if (fa[x] == x) return x; else return fa[x] = findX(fa[x]); } void LCA(int u){ fa[u] = u; for (int i = 0; i < vecArray[u].size(); i++){ int v = vecArray[u][i]; LCA(v); fa[v] = u; } for (int j = 0; j < indexQuery[u].size(); j++){ pair<int, int> p = indexQuery[u][j]; if (fa[p.first] != -1){ result[p.second] = findX(p.first); } } } int main(){ #ifdef TYH freopen("in.txt", "r", stdin); #endif // TYH int n; int i, j, k; scanf("%d", &n); int num = 0; //memset(fa, -1, sizeof(fa)); for (i = 0; i < N; i++) fa[i] = -1; indexNode.clear(); for (i = 0; i < n; i++){ string father, son; cin >> father >> son; if (indexNode.count(father)==0){ indexNode[father] = num; Name[num] = father; num++; } if (indexNode.count(son)==0){ indexNode[son] = num; Name[num] = son; num++; } vecArray[indexNode[father]].push_back(indexNode[son]); } int m; scanf("%d", &m); for (i = 0; i < m; i++){ string str1, str2; cin >> str1 >>str2; int index1 = indexNode[str1]; int index2 = indexNode[str2]; indexQuery[index1].push_back(make_pair(index2, i)); indexQuery[index2].push_back(make_pair(index1, i)); } LCA(0); for (i = 0; i < m; i++){ cout << Name[result[i]] << endl; } return 0; }
3、在线算法
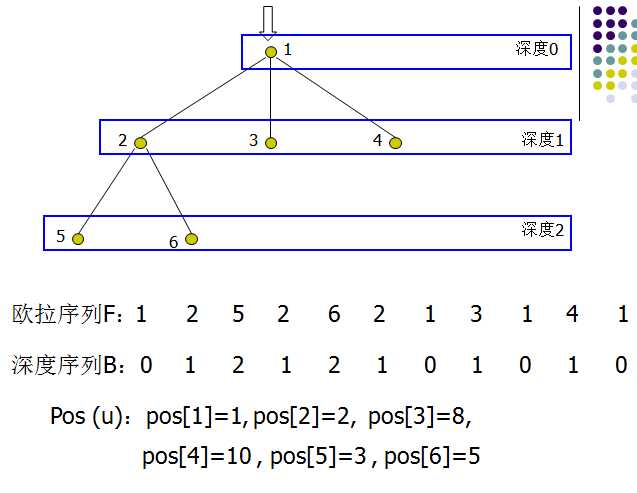
虽然离线算法具有较好的时间复杂度,但由于离线的特性可能在某些场合不适用。在线算法是深搜+RMQ,可以实现O(N)处理数据和O(1)的查询效率。RMQ算法在稍后进行介绍,是用来求某个区间内的最值问题。如果能够把树转换成一个线性数组,然后再应用RMQ算法,就能够实现O(1)的查询。对有根树T进行DFS,将遍历到的结点按照顺序记下,我们将得到一个长度为2N – 1的序列,称之为T的欧拉序列F。每个结点都在欧拉序列中出现,我们记录结点u在欧拉序列中第一次出现的位置为pos(u),如下图所示。
#include <stdio.h> #include <stdlib.h> #include <string> #include <fstream> #include <map> #include <vector> #include <iostream> #include <math.h> using namespace std; const int N = 1e5 + 10; const int M = 30; int arrayData[N]; int rmqData[2*N][M]; vector<int> vecArray[N];//the map of father and son map<string, int> indexNode;//the index of each node int firstNode[N];//the first position of the node string Name[N]; int pos[2 * N],depArray[2*N]; int countNum = -1; int n,m; bool flag[N]; int min(int x, int y){ return (x <y ? x : y); } void Dfs(int u,int dep){ countNum++; if (firstNode[u] == -1){ firstNode[u] = countNum; } depArray[countNum] = dep; pos[countNum] = u; int i = 0; for (i = 0; i < vecArray[u].size(); i++){ if (flag[i] == false){ Dfs(vecArray[u][i], dep + 1); countNum++; pos[countNum] = u; depArray[countNum] = dep; } } } void RMQ(){ int i, j; for (i = 0; i < 2*n-1; i++){ rmqData[i][0] = i;//record the index instead of dep } int m = (int)(log(2 * n) / log(2)); for (j = 1; j <= m; j++){ for (i = 0; i + (1 << j) - 1 <2*n-1; i++){ int x = rmqData[i][j - 1]; int y = rmqData[i + (1 << (j - 1))][j - 1]; if (depArray[x] < depArray[y]) rmqData[i][j] = x; else rmqData[i][j] = y; } } } int main(){ int i, j, k; scanf("%d", &n); m = (log(n*1.0) / log(2.0)); int num = 0; for (i = 0; i < N; i++){ firstNode[i] = -1; flag[i] = false; } indexNode.clear(); for (i = 0; i < n; i++){ string father, son; cin >> father >> son; if (indexNode.count(father) == 0){ indexNode[father] = num; Name[num] = father; num++; } if (indexNode.count(son) == 0){ indexNode[son] = num; Name[num] = son; num++; } vecArray[indexNode[father]].push_back(indexNode[son]); } Dfs(0, 0); RMQ(); int s; scanf("%d", &s); for (i = 0; i < s; i++){ string str1, str2; cin >> str1 >> str2; int l = indexNode[str1]; int r= indexNode[str2]; l = firstNode[l]; r = firstNode[r]; if (l > r){ int temp = l; l = r; r = temp; } int k = 0; while ((1 << (k + 1)) <= (r - l + 1)) k++; int x = rmqData[l][k]; int y=rmqData[r - (1 << k) + 1][k]; if (depArray[x] < depArray[y]){ cout << Name[pos[x]] << endl; } else{ cout<< Name[pos[y]]<<endl; } } return 0; }
标签:
原文地址:http://www.cnblogs.com/JeromeHuang/p/4472693.html