标签:style class blog code java http
最近使用了一个非常简单易用的方法解决了业务上的一个insert吞吐量的问题,在此总结一下。
首先我们明确一下,insert吞吐量其实并不是指的IPS(insert per second),而是指的RPS(effect rows per second)。
其次我们再说一下batch insert,其实顾名思义,就是批量插入。这种优化思想是很基本的,MySQL中最出名的应用就是group commit。
简单的来说,就是将SQL A 变成 SQL B
SQL A : insert into table values ($values); SQL B : insert into table values ($values),($values)...($values);
下面,我们来看看这种异常简单的改动会带来什么样子的变化。
测试环境交代:单id的表结构,10w个int values,本地使用socket连接MySQL server,使用shell单进程测试。
首先,我们看下使用SQL A将10w个int values插入到test表中所需的耗时,耗时1777秒。
real 29m37.090s user 9m11.705s sys 5m0.762s
然后,我们看下使用SQL B(每次insert,插入10 values)将10w个int values插入到test表中所需的耗时,耗时53秒
real 0m53.871s user 0m19.455s sys 0m6.285s
这是整整近33倍的时间提升。这部分性能提升的原因在于以下几点:
1、每次和MySQL server建立连接都需要经过各种初始化、权限认证,语法解析等等多个步骤,需要消耗一定的资源。
2、更新一个values和更新n个values耗时基本一致。(下面对比一下insert 单values核insert 10 values的profile耗时)

单values:
+------------------------------+----------+ | Status | Duration | +------------------------------+----------+ | starting | 0.000056 | | checking permissions | 0.000010 | | Opening tables | 0.000034 | | System lock | 0.000010 | | init | 0.000011 | | update | 0.000061 | | Waiting for query cache lock | 0.000003 | | update | 0.000015 | | end | 0.000003 | | query end | 0.000053 | | closing tables | 0.000009 | | freeing items | 0.000021 | | logging slow query | 0.000002 | | cleaning up | 0.000003 | +------------------------------+----------+
10 values: +------------------------------+----------+ | Status | Duration | +------------------------------+----------+ | starting | 0.000061 | | checking permissions | 0.000008 | | Opening tables | 0.000027 | | System lock | 0.000008 | | init | 0.000012 | | update | 0.000073 | | Waiting for query cache lock | 0.000003 | | update | 0.000010 | | end | 0.000008 | | query end | 0.000053 | | closing tables | 0.000010 | | freeing items | 0.000021 | | logging slow query | 0.000002 | | cleaning up | 0.000003 | +------------------------------+----------+
但是,是否values积攒的越多,效率越高吗? 答案自然是否定的,任何优化方案都不会是纯线性的,肯定会在某个条件下出现拐点。
我们按照不同的values number进行测试,分别为1、10、50、100、200、500、1000、5000、10000.
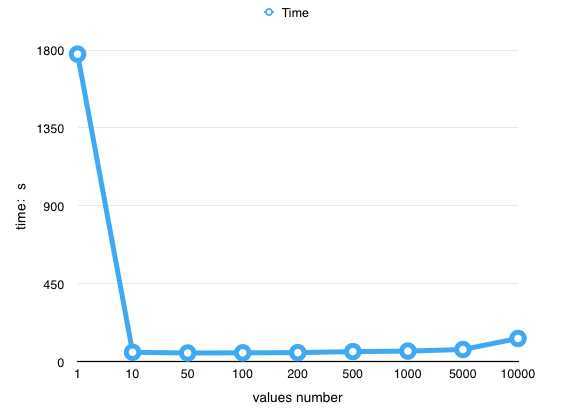
从下图我们可以看出,随着values number的增加,耗时先是急剧下降,从1777s变成53s,然后在增加values number就不会有太大的变化,直到values number超过200,最后的10000个values number耗时达到了2分钟。
从下图我们可以看到随着values numbers的增加,QPS(蓝线)先是猛增,然后下降,最终小于1/s。而RPS(绿线)随着增加猛增到一个高level,然后随着增加逐步下降,超过5000个values number之后开始急剧下降。
另,最关键的是,QPS最高峰和RPS的最高峰并不在同一个values number下,也就是说QPS最高的时候并不代表着insert的吞吐量就最高。
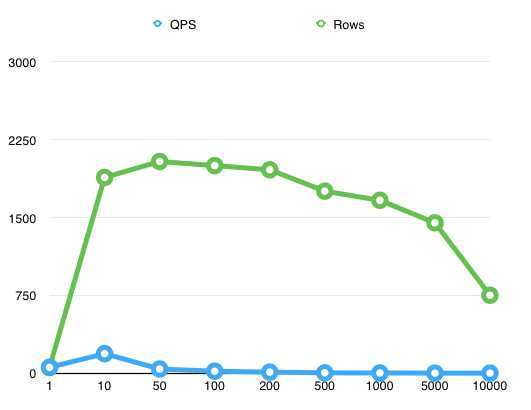
在我这个简单测试场景中,values number最合适的值是50,和单values对比,耗时减少97%,insert吞吐量提升36倍。
而这个值和表结构和字段类型及大小都有关系。需要根据不同的场景进行测试之后才可以得出,但是普遍来说,50-100是比较推荐的考虑值。
至于这个如何实现,只要前端写入的时候加入队列即可,可以按照2个条件进行合并
总结:
1、使用batch insert可以提高insert的吞吐量。
2、叠加的values number需要根据实际情况测试得出。
3、同时使用个数和时间控制阀值。
附简单测试的记录值:
|
ValuesNum |
Time |
QPS |
Rows |
|
1 |
1777 |
56 |
56 |
|
10 |
53 |
188 |
1886 |
|
50 |
49 |
40 |
2040 |
|
100 |
50 |
19 |
2000 |
|
200 |
51 |
10 |
1960 |
|
500 |
57 |
3 |
1754 |
|
1000 |
60 |
2 |
1666 |
|
5000 |
69 |
0.3 |
1449 |
|
10000 |
133 |
0.07 |
751 |
使用batch insert解决MySQL的insert吞吐量问题,布布扣,bubuko.com
使用batch insert解决MySQL的insert吞吐量问题
标签:style class blog code java http
原文地址:http://www.cnblogs.com/billyxp/p/3631242.html