标签:
(1)交叉连接(cross join)即我们所说的笛卡尔积。查询出满足两张表所有的记录数,A(3条记录),B(9条记录),A*B(27条记录)。
比如:雇员表(HR.employees)和货运公司(Sales.shippers)表做一个交叉连接。
1 select * from hr.employees; 2 select * from sales.shippers;
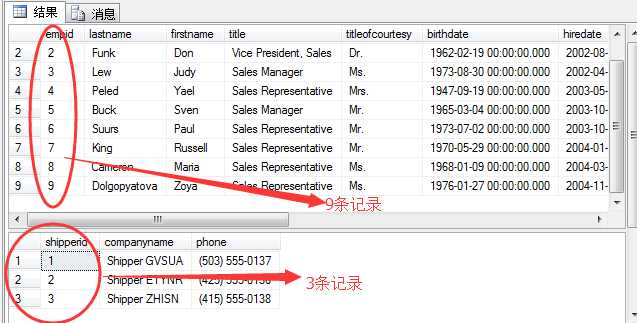
进行交叉连接以后,则找到27条记录。
1 select a.empid,b.shipperid 2 from hr.employees a cross join sales.shippers b;
(2)内连接(inner join),即必须满足某一条件的组合。
例如我们要查询产品类别表下,每种产品属于哪一分类,就需要关联产品分类表(production.categories)和产品明细表做一个inner join。
1 select a.categoryid,a.categoryname,b.productid,b.productname 2 from production.categories a inner join production.products b 3 on a.categoryid=b.categoryid;
结果如图所示:
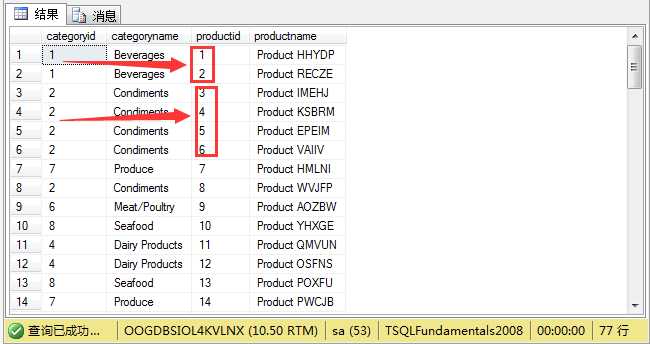
我们可以看到产品1、都属于产品分类1.以此类推.........,这样就可以找出类别1下有哪些产品,以及产品分别属于哪一分类。
在这里我们拓展一下:假若我们要查询有哪些顾客下单了,找出下订单的顾客信息和订单信息,那么就需要关联顾客表(sales.customers)和订单表
(sales.orders)。
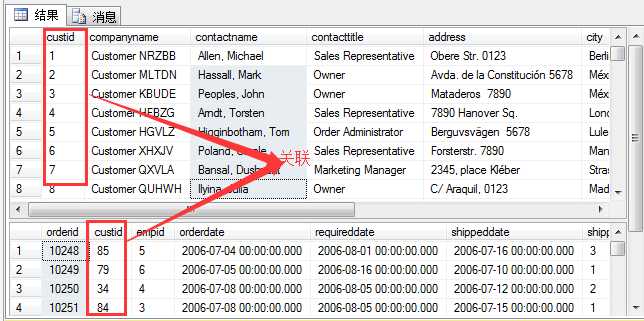
通过查看两张表的字段,我们可以看到两张表可以用custid顾客的ID进行连接。找出相关的顾客信息和订单信息。
1 select a.custid,a.contactname,b.custid,b.orderid 2 from sales.customers a join sales.orders b 3 on a.custid=b.custid
通过内连接(inner join)可以得出一些基本信息,
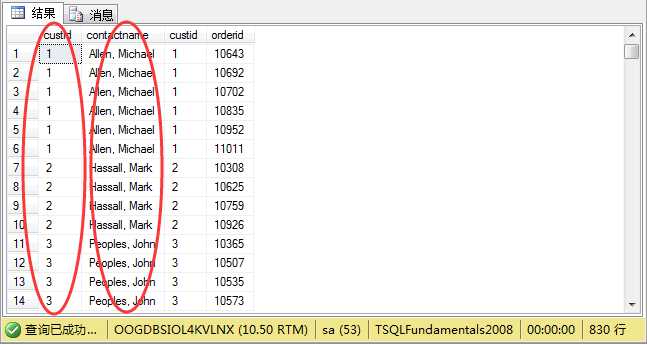
但是这里我们发现一些顾客下过很多订单,加入我们要找出该顾客下过的订单数,并且只显示该顾客的一条记录,那么我们就需要用到之前学到过的
count.....over用法,返回记录数。如要显示不重复的记录,那么我们就可以用关键字distinct进行过滤。

1 select distinct a.custid,a.contactname, 2 count(*) over(partition by a.custid) as N‘顾客订单数量‘ 3 from sales.customers a inner join sales.orders b 4 on a.custid=b.custid
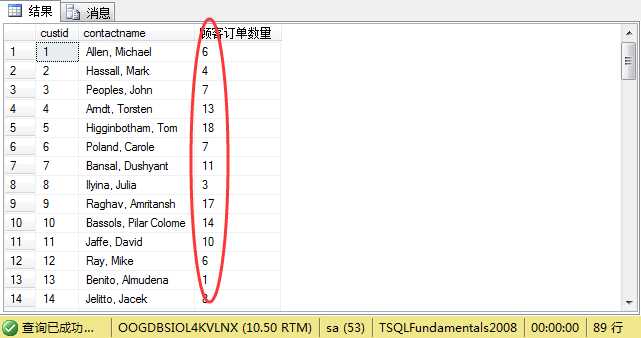
就这样我们可以得出每个顾客的订单数量。其实这里我们还有不用over开窗函数,也能实现同样的统计信息,那就是根据custid进行分组:
1 select a.custid,a.contactname, 2 count(*) as N‘group-by顾客订单数量‘ 3 from sales.customers a inner join sales.orders b 4 on a.custid=b.custid 5 group by a.custid ,a.contactname order by a.custid;
结果如图:
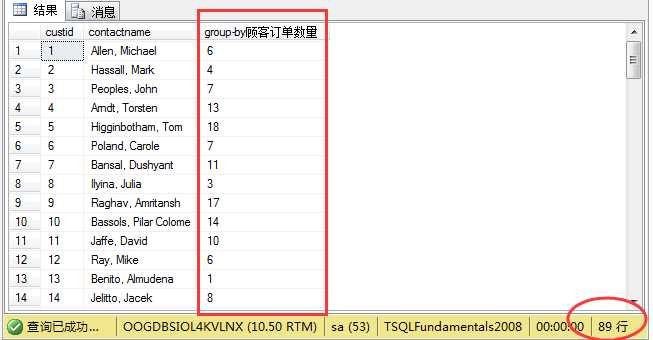
这里我们得出的结果跟上面用count.....over()结果一样。所以在这里选择哪种方式,可以根据需要,视情况而定。
但是这里我们注意一点,我们查询一下顾客表(sales.customers),看看里面的信息。
1 select * from sales.customers
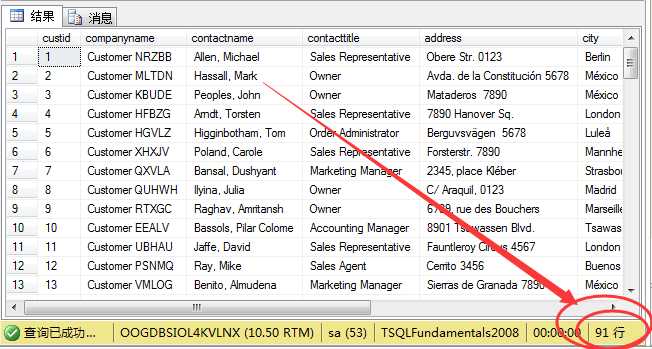
我们可以看到共有91条记录,即有91为顾客光顾过相关订单,根据上面顾客下单信息的89条记录,可以知道,有两位顾客光顾过订单,但却未下单,可以理解,不买看看总行吧!
但是我们却没有看到那两位观望着顾客的信息,怎样才能将那两位观望着找出来,咱们送给他两礼品,感谢他们的支持了?这就需要用到接下来说的连接left join。
(3)left......join ,左连接,即保证左侧条件全部有,右侧没有条件不足,则用null补齐。
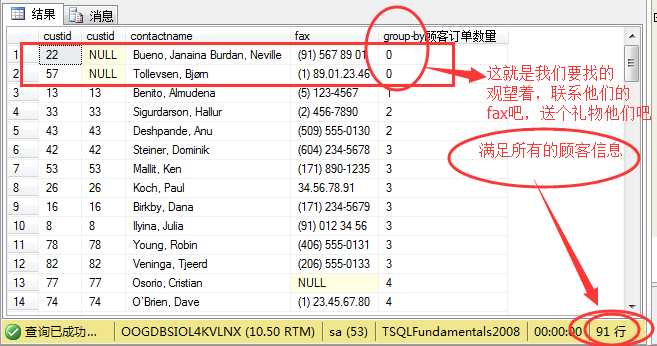
继续上述未完成的任务,即找出没有下订单顾客的信息,也就是订单数量为0的顾客信息,在这里就必须保证所有的顾客信息存在,即用到左连接
(left....join)。
1 select a.custid,b.custid,a.contactname,a.fax, 2 count(b.orderid) as N‘group-by顾客订单数量‘ 3 from sales.customers a left join sales.orders b 4 on a.custid=b.custid 5 group by a.custid ,a.fax,a.contactname,b.custid 6 order by count(b.custid);
结果如图所示:
(4)右连接(right .....join),其实右连接跟左连接相反,以右侧表为基准,保证右侧表满足所有记录,左侧表不足用null补齐。如果交换两个表位置,则就很好
的理解左右连接。
例如:将上述查询用用连接,则查询出来的是,下过订单的所有顾客信息。
1 select a.custid,b.custid,a.contactname,a.fax, 2 count(b.orderid) as N‘顾客订单数量‘ 3 from sales.customers a right join sales.orders b 4 on a.custid=b.custid 5 group by a.custid ,a.fax,a.contactname,b.custid 6 order by count(b.custid);
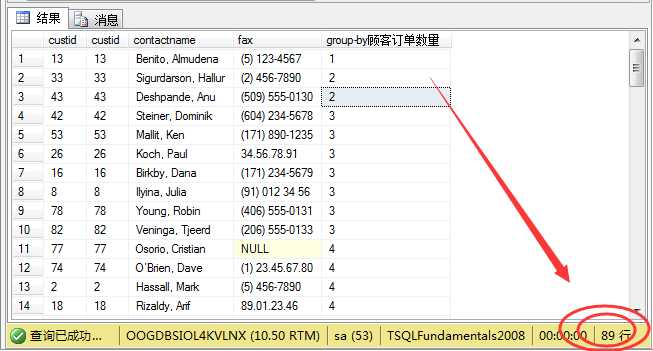
根据上述信息,我们知道下过订单的顾客确实有89人,有两人没有下过订单;但是在这里我们也可以通过右连接找出所有顾客的信息。
1 select a.custid,b.custid,a.contactname,a.fax, 2 count(b.orderid) as N‘顾客订单数量‘ 3 from sales.orders b right join sales.customers a 4 on a.custid=b.custid 5 group by a.custid ,a.fax,a.contactname,b.custid 6 order by count(b.custid);
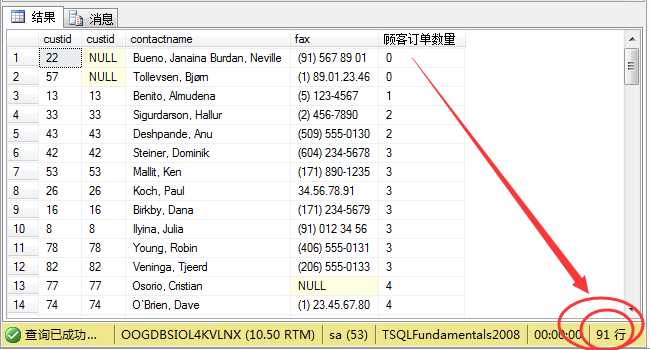
可以看到找出了所有顾客信息,包括未下订单的顾客信息。其实在这里只是交换了两张表的位置而已。
所以说对于左右连接来说,左连接就以左侧表为基准,
右连接就以右表为基准。
SQLServer学习笔记<> 表连接查询----交叉连接、内连接、左连接、右连接
标签:
原文地址:http://www.cnblogs.com/zzt-lovelinlin/p/4479364.html