标签:
PS:上网再次看了一下数据库关于索引的一些细节...感觉自己学的东西有点少...又再次的啃了啃索引....
学习内容:
索引查询优化...
上一章说道的索引还不是特别的详细,再补充一些具体的细节...
1.B-Tree索引...
B-tree结构被称为平衡多路查找树...其数据结构为:
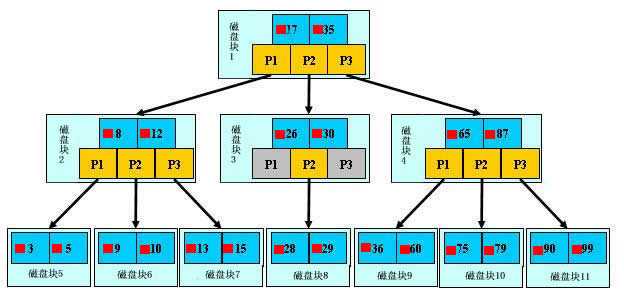
这就是其数据结构图。。。我们没必要完全的理解其中的原理。。并且我也不会做过多的原理介绍。。。我们只需要知道数据库是以这种方式进行存储数据的就可以了...
mysql> create table title -> ( -> id int not null, -> title varchar(255) not null, -> from_date date not null, -> key(id), -> key(title), -> key(from_date) -> ); //建立一个表格。。。有三个主键..。有主键必然要使用到索引... 介绍一下查询方式... 1.全列匹配... mysql>expla select * from title where id=1000 and title=‘gogoing‘ and from_date=‘1992-01-01‘; +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ | 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | | +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+ 2.最左前缀索引... explain select * from title where id=1001; +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+ 最左前缀原则是当索引用到多个列的时候,只有组成最左前缀的部分才能被使用到..上面只用到了第一列... 3.匹配的索引列使用了精确匹配。。。但是中间有部分列没有被给出... explain select * from title where id=1002 and from_date=‘1998-01-01‘; +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where | +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+ 这样只会走第一个索引id,而from_date将不走索引。。由于没有给出title的值,所以无法构成最左前缀原则,因此from_date成为不走索引... 我们可以使用两种方式解决这个问题....使用IN将title的所有值都包括在其中... EXPLAIN SELECT * FROM employees.titles WHERE emp_no=‘1005‘ AND title IN (‘title1的值‘,‘title2的值‘......) AND from_date=‘1986-06-26‘; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 7 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ 这样就不会出现不走索引的情况了...但是如果title的值过多,那么in这种方式就不能使用..因此解决这个问题的另一种方式就是建立辅助索引.... 4.查询的时候没有指定索引的第一列... explain select * from title where from_date=‘1995-01-26‘;//这个结果很明显,就是不走索引... 5.匹配某列前缀的字符串.. explain select * from title where id=1008 and title like ‘S%‘; +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where | +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+ 6.使用范围查询... explain select * from title where id>1010;范围列可以使用索引,但是必须是最左前缀..并且如果同一个查询语句使用了两个范围索引,那么后面的范围将成为不走索引.. explain select * from title where id>1010 and title=‘gogoing‘ and from_date between ‘1990-01-01‘ and ‘1998-01-01‘; 还有一种情况就是如下面代码.. explain select * from where id between 1000 and 1010 and title=‘gogoing‘ and from_date between ‘1998-01-01‘ and ‘2010-01-01‘; 上面这种情况就变成了第一个就成为了多值匹配,而后面那个范围成为了范围匹配...同样都是两个范围匹配,和上面的情况就不同了..这个我至今没弄明白..云里雾里的...如果有大牛会的话请告诉我。。。 7.带有表达式的查询方式... 如果查询语句中含有表达式,那么将成为不走索引。。。(除一些特殊方式)。。。 EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1=‘10000‘; +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where | +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ 不走索引...
2.Hash索引..
MySQL中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引。 Memory存储引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。。
hash索引就是讲我们存储的数据按照一定的哈希函数来进行保存在一个指针数据中,当我们需要查找的时候,调用hash函数,找到我们需要的数据的指针,通过这个指针,我们就可以访问其中的数据信息了..hash的指针数据是有序的,但对应的数据信息是无序的...
Hash索引有以下一些限制:
(1)由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录。但是访问内存中的记录是非常迅速的,不会对性造成太大的影响。
(2)不能使用hash索引排序。
(3)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(4)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询。
3.索引的使用范围...
那么我们到底什么情况下使用索引呢?有两种判断的方式...
i.看了别人的博客说。。一般当我们存储的数据不超过2000条的时候,我们是没有必要使用索引的...
ii.索引的选择性。。。
索引的选择性=表中列的唯一键的数量/表的行数...这个数值越接近于1越好...就比如说主键,毋庸置疑绝对是1..所以有了主键我们必须要使用索引..
上面说到了辅助索引...
4.那么什么是辅助索引呢?简单的介绍一下....
不同的存储引擎对应的辅助索引的结构图也是不同的。。。其实辅助索引和主索引并没有过大的区别,只是主索引要求key值唯一。。辅助索引的key值可以重复....并且二者构成的存储结构也基本相同,都是一棵b+tree。。。每一个数据记录都保存在一个地址当中,这个地址的获取由地址节点的父节点来存储...一层扣一层。。。就形成了树状结构...
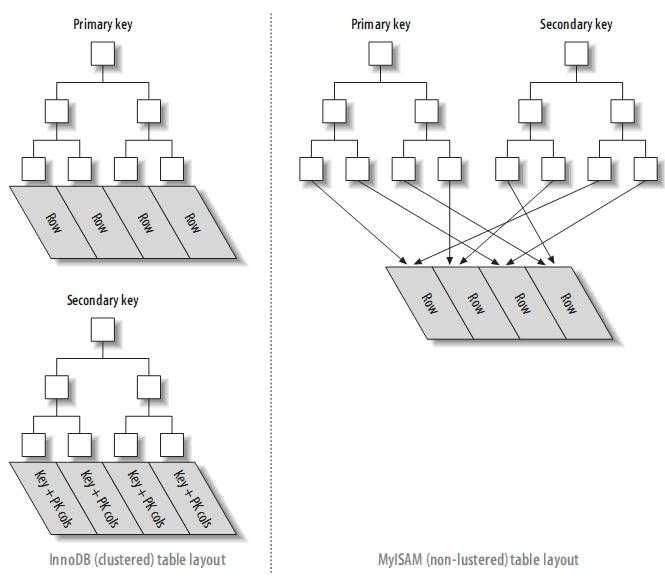
5.聚簇索引..
Innobe存储引擎支持聚簇索引,这种索引方式也是以b+tree为存储结构,但是他和myisam存储引擎完全不同,因为myisam不支持聚簇索引,支持非聚簇索引...
Innobe的数据文件本身就是索引文件..这个b+tree的data数据域完全保存着数据记录,并且也保存着索引的key值,那么当我们找到了key值的时候,我们就可以直接访问数据文件。。。因为数据文件的本身就是主索引...
而myisam存储引擎的数据文件和索引文件是完全分离的,b+tree的data数据域保存着记录数据文件的地址,当我们要通过索引key的值查找数据的时候,我们需要经过找到这个key对应的data数据域的指针值,然后我们通过指针的值去访问我们想要的数据信息...
聚簇索引和非聚簇索引的区别图...Primary key表示主索引...Secondary key表示辅助索引...
6.覆盖索引
简单的介绍一下覆盖索引的有点。。。自己学的也不是特别的透彻,只是做简单的介绍...
如果索引包含满足查询的所有数据,就称为覆盖索引。覆盖索引是一种非常强大的工具,能大大提高查询性能。只需要读取索引而不用读取数据有以下一些优点:
(1)索引项通常比记录要小,所以MySQL访问更少的数据;
(2)索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O;
(3)大多数据引擎能更好的缓存索引。比如MyISAM只缓存索引。
(4)覆盖索引对于InnoDB表尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。
覆盖索引不能是任何索引,只有B-TREE索引存储相应的值。而且不同的存储引擎实现覆盖索引的方式都不同,并不是所有存储引擎都支持覆盖索引(Memory和Falcon就不支持)。
对
于索引覆盖查询(index-covered query),使用EXPLAIN时,可以在Extra一列中看到“Using
index”。
7.利用索引进行排序...
MySQL中,有两种方式生成有序结果集:一是使用filesort,二是按索引顺序扫描。利用索引进行排序操作是非常快的,而且可以利用同一索引同时进 行查找和排序操作。当索引的顺序与ORDER BY中的列顺序相同且所有的列是同一方向(全部升序或者全部降序)时,可以使用索引来排序。如果查询是连接多个表,仅当ORDER BY中的所有列都是第一个表的列时才会使用索引。其它情况都会使用filesort。
create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT ‘‘, password varchar(16) NOT NULL DEFAULT ‘‘, PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values(‘cat01‘,‘1234567‘); insert into actor(name,password) values(‘cat02‘,‘1234567‘); insert into actor(name,password) values(‘ddddd‘,‘1234567‘); insert into actor(name,password) values(‘aaaaa‘,‘1234567‘); mysql> explain select actor_id from actor order by actor_id; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | actor | index | NULL | PRIMARY | 4 | NULL | 4 | Using index | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ mysql> explain select actor_id from actor order by password; +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 4 | Using filesort | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ mysql> explain select actor_id from actor order by name; +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | actor | index | NULL | name | 34 | NULL | 4 | Using index | +----+-------------+-------+-------+---------------+------+---------+------+------+-------------+
标签:
原文地址:http://www.cnblogs.com/RGogoing/p/4474101.html