标签:
uniVocity-parsers 是一个开源的Java项目。 针对CSV/TSV/定宽文本文件的解析,它以简洁的API开发接口提供了丰富而强大的功能。后面会做进一步介绍。
和其他解析库有所不同,uniVocity-parsers以高性能、可扩展为出发点,设计了一套自有架构。基于这套架构,开发者可以构建出新的文件解析器。
1. 概述
作为一名Java开发者,我目前正在参与开发一个Web项目,该项目帮助通信运营商评估当前的网络,并给出解决方案。 在该项目中,CSV文件扮演着至关重要的角色,它是运营商网络数据的承载格式,这些数据包含宽带用户的实时在线状态(在线/离线),及其实时流量。 通常来讲,单个CSV文件可以达到1GB以上,包含上百万条记录。项目当前采用的CSV解析库为JavaCSV。
随着运营商网络规模的扩张,以及系统监控周期的增加,CSV文件迅速变大。 项目组不得不解决超大CSV数据解析所带来的性能问题(甚至包括秒级的解析效率),以及业务变化带来的功能扩展受到限制的问题。
经过很多次的测试和分析,我们最终确定采用uniVocity-parsers作为CSV文件解析库, 实践之后发现它确实解决了我们的问题。除了更好的性能和扩展性之外,该库还为开发者提供了简洁易懂的API、开发文档和教程。 对于高级的功能扩展诉求,官方提供对应的收费服务。
该项目托管在Github上,截至目前,已有69个star和10个fork。你可以在这里和这里找到相关开发文档和教程,也可以在这里找到更多例子和新闻。
值得关注的是,Apache社区知名的开源项目Apache Camel也集成了uniVocity-parsers ,作为该项目解析CSV/TSV/定宽文本文件的推荐库。 更多信息请查看这里。
2. 安装
我们项目组目前在用1.5.1版本, 推荐移步到uniVocity-parsers官方网站下载最新版本。
该项目同时也发发布在了Maven的中心仓库,因此也可以在你的pom.xml中直接添加如下代码:
<dependency> <groupId>com.univocity</groupId> <artifactId>univocity-parsers</artifactId> <version>1.5.1</version> </dependency>
3. 特性简介
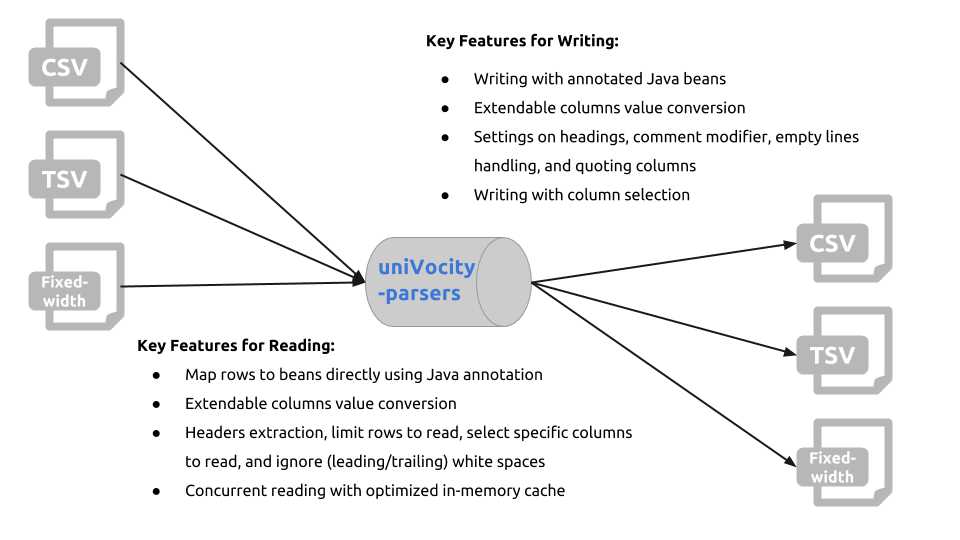
uniVocity-parsers提供了一系列强大的功能,能够很好的满足你所有关于列表式数据的处理需求。如下图表展现了部分关键功能:
4. 读取列表式数据
读取CSV中的所有行
CsvParser parser = new CsvParser(new CsvParserSettings()); List<String[]> allRows = parser.parseAll(getReader("/examples/example.csv"));
如需查看文件写入相关的所有功能,请移步:https://github.com/uniVocity/univocity-parsers#reading-csv
5. 写入列表式数据
仅需2行代码,就可以完成CSV格式数据的写入:
List<String[]> rows = someMethodToCreateRows(); CsvWriter writer = new CsvWriter(outputWriter, new CsvWriterSettings()); writer.writeRowsAndClose(rows);
如需查看文件写入相关的所有功能,请移步: https://github.com/uniVocity/univocity-parsers/blob/master/README.md#writing
6. 性能与扩展性
如下为我们对比 uniVocity-parsers 和 JavaCSV 的测试对比表:
| 文件大小 | JavaCSV解析耗时 | uniVocity-parsers解析耗时 |
| 10MB, 145453 行 | 1138ms | 836ms |
| 100MB, 809008 行 | 23s | 6s |
| 434MB, 4499959 行 | 91s | 28s |
| 1GB, 23803502 行 | 245s | 70s |
在这里可以查看几乎所有CSV解析库的性能对比分析表,从表中可以发现,uniVocity-parsers以绝对优势领先其他库。
uniVocity-parsers在性能和灵活性方面的优势得益于如下设计和机制:
7. 设计与实现
在uniVocity-parsers中,有一些核心的数据处理模块,他们负责对数据按行读写、按列读写,以及行列数据的转换。如下是这些核心模块的关系图:
你可以通过实现 RowProcessor 接口或者继承其实现类来开发自己的数据处理模块。如下代码中,我通过简单的内部匿名类开发了自己的数据处理模块。
CsvParserSettings settings = new CsvParserSettings(); settings.setRowProcessor(new RowProcessor() { StringBuilder stringBuilder = new StringBuilder(); /** * 处理第一行数据之前,你可以根据业务逻辑做相关初始化配置。 **/ @Override public void processStarted(ParsingContext context) { System.out.println("Started to process rows of data."); } /** * 根据你的业务逻辑,处理行数据 **/ @Override public void rowProcessed(String[] row, ParsingContext context) { System.out.println("The row in line #" + context.currentLine() + ": "); for (String col : row) { stringBuilder.append(col).append("\t"); } } /** * 所有行数据处理完成之后,做清理工作。 **/ @Override public void processEnded(ParsingContext context) { System.out.println("Finished processing rows of data."); System.out.println(stringBuilder); } }); CsvParser parser = new CsvParser(settings); List<String[]> allRows = parser.parseAll(new FileReader("/myFile.csv"));
uniVocity-parsers库提供的特性不止这些,由于它在我们的项目中发挥了很大的作用,推荐你进一步了解。
uniVocity-parsers:一款强大的CSV/TSV/定宽文本文件解析库(Java)
标签:
原文地址:http://www.cnblogs.com/xiaoleiy/p/4480667.html