标签:
基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法。
E2LSH中的哈希函数定义如下:
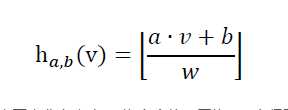
其中,v为d维原始数据,a为随机变量,由正态分布产生; w为宽度值,因为a?v+b得到的是一个实数,如果不加以处理,那么起不到桶的效果,w是E2LSH中最重要的参数,调得过大,数据就被划分到一个桶中去了,过小就起不到局部敏感的效果。b使用均匀分布随机产生,均匀分布的范围在[0,w]。
但是这样,得到的结果是(N1,N2,…,Nk),其中N1,N2,…,Nk在整数域而不是只有0,1两个值,这样的k元组就代表一个桶。但将k元组直接当做桶标号存入哈希表,占用内存且不便于查找,为了方便存储,设计者又将其分层,使用数组+链表的方式。
对每个形式为k元组的桶标号,使用如下h1函数和h2函数计算得到两个值,其中h1的结果是数组中的位置,数组的大小也相当于哈希表的大小,h2的结果值作为k元组的代表,链接到对应数组的h1位置上的链表中。在下面的公式中,r’为[0,prime-1]中依据均匀分布随机产生。
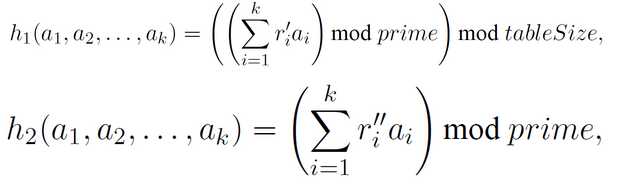
经过如上操作后,查询步骤如下。
对于查询点query,
使用k个哈希函数计算桶标号的k元组;
对k元组计算h1和h2值,
获取哈希表的h1位置的链表,
在链表中查找h2值,
获取h2值位置上存储的样本
Query与上述样本计算精确的相似度,并排序
按照顺序返回结果。
E2LSH方法存在两方面的不足[8]:首先是典型的基于概率模型生成索引编码的结果并不稳定。虽然编码位数增加,但是查询准确率的提高确十分缓慢;其次是需要大量的存储空间,不适合于大规模数据的索引。E2LSH方法的目标是保证查询结果的准确率和查全率,并不关注索引结构需要的存储空间的大小。E2LSH使用多个索引空间以及多次哈希表查询,生成的索引文件的大小是原始数据大小的数十倍甚至数百倍。
部分参考文献:http://dataunion.org/12912.html
E2LSH可以说是分层法基于p-stable distribution的应用。另一种当然是转换成hashcode,则定义哈希函数如下:
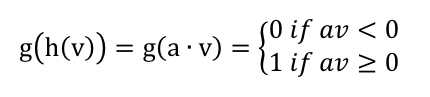
其中,a和v都是d维向量,a由正态分布产生。同上,选择k个上述的哈希函数,得到一个k位的hamming码,按照”哈希技术分类”中描述的技术即可使用该算法。
KP7L6G16E0.png)
标签:
原文地址:http://www.cnblogs.com/hxsyl/p/4481078.html