标签:
一个简单的网页爬虫例子!
html代码:
<head runat="server"> <title>c#爬网</title> </head> <body> <form id="form1" runat="server"> <div style="margin:0 auto;width:700px"> <asp:TextBox ID="txtUrl" runat="server" Width="640"></asp:TextBox> <asp:Button ID="btnStart" runat="server" Text="开始" onclick="btnStart_Click" /><br /><br /> <textarea id="htmlStr" cols="20" rows="2" runat="server" style="width:700px;height:500px"></textarea> </div> </form> </body> </html>
后台代码:
public partial class _Default : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { } protected void btnStart_Click(object sender, EventArgs e) { string url = this.txtUrl.Text.Trim(); if (!string.IsNullOrEmpty(url)) { WebRequest request = WebRequest.Create(url); WebResponse response = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.UTF8); string htmlCode = reader.ReadToEnd();//获取整个页面的源码 //正则,获取<form></form>标签间的内容 Regex reg = new Regex("(?is)<form[^>]*>(?<form>.*?)</form>"); this.htmlStr.Value = reg.Match(htmlCode).Groups["form"].Value; } } }
运行效果:
这里输入url地址是本地的
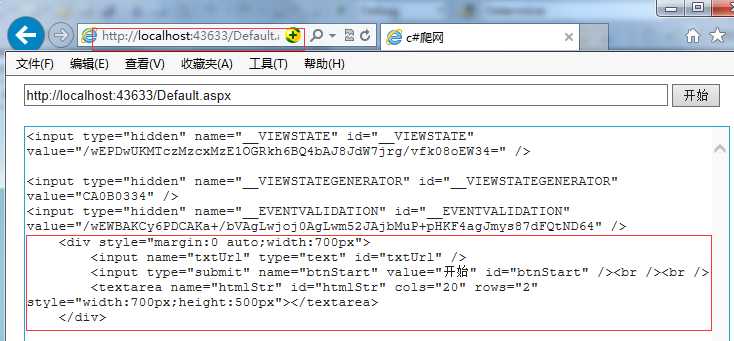
可以看到获取了<form></form>标签间的内容(当然还包括viewstate)。
标签:
原文地址:http://www.cnblogs.com/qk2014/p/4484066.html