标签:
1.本文的目的是练习Web爬虫
目标:
1.爬去糗事百科热门段子
2.去除带图片的段子
3.获取段子的发布时间,发布人,段子内容,点赞数。
2.首先我们确定URL为http://www.qiushibaike.com/hot/page/10(可以随便自行选择),先构造看看能否成功
构造代码:

1 # -*- coding:utf-8 -*- 2 import urllib 3 import urllib2 4 import re 5 6 page = 10 7 url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page) 8 user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ 9 headers = { ‘User-Agent‘ : user_agent } 10 try: 11 request = urllib2.Request(url,headers = headers) 12 response = urllib2.urlopen(request) 13 content = response.read() 14 print content 15 except urllib2.URLError, e: 16 if hasattr(e,"code"): 17 print e.code 18 if hasattr(e,"reason"): 19 print e.reason
成功构造,但是有乱码情况,不用担心,我们只需将:
content = response.read()
替换为
content = response.read().decode(‘UTF-8‘)
3.提取段子前,我们必须,必须分析页面构造
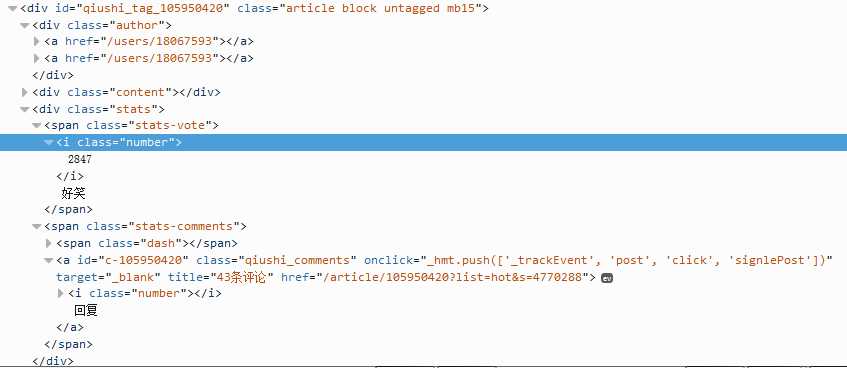
4.好了看看页面的构造,我们可以写正则来匹配,代码入如下:
pattern = re.compile(‘<div.*?class="author.*?>.*?<a.*?</a>.*?<a.*?>(.*?)</a>.*?<div.*?class‘+‘="content".*?>(.*?)</div>(.*?)<div class="stats.*?class="number">(.*?)</i>‘,re.S) items = re.findall(pattern,content) for item in items: haveImg = re.search("img",item[2]) if not haveImg: print item[0],item[1],item[2],item[3]
其中:
(1) .*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配
(2) (.*?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推
(3) re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符
(4) img 是去除匹配的图片标签
通过以上的实验,得到最终的实验代码:
1 # -*- coding:utf-8 -*- 2 import urllib 3 import urllib2 4 import re 5 6 page = 10 7 url = ‘http://www.qiushibaike.com/hot/page/‘ + str(page) 8 user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ 9 headers = { ‘User-Agent‘ : user_agent } 10 try: 11 request = urllib2.Request(url,headers = headers) 12 response = urllib2.urlopen(request) 13 content = response.read().decode(‘utf-8‘) 14 pattern = re.compile(‘<div.*?class="author.*?>.*?<a.*?</a>.*?<a.*?>(.*?)</a>.*?<div.*?class‘+‘="content".*?>(.*?)</div>(.*?)<div class="stats.*?class="number">(.*?)</i>‘,re.S) 15 items = re.findall(pattern,content) 16 for item in items: 17 haveImg = re.search("img",item[2]) 18 if not haveImg: 19 print item[0],item[1],item[2],item[3] 20 except urllib2.URLError, e: 21 if hasattr(e,"code"): 22 print e.code 23 if hasattr(e,"reason"): 24 print e.reason
参考:http://cuiqingcai.com/990.html
标签:
原文地址:http://www.cnblogs.com/sxmcACM/p/4488738.html
