标签:
题外语:本人对linux内核的了解尚浅,如果有差池欢迎指正,也欢迎提问交流!
首先要理解一下每一个进程是如何维护自己独立的寻址空间的,我的电脑里呢是8G内存空间。了解过的朋友应该都知道这是虚拟内存技术解决的这个问题,然而再linux中具体是怎样的模型解决的操作系统的这个设计需求的呢,让我们从linux源码的片段开始看吧!(以下内核源码均来自fedora21 64位系统的fc-3.19.3版本内核)
<include/linux/mm_type.h>中对于物理页面的定义struct page,也就是我们常说的页表,关于这里的结构体的每个变量/位的操作函数大部分在<include/linux/mm.h>中。

1 struct page { 2 /* First double word block */ 3 unsigned long flags; /* Atomic flags, some possibly 4 * updated asynchronously */ 5 union { 6 struct address_space *mapping; /* If low bit clear, points to 7 * inode address_space, or NULL. 8 * If page mapped as anonymous 9 * memory, low bit is set, and 10 * it points to anon_vma object: 11 * see PAGE_MAPPING_ANON below. 12 */ 13 void *s_mem; /* slab first object */ 14 }; 15 16 /* Second double word */ 17 struct { 18 union { 19 pgoff_t index; /* Our offset within mapping. */ 20 void *freelist; /* sl[aou]b first free object */ 21 bool pfmemalloc; /* If set by the page allocator, 22 * ALLOC_NO_WATERMARKS was set 23 * and the low watermark was not 24 * met implying that the system 25 * is under some pressure. The 26 * caller should try ensure 27 * this page is only used to 28 * free other pages. 29 */ 30 }; 31 32 union { 33 #if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && 34 defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE) 35 /* Used for cmpxchg_double in slub */ 36 unsigned long counters; 37 #else 38 /* 39 * Keep _count separate from slub cmpxchg_double data. 40 * As the rest of the double word is protected by 41 * slab_lock but _count is not. 42 */ 43 unsigned counters; 44 #endif 45 46 struct { 47 48 union { 49 /* 50 * Count of ptes mapped in 51 * mms, to show when page is 52 * mapped & limit reverse map 53 * searches. 54 * 55 * Used also for tail pages 56 * refcounting instead of 57 * _count. Tail pages cannot 58 * be mapped and keeping the 59 * tail page _count zero at 60 * all times guarantees 61 * get_page_unless_zero() will 62 * never succeed on tail 63 * pages. 64 */ 65 atomic_t _mapcount; 66 67 struct { /* SLUB */ 68 unsigned inuse:16; 69 unsigned objects:15; 70 unsigned frozen:1; 71 }; 72 int units; /* SLOB */ 73 }; 74 atomic_t _count; /* Usage count, see below. */ 75 }; 76 unsigned int active; /* SLAB */ 77 }; 78 }; 79 80 /* Third double word block */ 81 union { 82 struct list_head lru; /* Pageout list, eg. active_list 83 * protected by zone->lru_lock ! 84 * Can be used as a generic list 85 * by the page owner. 86 */ 87 struct { /* slub per cpu partial pages */ 88 struct page *next; /* Next partial slab */ 89 #ifdef CONFIG_64BIT 90 int pages; /* Nr of partial slabs left */ 91 int pobjects; /* Approximate # of objects */ 92 #else 93 short int pages; 94 short int pobjects; 95 #endif 96 }; 97 98 struct slab *slab_page; /* slab fields */ 99 struct rcu_head rcu_head; /* Used by SLAB 100 * when destroying via RCU 101 */ 102 #if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS 103 pgtable_t pmd_huge_pte; /* protected by page->ptl */ 104 #endif 105 }; 106 107 /* Remainder is not double word aligned */ 108 union { 109 unsigned long private; /* Mapping-private opaque data: 110 * usually used for buffer_heads 111 * if PagePrivate set; used for 112 * swp_entry_t if PageSwapCache; 113 * indicates order in the buddy 114 * system if PG_buddy is set. 115 */ 116 #if USE_SPLIT_PTE_PTLOCKS 117 #if ALLOC_SPLIT_PTLOCKS 118 spinlock_t *ptl; 119 #else 120 spinlock_t ptl; 121 #endif 122 #endif 123 struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */ 124 struct page *first_page; /* Compound tail pages */ 125 }; 126 127 #ifdef CONFIG_MEMCG 128 struct mem_cgroup *mem_cgroup; 129 #endif 130 131 /* 132 * On machines where all RAM is mapped into kernel address space, 133 * we can simply calculate the virtual address. On machines with 134 * highmem some memory is mapped into kernel virtual memory 135 * dynamically, so we need a place to store that address. 136 * Note that this field could be 16 bits on x86 ... ;) 137 * 138 * Architectures with slow multiplication can define 139 * WANT_PAGE_VIRTUAL in asm/page.h 140 */ 141 #if defined(WANT_PAGE_VIRTUAL) 142 void *virtual; /* Kernel virtual address (NULL if 143 not kmapped, ie. highmem) */ 144 #endif /* WANT_PAGE_VIRTUAL */ 145 146 #ifdef CONFIG_KMEMCHECK 147 /* 148 * kmemcheck wants to track the status of each byte in a page; this 149 * is a pointer to such a status block. NULL if not tracked. 150 */ 151 void *shadow; 152 #endif 153 154 #ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS 155 int _last_cpupid; 156 #endif 157 }
在整个struct page的定义里面的注释对每个位都作了详尽的解释,但我还是觉得有几个重要的定义要重复一下:
(1)void*virtual:页的虚拟地址(由于在64位系统之中C语言里的void*指针的长度最长为64bit,寻址空间是2^64大远远超出了当前主流微机的硬件内存RAM的大小(8GB,16GB左右)这也就给虚拟空间寻址,交换技术提供了可能性)对virtual中的虚拟地址进行映射需要通过四级页表来进行。
(2)pgoff_t index:这个变量和freelist被定义在同一个union中,index变量被内存管理子系统中的多个模块使用,比如高速缓存。
(3)unsigned long flags:flag变量很少有设成long的可见里面的信息量比较大,这里是用来存放页的状态,比如锁/未锁,换出(虚拟内存用),激活等等。
再继续说内存管理机制之前,有一点非常重要,就是linux中关于进程和内存之间的对应关系。
linux中的每一个进程维护一个PCB,而这个PCB就是/include/linux/sched.h中定义的task_struct,在这个结构体的定义之中有定义变量:
struct mm_struct *mm, *active_mm;
这也就是进程和内存管理的桥梁之一,也是由此可见进程和内存块/页之间的关系是一对多的(考虑进程共享的内存的话是多对多),进程在装入内存的时候,操作系统的工作的实质是将task_struct中的相关的内存数据映射到部分映射到物理内存之中,而对于并没有映射的页就采取交换技术来解决。和windows系统中的程序装入过程相比较,windows中的程序装入过程都是靠loader完成的,loader的工作就是针对PE格式的可执行文件通过二进制的分析(比如IDT,IAT等等)进行装入,很多情况下一个进程都会被装入到同一个虚拟地址之中0x40000000(90%都是装入这里)。而linux之中,我们的进程是根据调度算法来安排其在虚拟地址之中的分布情况,buddy算法可以将进程的使用的页尽可能整齐地装入(其实这里我有些不是很清楚的地方,linux如果这么动态分配内存那么该如何处理一些动态加载的库的问题,像windows中的dll文件都是通过计算偏移来重定位,而linux会怎么做呢?)进程在已经装入物理内存的页的基础之上开始执行指令,跳转到并未被装入物理内存的页的虚拟地址的时候,会触发一个缺页中断,缺页中断触发页的交换的过程,从而帮助程序继续执行,这也就是虚拟内存的过程。
1 struct task_struct { 2 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ 3 void *stack; 4 atomic_t usage; 5 unsigned int flags; /* per process flags, defined below */ 6 unsigned int ptrace; 7 8 #ifdef CONFIG_SMP 9 struct llist_node wake_entry; 10 int on_cpu; 11 struct task_struct *last_wakee; 12 unsigned long wakee_flips; 13 unsigned long wakee_flip_decay_ts; 14 15 int wake_cpu; 16 #endif 17 int on_rq; 18 19 int prio, static_prio, normal_prio; 20 unsigned int rt_priority; 21 const struct sched_class *sched_class; 22 struct sched_entity se; 23 struct sched_rt_entity rt; 24 #ifdef CONFIG_CGROUP_SCHED 25 struct task_group *sched_task_group; 26 #endif 27 struct sched_dl_entity dl; 28 29 #ifdef CONFIG_PREEMPT_NOTIFIERS 30 /* list of struct preempt_notifier: */ 31 struct hlist_head preempt_notifiers; 32 #endif 33 34 #ifdef CONFIG_BLK_DEV_IO_TRACE 35 unsigned int btrace_seq; 36 #endif 37 38 unsigned int policy; 39 int nr_cpus_allowed; 40 cpumask_t cpus_allowed; 41 42 #ifdef CONFIG_PREEMPT_RCU 43 int rcu_read_lock_nesting; 44 union rcu_special rcu_read_unlock_special; 45 struct list_head rcu_node_entry; 46 #endif /* #ifdef CONFIG_PREEMPT_RCU */ 47 #ifdef CONFIG_PREEMPT_RCU 48 struct rcu_node *rcu_blocked_node; 49 #endif /* #ifdef CONFIG_PREEMPT_RCU */ 50 #ifdef CONFIG_TASKS_RCU 51 unsigned long rcu_tasks_nvcsw; 52 bool rcu_tasks_holdout; 53 struct list_head rcu_tasks_holdout_list; 54 int rcu_tasks_idle_cpu; 55 #endif /* #ifdef CONFIG_TASKS_RCU */ 56 57 #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) 58 struct sched_info sched_info; 59 #endif 60 61 struct list_head tasks; 62 #ifdef CONFIG_SMP 63 struct plist_node pushable_tasks; 64 struct rb_node pushable_dl_tasks; 65 #endif 66 67 struct mm_struct *mm, *active_mm; 68 #ifdef CONFIG_COMPAT_BRK 69 unsigned brk_randomized:1; 70 #endif 71 /* per-thread vma caching */ 72 u32 vmacache_seqnum; 73 struct vm_area_struct *vmacache[VMACACHE_SIZE]; 74 #if defined(SPLIT_RSS_COUNTING) 75 struct task_rss_stat rss_stat; 76 #endif 77 /* task state */ 78 int exit_state; 79 int exit_code, exit_signal; 80 int pdeath_signal; /* The signal sent when the parent dies */ 81 unsigned int jobctl; /* JOBCTL_*, siglock protected */ 82 83 /* Used for emulating ABI behavior of previous Linux versions */ 84 unsigned int personality; 85 86 unsigned in_execve:1; /* Tell the LSMs that the process is doing an 87 * execve */ 88 unsigned in_iowait:1; 89 90 /* Revert to default priority/policy when forking */ 91 unsigned sched_reset_on_fork:1; 92 unsigned sched_contributes_to_load:1; 93 94 #ifdef CONFIG_MEMCG_KMEM 95 unsigned memcg_kmem_skip_account:1; 96 #endif 97 98 unsigned long atomic_flags; /* Flags needing atomic access. */ 99 100 pid_t pid; 101 pid_t tgid; 102 103 #ifdef CONFIG_CC_STACKPROTECTOR 104 /* Canary value for the -fstack-protector gcc feature */ 105 unsigned long stack_canary; 106 #endif 107 /* 108 * pointers to (original) parent process, youngest child, younger sibling, 109 * older sibling, respectively. (p->father can be replaced with 110 * p->real_parent->pid) 111 */ 112 struct task_struct __rcu *real_parent; /* real parent process */ 113 struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ 114 /* 115 * children/sibling forms the list of my natural children 116 */ 117 struct list_head children; /* list of my children */ 118 struct list_head sibling; /* linkage in my parent‘s children list */ 119 struct task_struct *group_leader; /* threadgroup leader */ 120 121 /* 122 * ptraced is the list of tasks this task is using ptrace on. 123 * This includes both natural children and PTRACE_ATTACH targets. 124 * p->ptrace_entry is p‘s link on the p->parent->ptraced list. 125 */ 126 struct list_head ptraced; 127 struct list_head ptrace_entry; 128 129 /* PID/PID hash table linkage. */ 130 struct pid_link pids[PIDTYPE_MAX]; 131 struct list_head thread_group; 132 struct list_head thread_node; 133 134 struct completion *vfork_done; /* for vfork() */ 135 int __user *set_child_tid; /* CLONE_CHILD_SETTID */ 136 int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ 137 138 cputime_t utime, stime, utimescaled, stimescaled; 139 cputime_t gtime; 140 #ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE 141 struct cputime prev_cputime; 142 #endif 143 #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN 144 seqlock_t vtime_seqlock; 145 unsigned long long vtime_snap; 146 enum { 147 VTIME_SLEEPING = 0, 148 VTIME_USER, 149 VTIME_SYS, 150 } vtime_snap_whence; 151 #endif 152 unsigned long nvcsw, nivcsw; /* context switch counts */ 153 u64 start_time; /* monotonic time in nsec */ 154 u64 real_start_time; /* boot based time in nsec */ 155 /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ 156 unsigned long min_flt, maj_flt; 157 158 struct task_cputime cputime_expires; 159 struct list_head cpu_timers[3]; 160 161 /* process credentials */ 162 const struct cred __rcu *real_cred; /* objective and real subjective task 163 * credentials (COW) */ 164 const struct cred __rcu *cred; /* effective (overridable) subjective task 165 * credentials (COW) */ 166 char comm[TASK_COMM_LEN]; /* executable name excluding path 167 - access with [gs]et_task_comm (which lock 168 it with task_lock()) 169 - initialized normally by setup_new_exec */ 170 /* file system info */ 171 int link_count, total_link_count; 172 #ifdef CONFIG_SYSVIPC 173 /* ipc stuff */ 174 struct sysv_sem sysvsem; 175 struct sysv_shm sysvshm; 176 #endif 177 #ifdef CONFIG_DETECT_HUNG_TASK 178 /* hung task detection */ 179 unsigned long last_switch_count; 180 #endif 181 /* CPU-specific state of this task */ 182 struct thread_struct thread; 183 /* filesystem information */ 184 struct fs_struct *fs; 185 /* open file information */ 186 struct files_struct *files; 187 /* namespaces */ 188 struct nsproxy *nsproxy; 189 /* signal handlers */ 190 struct signal_struct *signal; 191 struct sighand_struct *sighand; 192 193 sigset_t blocked, real_blocked; 194 sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */ 195 struct sigpending pending; 196 197 unsigned long sas_ss_sp; 198 size_t sas_ss_size; 199 int (*notifier)(void *priv); 200 void *notifier_data; 201 sigset_t *notifier_mask; 202 struct callback_head *task_works; 203 204 struct audit_context *audit_context; 205 #ifdef CONFIG_AUDITSYSCALL 206 kuid_t loginuid; 207 unsigned int sessionid; 208 #endif 209 struct seccomp seccomp; 210 211 /* Thread group tracking */ 212 u32 parent_exec_id; 213 u32 self_exec_id; 214 /* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, 215 * mempolicy */ 216 spinlock_t alloc_lock; 217 218 /* Protection of the PI data structures: */ 219 raw_spinlock_t pi_lock; 220 221 #ifdef CONFIG_RT_MUTEXES 222 /* PI waiters blocked on a rt_mutex held by this task */ 223 struct rb_root pi_waiters; 224 struct rb_node *pi_waiters_leftmost; 225 /* Deadlock detection and priority inheritance handling */ 226 struct rt_mutex_waiter *pi_blocked_on; 227 #endif 228 229 #ifdef CONFIG_DEBUG_MUTEXES 230 /* mutex deadlock detection */ 231 struct mutex_waiter *blocked_on; 232 #endif 233 #ifdef CONFIG_TRACE_IRQFLAGS 234 unsigned int irq_events; 235 unsigned long hardirq_enable_ip; 236 unsigned long hardirq_disable_ip; 237 unsigned int hardirq_enable_event; 238 unsigned int hardirq_disable_event; 239 int hardirqs_enabled; 240 int hardirq_context; 241 unsigned long softirq_disable_ip; 242 unsigned long softirq_enable_ip; 243 unsigned int softirq_disable_event; 244 unsigned int softirq_enable_event; 245 int softirqs_enabled; 246 int softirq_context; 247 #endif 248 #ifdef CONFIG_LOCKDEP 249 # define MAX_LOCK_DEPTH 48UL 250 u64 curr_chain_key; 251 int lockdep_depth; 252 unsigned int lockdep_recursion; 253 struct held_lock held_locks[MAX_LOCK_DEPTH]; 254 gfp_t lockdep_reclaim_gfp; 255 #endif 256 257 /* journalling filesystem info */ 258 void *journal_info; 259 260 /* stacked block device info */ 261 struct bio_list *bio_list; 262 263 #ifdef CONFIG_BLOCK 264 /* stack plugging */ 265 struct blk_plug *plug; 266 #endif 267 268 /* VM state */ 269 struct reclaim_state *reclaim_state; 270 271 struct backing_dev_info *backing_dev_info; 272 273 struct io_context *io_context; 274 275 unsigned long ptrace_message; 276 siginfo_t *last_siginfo; /* For ptrace use. */ 277 struct task_io_accounting ioac; 278 #if defined(CONFIG_TASK_XACCT) 279 u64 acct_rss_mem1; /* accumulated rss usage */ 280 u64 acct_vm_mem1; /* accumulated virtual memory usage */ 281 cputime_t acct_timexpd; /* stime + utime since last update */ 282 #endif 283 #ifdef CONFIG_CPUSETS 284 nodemask_t mems_allowed; /* Protected by alloc_lock */ 285 seqcount_t mems_allowed_seq; /* Seqence no to catch updates */ 286 int cpuset_mem_spread_rotor; 287 int cpuset_slab_spread_rotor; 288 #endif 289 #ifdef CONFIG_CGROUPS 290 /* Control Group info protected by css_set_lock */ 291 struct css_set __rcu *cgroups; 292 /* cg_list protected by css_set_lock and tsk->alloc_lock */ 293 struct list_head cg_list; 294 #endif 295 #ifdef CONFIG_FUTEX 296 struct robust_list_head __user *robust_list; 297 #ifdef CONFIG_COMPAT 298 struct compat_robust_list_head __user *compat_robust_list; 299 #endif 300 struct list_head pi_state_list; 301 struct futex_pi_state *pi_state_cache; 302 #endif 303 #ifdef CONFIG_PERF_EVENTS 304 struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts]; 305 struct mutex perf_event_mutex; 306 struct list_head perf_event_list; 307 #endif 308 #ifdef CONFIG_DEBUG_PREEMPT 309 unsigned long preempt_disable_ip; 310 #endif 311 #ifdef CONFIG_NUMA 312 struct mempolicy *mempolicy; /* Protected by alloc_lock */ 313 short il_next; 314 short pref_node_fork; 315 #endif 316 #ifdef CONFIG_NUMA_BALANCING 317 int numa_scan_seq; 318 unsigned int numa_scan_period; 319 unsigned int numa_scan_period_max; 320 int numa_preferred_nid; 321 unsigned long numa_migrate_retry; 322 u64 node_stamp; /* migration stamp */ 323 u64 last_task_numa_placement; 324 u64 last_sum_exec_runtime; 325 struct callback_head numa_work; 326 327 struct list_head numa_entry; 328 struct numa_group *numa_group; 329 330 /* 331 * numa_faults is an array split into four regions: 332 * faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer 333 * in this precise order. 334 * 335 * faults_memory: Exponential decaying average of faults on a per-node 336 * basis. Scheduling placement decisions are made based on these 337 * counts. The values remain static for the duration of a PTE scan. 338 * faults_cpu: Track the nodes the process was running on when a NUMA 339 * hinting fault was incurred. 340 * faults_memory_buffer and faults_cpu_buffer: Record faults per node 341 * during the current scan window. When the scan completes, the counts 342 * in faults_memory and faults_cpu decay and these values are copied. 343 */ 344 unsigned long *numa_faults; 345 unsigned long total_numa_faults; 346 347 /* 348 * numa_faults_locality tracks if faults recorded during the last 349 * scan window were remote/local. The task scan period is adapted 350 * based on the locality of the faults with different weights 351 * depending on whether they were shared or private faults 352 */ 353 unsigned long numa_faults_locality[2]; 354 355 unsigned long numa_pages_migrated; 356 #endif /* CONFIG_NUMA_BALANCING */ 357 358 struct rcu_head rcu; 359 360 /* 361 * cache last used pipe for splice 362 */ 363 struct pipe_inode_info *splice_pipe; 364 365 struct page_frag task_frag; 366 367 #ifdef CONFIG_TASK_DELAY_ACCT 368 struct task_delay_info *delays; 369 #endif 370 #ifdef CONFIG_FAULT_INJECTION 371 int make_it_fail; 372 #endif 373 /* 374 * when (nr_dirtied >= nr_dirtied_pause), it‘s time to call 375 * balance_dirty_pages() for some dirty throttling pause 376 */ 377 int nr_dirtied; 378 int nr_dirtied_pause; 379 unsigned long dirty_paused_when; /* start of a write-and-pause period */ 380 381 #ifdef CONFIG_LATENCYTOP 382 int latency_record_count; 383 struct latency_record latency_record[LT_SAVECOUNT]; 384 #endif 385 /* 386 * time slack values; these are used to round up poll() and 387 * select() etc timeout values. These are in nanoseconds. 388 */ 389 unsigned long timer_slack_ns; 390 unsigned long default_timer_slack_ns; 391 392 #ifdef CONFIG_FUNCTION_GRAPH_TRACER 393 /* Index of current stored address in ret_stack */ 394 int curr_ret_stack; 395 /* Stack of return addresses for return function tracing */ 396 struct ftrace_ret_stack *ret_stack; 397 /* time stamp for last schedule */ 398 unsigned long long ftrace_timestamp; 399 /* 400 * Number of functions that haven‘t been traced 401 * because of depth overrun. 402 */ 403 atomic_t trace_overrun; 404 /* Pause for the tracing */ 405 atomic_t tracing_graph_pause; 406 #endif 407 #ifdef CONFIG_TRACING 408 /* state flags for use by tracers */ 409 unsigned long trace; 410 /* bitmask and counter of trace recursion */ 411 unsigned long trace_recursion; 412 #endif /* CONFIG_TRACING */ 413 #ifdef CONFIG_MEMCG 414 struct memcg_oom_info { 415 struct mem_cgroup *memcg; 416 gfp_t gfp_mask; 417 int order; 418 unsigned int may_oom:1; 419 } memcg_oom; 420 #endif 421 #ifdef CONFIG_UPROBES 422 struct uprobe_task *utask; 423 #endif 424 #if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE) 425 unsigned int sequential_io; 426 unsigned int sequential_io_avg; 427 #endif 428 #ifdef CONFIG_DEBUG_ATOMIC_SLEEP 429 unsigned long task_state_change; 430 #endif 431 };
愚蠢的问题1:
MMU是由硬件实现的专门为解决虚拟地址和物理地址映射问题而设计的部件,那么为什么要在linux的源代码中体现呢?为什么在要在软件中再描述一次呢?
虚拟地址到物理地址的映射,(目前而讲)需要4级页表索引的访问来完成。在mm_struct结构体中的定义之中有一个pdg_t类型的指针名叫pgd(PageGlobalDirectory),由此出发继续向下级访问有pud(PageUpperDirectory)pmd(PageMiddleDirectory)pte(PageTableEntry),最后一级是具体的页表很遗憾的是,我暂时没有在3.19内核的源码中找到关于pte_t的定义,但是根据书籍上的描述应该是一个指向struct page数组的指针。
于是我们可以这样总结,程序在执行的过程会有大量的跳转的过程,而每次的跳转需要一个操作数即地址,这个地址是一个虚拟地址,然后根据该虚拟地址进行MMU的操作,过程中得到一个页表,首先根据页表判断该页是否已经存在于物理内存中,如果不是的话则进行一次交换的操作,上文已经阐述过该过程,页交换完成之后,寻址过程就得以继续进行了,此时使用相同的虚拟地址访问到的是另一个物理页面,即交换进入的物理页面。
愚蠢的问题2:
虚拟内存的机制像是把物理内存和外部存储容量共同地址编码,这个共同的编码就是虚拟地址,所谓“编码”过程不一定是顺序一对一的,但是虚拟地址和页表的索引之间一定是个满射关系。
这是我最初对于虚拟内存机制的理解,表面看起来没有什么问题,可还是当考虑每个进程的寻址空间独立性的时候就会发现问题,相同的地址在两个进程中映射外部地址应该可以是不相同的,可是一旦将他们看作共同地址编码,就不会有相同的逻辑地址映射到不同的物理地址这回事了。
其实答案很简单一句话:每个进程维护一个页表 !
最后一张大图概括一下上文
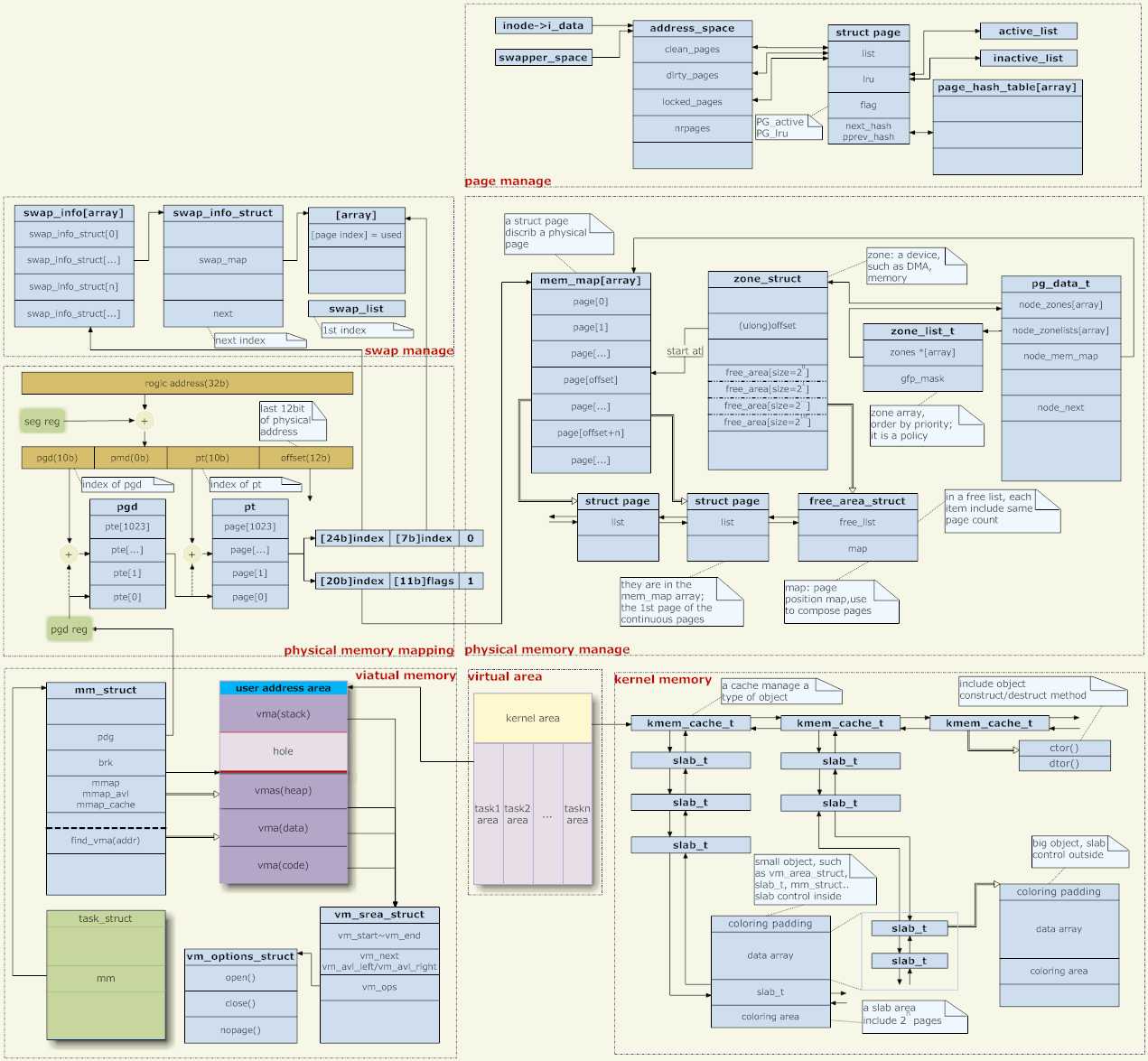
标签:
原文地址:http://www.cnblogs.com/guguli/p/4489272.html
