标签:
OCR,即Optical Character Recognition,光学字符识别。以下介绍来自搜索:
OCR(Optical Character
Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent
Character
Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
简单地说吧,就是识别印刷品上面的文字,大概用得比较多的情况是:用设备的摄像头拍一张照片,照片中有文字,然后通过OCR技术将照片中的字符识别出来,转化为字符。顺便说一下,如果想“干坏事”的话,也可以用OCR技术来识别一些简单的图片验证码,呵呵,不过,现在很多网站的验证码都比较“狡猾”,要准确识别出来不那么容易。
好了,接下来看看如何在UAP中使用OCR技术。
用于OCR识别的API主要在Windows.Media.Ocr命名空间下。用法如下:
1、调用IsLanguageSupported静态方法检查一下,是否支持某种语言文字的识别,如繁体中文、简体中文等(估计它识别不了甲骨文和篆书)。
2、调用OcrEngine.TryCreateFromLanguage方法从指定的语言创建OcrEngine实例;或者调用TryCreateFromUserProfileLanguages方法从用户配置的语言中创建。这些方法都是静态的,可直接访问。
3、调用OcrEngine实例的RecognizeAsync方法开始进行识别,识别完成后会异步返回OcrResult对象,其中对象中的Text属性就是被识别出来的文本。RecognizeAsync方法需要一个Windows.Graphics.Imaging.SoftwareBitmap实例作为参数,它通过BitmapDecoder类来获取,就是要进行识别的图片。
下面就用一个示例来演示一下。该例可以选择一张带文字的图片,然后识别出图中的文本。代码如下:
FileOpenPicker picker = new FileOpenPicker(); picker.FileTypeFilter.Add(".jpg"); picker.FileTypeFilter.Add(".jpeg"); // 选择文件 StorageFile imgFile = await picker.PickSingleFileAsync(); if(imgFile != null) { using (IRandomAccessStream inStream = await imgFile.OpenReadAsync()) { // 显示图片 BitmapImage bmp = new BitmapImage(); bmp.DecodePixelWidth = 700; bmp.SetSource(inStream.CloneStream()); this.img.Source = bmp; // 解码图片 BitmapDecoder decoder = await BitmapDecoder.CreateAsync(BitmapDecoder.JpegDecoderId, inStream); // 获取图像 SoftwareBitmap swbmp = await decoder.GetSoftwareBitmapAsync(); // 准备识别 Windows.Globalization.Language lang = new Windows.Globalization.Language("zh-CN"); // 判断是否支持简体中文识别 if (OcrEngine.IsLanguageSupported(lang)) { OcrEngine engine = OcrEngine.TryCreateFromLanguage(lang); if (engine != null) { OcrResult result = await engine.RecognizeAsync(swbmp); if (result != null) { tbResult.Text = result.Text; } } } else { Windows.UI.Popups.MessageDialog dialog = new Windows.UI.Popups.MessageDialog("不支持简体中文的识别。"); await dialog.ShowAsync(); } } }
目前是支持简体中文字符的识别,不过准确率还不能达到100%,97%的准确应该可以保证的。看看识别的结果:
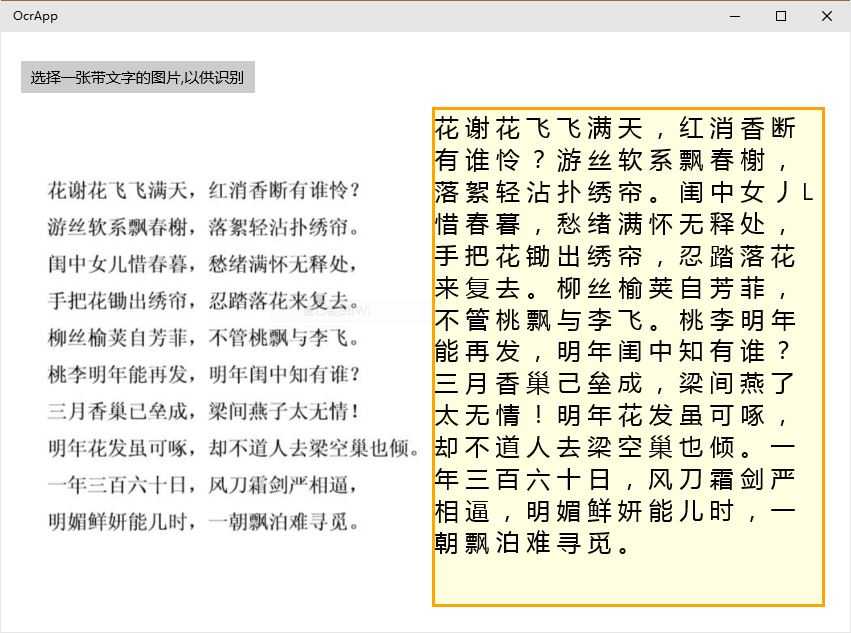
从上面的结果来看,“儿”、“子”、“几”三字没有正确识别,准确率还过得去。
示例源码下载:http://files.cnblogs.com/files/tcjiaan/OcrApp.zip
好,本次就扯到这里,改天有空再吹。
标签:
原文地址:http://www.cnblogs.com/tcjiaan/p/4491906.html