标签:
问题一:
Select * from student; 这种语句不好
我的理解:根据Innode存储引擎以及网上的各种资料所说的innodb的B+树索引结构可以分析出,当在非聚集索引列上搜索若用select * 会发生索引覆盖的问题。下面请看演示:
首先我们的表中的数据是:
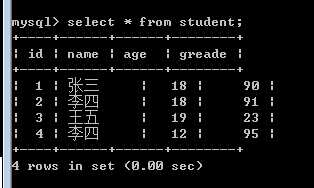
表的结构是:
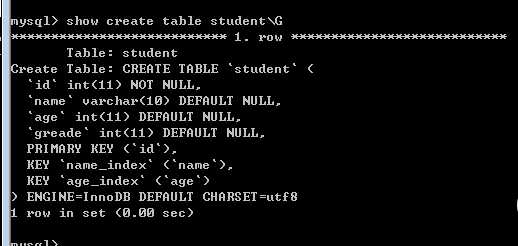
我们可以看到:表里有三个索引,primary 索引,name列的name_index索引,以及age列的age_index索引。
然后我们进行搜索:
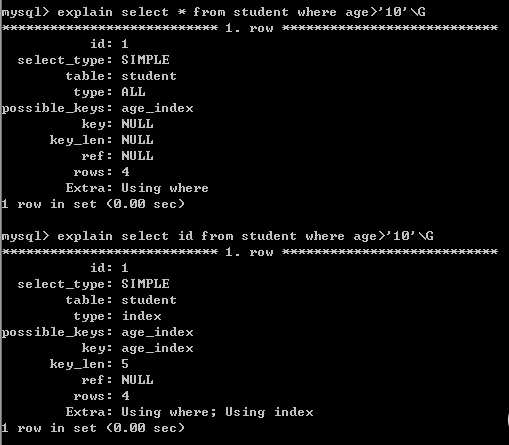
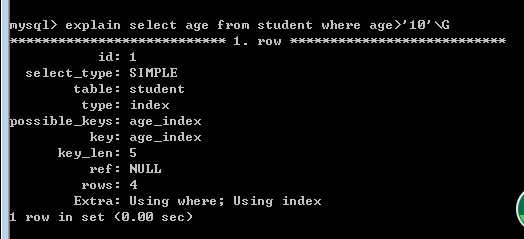
我们发现分别搜索*,id,age三个列进行了搜索,我们预计的结果是*不使用索引,id和age会使用age_index索引,但是呈现的是三个都使用了索引。然后我们在以name作为where的判定条件进行select * 搜索。我们预计的是也不使用name_index,但explain现实的依旧是使用索引,如下:
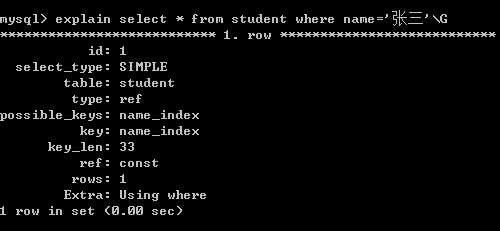
这是由于我们的表中的数据量太小,当表中的数据量较小时,存储引擎的优化器依旧会使用非聚集索引然后再进行一次书签查找。
索引我们给表中在增加几条数据,如下:
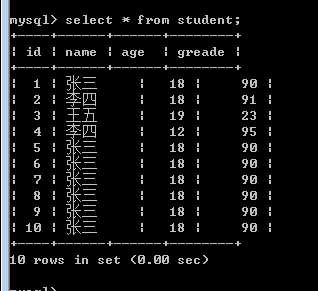
然后再进行刚才的以name为判定条件进行select*查找。
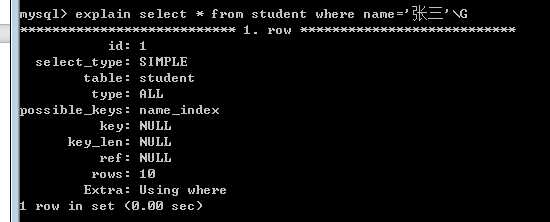
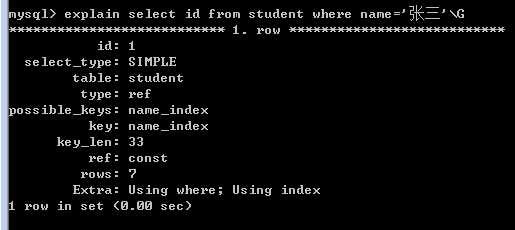
我们发现此时,select * 是没有使用非聚集索引name_index,而id是使用到了索引的。
所以,以上理论成立!
总结如下:

问题二:limit 1 为什么效率高
网上有一篇文章说的比较清楚:http://www.linuxidc.com/Linux/2013-03/81974.htm
大概意思是因为加上LIMIT 1,只要找到了对应的一条记录,就不会继续向下扫描了,效率会大大提高。
由于mysql自带的explain和profiles 并不能检测搜索了多少条语句,所以并不能直观的验证,可通过cpu使用率间接分析,但完整的测试需要用到大量非重复数据,所以没有直观的截图来验证。这里来引用mysql官方文档来作为例证:
Mysql官方文档对于limit的定义:
In some cases, MySQL handles a query differently when you are using LIMIT row_count and not using HAVING:
If you are selecting only a few rows with LIMIT, MySQL uses indexes in some cases when normally it would prefer to do a full table scan.
If you use LIMIT row_count with ORDER BY, MySQL ends the sorting as soon as it has found the firstrow_count rows of the sorted result, rather than sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query without the LIMIT clause must be selected, and most or all of them must be sorted, before it can be ascertained that the first row_count rows have been found. In either case, after the initial rows have been found, there is no need to sort any remainder of the result set, and MySQL does not do so.
When combining LIMIT row_count with DISTINCT, MySQL stops as soon as it finds row_count unique rows.
In some cases, a GROUP BY can be resolved by reading the key in order (or doing a sort on the key) and then calculating summaries until the key value changes. In this case, LIMIT row_count does not calculate any unnecessary GROUP BY values.
As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are usingSQL_CALC_FOUND_ROWS.
LIMIT 0 quickly returns an empty set. This can be useful for checking the validity of a query. When using one of the MySQL APIs, it can also be employed for obtaining the types of the result columns. (This trick does not work in the MySQL Monitor (the mysql program), which merely displays Empty set in such cases; you should instead use SHOW COLUMNS or DESCRIBE for this purpose.)
When the server uses temporary tables to resolve the query, it uses the LIMIT row_count clause to calculate how much space is required.
从上面加大的字体可以看出,mysql官方文档又说到:
When combining MySQL stops as soon as it finds
所以,例证成
select * 为什么不好? limit 1 为什么好? --mysql SQL语句优化
标签:
原文地址:http://www.cnblogs.com/xyxxs/p/4493265.html