标签:
借助于文章【1】中的内容把EM算法的过程顺一遍,加深一下印象。
关于EM公式的推导,一般会有两个证明,一个是利用Jesen不等式,另一个是将其分解成KL距离和L函数,本质是类似的。
下面介绍Jensen EM的整个推导过程。
Jensen不等式
回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x,
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么
特别地,如果f是严格凸函数,那么
这里我们将
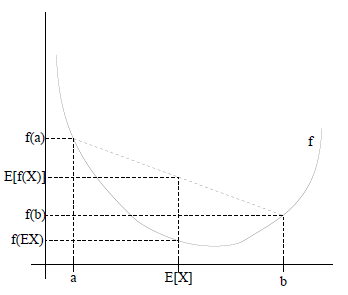
如果用图表示会很清晰:
图中,实线
当
Jensen不等式应用于凹函数时,不等号方向反向,也就是
EM算法
给定的训练样本是clip_image023,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
clip_image024
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求clip_image026一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。竟然不能直接最大化clip_image028,我们可以不断地建立clip_image030的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i,让clip_image032表示该样例隐含变量z的某种分布,clip_image032[1]满足的条件是clip_image034。(如果z是连续性的,那么clip_image032[2]是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
可以由前面阐述的内容得到下面的公式:
clip_image035
(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式,考虑到clip_image037是凹函数(二阶导数小于0),而且
clip_image038
就是clip_image039的期望(回想期望公式中的Lazy Statistician规则)
设Y是随机变量X的函数clip_image041(g是连续函数),那么
(1) X是离散型随机变量,它的分布律为clip_image043,k=1,2,…。若clip_image045绝对收敛,则有
clip_image047
(2) X是连续型随机变量,它的概率密度为clip_image049,若clip_image051绝对收敛,则有
clip_image053
对应于上述问题,Y是clip_image039[1],X是clip_image055,clip_image057是clip_image059,g是clip_image055[1]到clip_image039[2]的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:
clip_image060
可以得到(3)。
这个过程可以看作是对clip_image028[1]求了下界。对于clip_image032[3]的选择,有多种可能,那种更好的?假设clip_image026[1]已经给定,那么clip_image028[2]的值就决定于clip_image057[1]和clip_image062了。我们可以通过调整这两个概率使下界不断上升,以逼近clip_image028[3]的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于clip_image028[4]了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
clip_image063
c为常数,不依赖于clip_image065。对此式子做进一步推导,我们知道clip_image067,那么也就有clip_image069,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
clip_image070
至此,我们推出了在固定其他参数clip_image026[2]后,clip_image072的计算公式就是后验概率,解决了clip_image072[1]如何选择的问题。这一步就是E步,建立clip_image028[5]的下界。接下来的M步,就是在给定clip_image072[2]后,调整clip_image026[3],去极大化clip_image028[6]的下界(在固定clip_image072[3]后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
循环重复直到收敛 {
(E步)对于每一个i,计算
clip_image074
(M步)计算
clip_image075
那么究竟怎么确保EM收敛?假定clip_image077和clip_image079是EM第t次和t+1次迭代后的结果。如果我们证明了clip_image081,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定clip_image077[1]后,我们得到E步
clip_image083
这一步保证了在给定clip_image077[2]时,Jensen不等式中的等式成立,也就是
clip_image084
然后进行M步,固定clip_image086,并将clip_image088视作变量,对上面的clip_image090求导后,得到clip_image092,这样经过一些推导会有以下式子成立:
clip_image093
解释第(4)步,得到clip_image092[1]时,只是最大化clip_image090[1],也就是clip_image095的下界,而没有使等式成立,等式成立只有是在固定clip_image026[4],并按E步得到clip_image097时才能成立。
况且根据我们前面得到的下式,对于所有的clip_image097[1]和clip_image026[5]都成立
clip_image098
第(5)步利用了M步的定义,M步就是将clip_image088[1]调整到clip_image100,使得下界最大化。因此(5)成立,(6)是之前的等式结果。
这样就证明了clip_image102会单调增加。一种收敛方法是clip_image102[1]不再变化,还有一种就是变化幅度很小。
再次解释一下(4)、(5)、(6)。首先(4)对所有的参数都满足,而其等式成立条件只是在固定clip_image026[6],并调整好Q时成立,而第(4)步只是固定Q,调整clip_image026[7],不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与clip_image102[2]一个特定值(这里clip_image088[2])一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与clip_image102[3]另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
如果我们定义
clip_image103
从前面的推导中我们知道clip_image105,EM可以看作是J的坐标上升法,E步固定clip_image026[8],优化clip_image107,M步固定clip_image107[1]优化clip_image026[9]。
重新审视混合高斯模型
我们已经知道了EM的精髓和推导过程,再次审视一下混合高斯模型。之前提到的混合高斯模型的参数clip_image109和clip_image111计算公式都是根据很多假定得出的,有些没有说明来由。为了简单,这里在M步只给出clip_image113和clip_image115的推导方法。
E步很简单,按照一般EM公式得到:
clip_image116
简单解释就是每个样例i的隐含类别clip_image055[2]为j的概率可以通过后验概率计算得到。
在M步中,我们需要在固定clip_image072[4]后最大化最大似然估计,也就是
clip_image118
这是将clip_image120的k种情况展开后的样子,未知参数clip_image122和clip_image124。
固定clip_image126和clip_image128,对clip_image130求导得
clip_image131
等于0时,得到
clip_image132
这就是我们之前模型中的clip_image115[1]的更新公式。
然后推导clip_image126[1]的更新公式。看之前得到的
clip_image133
在clip_image113[1]和clip_image115[2]确定后,分子上面的一串都是常数了,实际上需要优化的公式是:
clip_image134
需要知道的是,clip_image126[2]还需要满足一定的约束条件就是clip_image136。
这个优化问题我们很熟悉了,直接构造拉格朗日乘子。
clip_image137
还有一点就是clip_image139,但这一点会在得到的公式里自动满足。
求导得,
clip_image141
等于0,得到
clip_image142
也就是说clip_image143再次使用clip_image136[1],得到
clip_image144
这样就神奇地得到了clip_image146。
那么就顺势得到M步中clip_image126[3]的更新公式:
clip_image147
clip_image111[1]的推导也类似,不过稍微复杂一些,毕竟是矩阵。结果在之前的混合高斯模型中已经给出。
总结
如果将样本看作观察值,潜在类别看作是隐藏变量,那么聚类问题也就是参数估计问题,只不过聚类问题中参数分为隐含类别变量和其他参数,这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步估计隐含变量,M步估计其他参数,交替将极值推向最大。EM中还有“硬”指定和“软”指定的概念,“软”指定看似更为合理,但计算量要大,“硬”指定在某些场合如K-means中更为实用(要是保持一个样本点到其他所有中心的概率,就会很麻烦)。
另外,EM的收敛性证明方法确实很牛,能够利用log的凹函数性质,还能够想到利用创造下界,拉平函数下界,优化下界的方法来逐步逼近极大值。而且每一步迭代都能保证是单调的。最重要的是证明的数学公式非常精妙,硬是分子分母都乘以z的概率变成期望来套上Jensen不等式,前人都是怎么想到的。
在Mitchell的Machine Learning书中也举了一个EM应用的例子,明白地说就是将班上学生的身高都放在一起,要求聚成两个类。这些身高可以看作是男生身高的高斯分布和女生身高的高斯分布组成。因此变成了如何估计每个样例是男生还是女生,然后在确定男女生情况下,如何估计均值和方差,里面也给出了公式,有兴趣可以参考。
参考:
【1】
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html#2831962
【2】http://wenku.baidu.com/view/d5e6973a87c24028915fc361.html
标签:
原文地址:http://blog.csdn.net/lansatiankongxxc/article/details/45646677