前段时间做了个在线教育培训的项目,与视频会议比较类似,所以了,我打算像 广域网即时通信系统GG(QQ高仿版)一样,写一个视频会议系统并把实现的原理和源码都分享出来,让有兴趣的朋友可以参考下。继承GG的名称,我把这个视频会议系统命名为GGMeeting,目前版本为1.0,后续功能会不断增强。
一般而言,视频会议的主要核心功能是:多人语音、多人视频、公共电子白板、会议房间管理。本文我们将介绍视频会议系统的主要功能及其实现原理,后面有空在介绍详细每个功能的详细实现细节。
在视频会议中,网络语音通话通常多对多的的,但就模型层面来说,我们讨论一个方向的通道就可以了。一方说话,另一方则听到声音。看似简单而迅捷,但是其背后的流程却是相当复杂的。我们将其经过的各个主要环节简化成下图所示的概念模型:
![]()
这是一个最基础的模型,由五个重要的环节构成:采集、编码、传送、解码、播放。
语音采集指的是从麦克风采集音频数据,即声音样本转换成数字信号。其涉及到几个重要的参数:采样频率、采样位数、声道数。
假设我们将采集到的音频帧不经过编码,而直接发送,那么我们可以计算其所需要的带宽要求,仍以上例:320*100 =32KBytes/s,如果换算为bits/s,则为256kb/s。这是个很大的带宽占用。而通过网络流量监控工具,我们可以发现采用类似QQ等IM软件进行语音通话时,流量为3-5KB/s,这比原始流量小了一个数量级。而这主要得益于音频编码技术。 所以,在实际的语音通话应用中,编码这个环节是不可缺少的。目前有很多常用的语音编码技术,像G.729、iLBC、AAC、SPEEX等等。
当一个音频帧完成编码后,即可通过网络发送给通话的对方。对于语音对话这样Realtime应用,低延迟和平稳是非常重要的,这就要求我们的网络传送非常顺畅。
当对方接收到编码帧后,会对其进行解码,以恢复成为可供声卡直接播放的数据。
完成解码后,即可将得到的音频帧提交给声卡进行播放。
如果仅仅依靠上述的技术就能实现一个效果良好的应用于广域网上的语音对话系统,那就太easy了。正是由于很多现实的因素为上述的概念模型引入了众多挑战,使得网络语音系统的实现不是那么简单,其涉及到很多专业技术。一个“效果良好”的语音对话系统应该达到如下几点:低延迟,背景噪音小,声音流畅、没有卡、停顿的感觉,没有回音。
对于低延迟,只有在低延迟的情况下,才能让通话的双方有很强的Realtime的感觉。当然,这个主要取决于网络的速度和通话双方的物理位置的距离,就单纯软件的角度,优化的可能性很小。
(1)回音消除
现在大家几乎都已经都习惯了在语音聊天时,直接用PC或笔记本的声音外放功能。当使用外放功能时,扬声器播放的声音会被麦克风再次采集,传回给对方,这样对方就听到了自己的回音。
回音消除的原理简单地来说就是,回音消除模块依据刚播放的音频帧,在采集的音频帧中做一些类似抵消的运算,从而将回声从采集帧中清除掉。这个过程是相当复杂的,因为它还与你聊天时所处的房间的大小、以及你在房间中的位置有关,因为这些信息决定了声波反射的时长。 智能的回音消除模块,能动态调整内部参数,以最佳适应当前的环境。
(2)噪声抑制
噪声抑制又称为降噪处理,是根据语音数据的特点,将属于背景噪音的部分识别出来,并从音频帧中过滤掉。有很多编码器都内置了该功能。
(3)抖动缓冲区
抖动缓冲区(JitterBuffer)用于解决网络抖动的问题。所谓网络抖动,就是网络延迟一会大一会小,在这种情况下,即使发送方是定时发送数据包的(比如每100ms发送一个包),而接收方的接收就无法同样定时了,有时一个周期内一个包都接收不到,有时一个周期内接收到好几个包。如此,导致接收方听到的声音就是一卡一卡的。
JitterBuffer工作于解码器之后,语音播放之前的环节。即语音解码完成后,将解码帧放入JitterBuffer,声卡的播放回调到来时,从JitterBuffer中取出最老的一帧进行播放。
JitterBuffer的缓冲深度取决于网络抖动的程度,网络抖动越大,缓冲深度越大,播放音频的延迟就越大。所以,JitterBuffer是利用了较高的延迟来换取声音的流畅播放的,因为相比声音一卡一卡来说,稍大一点的延迟但更流畅的效果,其主观体验要更好。
当然,JitterBuffer的缓冲深度不是一直不变的,而是根据网络抖动程度的变化而动态调整的。当网络恢复到非常平稳通畅时,缓冲深度会非常小,这样因为JitterBuffer而增加的播放延迟就可以忽略不计了。
(4)静音检测
在语音对话中,要是当一方没有说话时,就不会产生流量就好了。静音检测就是用于这个目的的。静音检测通常也集成在编码模块中。静音检测算法结合前面的噪声抑制算法,可以识别出当前是否有语音输入,如果没有语音输入,就可以编码输出一个特殊的的编码帧(比如长度为0)。特别是在多人视频会议中,通常只有一个人在发言,这种情况下,利用静音检测技术而节省带宽还是非常可观的。
(5)混音
在视频会议中,多人同时发言时,我们需要同时播放来自于多个人的语音数据,而声卡播放的缓冲区只有一个,所以,需要将多路语音混合成一路,这就是混音算法要做的事情。
视频通话的概念模型与语音完全一致:
![]()
摄像头采集指的是从捕捉摄像头采集到的每一帧视频图像。在windows系统上,通常使用VFW技术或DirectShow技术来实现。采集视频的两个关键参数是帧频(fps)和分辨率。
一般而言,一个摄像头可以支持多种不同的采集分辨率和采集帧频,而不同的摄像头支持的分辨率的集合不一样。比如现在有很多高清摄像头可以支持30fps的1920*1080的图像采集。
编码用于压缩视频图像,同时也决定了图像的清晰度。视频编码常用的技术是H.263、H.264、MPEG-4、XVID等。
当对方接收到编码的视频帧后,会对其进行解码,以恢复成一帧图像,然后在UI的界面上绘制出来。
相比于语音,视频的相关处理要简单一些。
(1)动态调整视频的清晰度
在Internet上,网络速度是实时动态变化的,所以,在视频会议中,为了优先保证语音的通话质量,需要实时调整视频的相关参数,其最主要的就是调整编码的清晰度,因为清晰度越高,对带宽要求越高,反之亦然。
比如,当检测网络繁忙时,就自动降低编码的清晰度,以降低对带宽的占用。
(2)自动丢弃视频帧
同样网络繁忙时,还有一个方法,就是发送方是主动丢弃要发送的视频帧,这样在接收方看来,就是帧频fps降低了。
在视频会议中,电子白板的功能是很重要的。通常会议的主持人会在白板上画图进行讲解,然后其它的人能同步观看和操作电子白板的内容。
通常的电子白板都支持如下功能:线段、箭头线、双箭头线,水平肘型连接符、垂直肘型连接符,矩形、三角形、椭圆(圆),文本,自由曲线,插入图片,激光笔。
在实现上,电子白板主要是使用GDI+技术。
对于电子白板的同步,其原理是这样的:比如,当操作者在白板上绘制一个图像时,这个操作会被封装成一个Command对象(命令模式),然后,通过网络广播发送给会议中的其它人。当其他人接收到这个Command对象时,就将其转换成一个白板操作来执行,这样各个白板的内容就自动同步了。
对于那些动态创建视频会议室,在用完之后就动态将其销毁的通常的视频会议应用场景来说,使用动态组来表示会议房间,是非常恰当的。
所谓“动态组”,就是在服务器内存中动态创建的组,不需要序列化存储到比如数据库或磁盘中,需要的时候就创建一个,然后加入多个成员进行组内沟通,当不再使用的时候,就直接从内存中销毁了。
基于Socket技术,我们可以在服务端实现DynamicGroupManager类来对动态组进行管理。
虽然,动态组仅仅存在于内存之中,但是,在项目需要时,我们仍然可以将其某些重要的信息持久化到数据库中存储。然后,在服务器重启时,可以从DB中加载重要的房间信息。
GGMeeting的当前版本为1.0,已经实现了上述的4个主要功能,大家可以下载源码研究下。
运行效果截图:
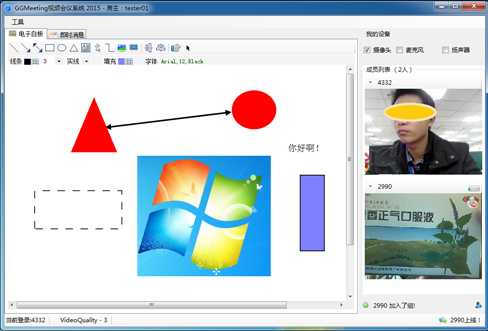
部署说明:
(1)将GGMeeting.Server部署到服务器上,并运行起来。
(2)修改Client配置文件GGMeeting.exe.config中的ServerIP的值。
(3)运行第一个Client实例,以随机帐号进入测试房间。
(4)在别的机器上继续运行Client,以随机帐号进入测试房间,大家即可在测试房间中进行视频会议。
注意:语音视频数据都是实时采集、实时播放的数据,所以测试时,服务器的带宽要求最好是独享带宽,共享带宽一般无法满足实时语音视频的要求。
________________________________________________________________________
欢迎和我探讨关于 GG 和 GGMeeting 的一切,我的QQ:2027224508,多多交流!
大家有什么问题和建议,可以留言,也可以发送email到我邮箱:ggim2013@163.com。
如果你觉得还不错,请粉我,顺便再顶一下啊
原文地址:http://blog.csdn.net/zhuweisky/article/details/45694975