标签:
起初发现了如下的现象:
mysql> show variables like ‘character%‘; +--------------------------+---------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /opt/mysql/server-5.6/share/charsets/ | +--------------------------+---------------------------------------+ mysql> show create table t4\G *************************** 1. row *************************** Table: t4 Create Table: CREATE TABLE `t4` ( `data` varchar(100) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1 mysql> insert into t4 select ‘\U+1F600‘;
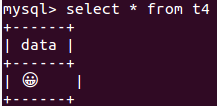
觉得很奇怪怎么latin1也支持emoji字符了呢?不是只有utf8mb4才支持吗? 于是在StackOverFlow上提问,一个网友的回答觉得有道理,回答如下:
I think you saved into and retrieved from the database a string of bytes that is interpreted by the terminal as an Unicode character. Check the output of SELECT LENGTH(data), CHAR_LENGTH(data) FROM t4 to see what‘s happening. They should return different values for multi-byte characters and the same value forlatin1. – axiac 19 hours ago
在加上无意中看到了一篇博客, 其中说道:
抛一个问题,latin1字符集的表,用户写入和读取汉字是否有问题?答案是只要合理设置,没有问题。假设SecureCRT为UTF8,character_set_client和表字符集均设置为latin1,参考第3节的分析,那么用户读取和写入数据的过程中,并不涉及字符集编码转换的问题,将UTF8的汉字字符转为二进制流写入database,提取出来后,secureCRT再将对应的二进制解码为对应的汉字,所以不影响用户的使用。
于是现在觉得上述现象很正常。
因为操作系统默认的字符集为utf8(LANG=en_US.UTF-8), 而client、connection、database均为latin1, 于是这一路(从终端界面执行insert到保存数据到表中)都没有编码转换,直接传输的是utf8编码后的二进制流。
怎么验证上述结论呢? 于是决定修改中间环节的字符集,看会发生什么?
mysql> set names gbk; mysql> show variables like ‘character%‘; +--------------------------+---------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------+ | character_set_client | gbk | | character_set_connection | gbk | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | gbk | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /opt/mysql/server-5.6/share/charsets/ | +--------------------------+---------------------------------------+ mysql> insert into t4 select ‘\U+1F600‘; ERROR 1366 (HY000): Incorrect string value: ‘\xF0\x9F\x98\x80‘ for column ‘data‘ at row 1
分析:
现在操作系统是utf8, client、connection是gbk, 字段是latin1, 因为一开始是utf8二进制流,且client和connection均为gbk,无需转码,故只在最后当保存到表字段中时需要由utf8转为latin1,由于latin1不能解码该utf8二进制流故导致了上述报错。
若将字符集不一致的情况再往前挪一步会怎样呢? 如下所示:
mysql> set character_set_connection = latin1; mysql> show variables like ‘character%‘; +--------------------------+---------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------+ | character_set_client | gbk | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | gbk | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /opt/mysql/server-5.6/share/charsets/ | +--------------------------+---------------------------------------+
现在client和connection就不一致了,就是说需要先将utf8-->gbk-->latin1, 那么现在能成功插入emoji字符吗?
mysql> insert into t4 select ‘\U+1F600‘;
可以插入,查询结果如下:
mysql> select data,hex(data) from t4; +------+-----------+ | data | hex(data) | +------+-----------+ | ?? | 3F3F | +------+-----------+
似乎在utf8-->gbk的过程中,将utf8编码后的二进制流(f0 9f 98 80)解码成了‘??’,而‘??’能被latin1成功解析。但如何通过java程序模拟上述的转换呢?
试了下面的代码 但未能成功再现。
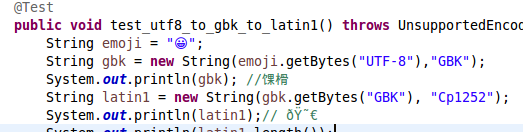
即将utf8转为gbk时未能得到‘??’,而是‘馃榾’。不知何故?
那假如将上例中的client与connection交换一下位置呢,如下所示:
mysql> show variables like ‘character%‘; +--------------------------+---------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------+ | character_set_client | latin1 | | character_set_connection | gbk | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | gbk | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /opt/mysql/server-5.6/share/charsets/ | +--------------------------+---------------------------------------+
现在的转化流变成这样了:utf8-->latin1-->gbk-->latin1, 从之前的经验似乎可以预测进行第一步转化时就应该报错(Incorrect string value: ‘\xF0\x9F\x98\x80‘ for column ‘data‘ at row 1),但实际情况是:
mysql> insert into t4 select ‘\U+1F600‘; Query OK, 1 row affected (0.01 sec) mysql> select data,hex(data) from t4; +------+-----------+ | data | hex(data) | +------+-----------+ | ?? | 3F3F | | ???? | 3F3F3F3F | +------+-----------+
并未报错仍能成功插入, 似乎只要不是最后一步往表里插入记录就不会报错,但这次变成4个问号了。
这次用java程序模拟的结果如下所示:

注:
为什么用Cp1252表示latin1?
主要是参考了该表格:
Table 5.3 MySQL to Java Encoding Name Translations

标签:
原文地址:http://my.oschina.net/zhuguowei/blog/414476