标签:
Hibernate是一个持久层框架,经常访问物理数据库。为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
Hibernate向我们提供的主要的操纵数据库的接口,Session就是其中的一个,它提供了基本的增,删,改,查方法.而且具有一个缓存机制,能够按照某个时间点,按照缓存中的持久化对象属性的变化来更新数据库,着就是Session的缓存清理过程.在Hibernate中对象分为三个状态,临时,持久化,游离.如果我们希望JAVA里的一个对象一直存在,就必须有一个变量一直引用着这个对象.当这个变量没了.对象也就被JVM回收了
Hibernate缓存包括两大类:
Hibernate一级缓存和Hibernate二级缓存。
Hibernate一级缓存又称为“Session的缓存”。
Session内置不能被卸载,Session的缓存是事务范围的缓存(Session对象的生命周期通常对应一个数据库事务或者一个应用事务)。
一级缓存中,持久化类的每个实例都具有唯一的OID。
Hibernate session就是java.sql.Connection的一层高级封装,一个session对应了一个Connection。
http请求结束后正确的关闭session(过滤器实现了session的正常关闭);延迟加载必须保证是同一个session(session绑定在ThreadLocal)。
Hibernate二级缓存又称为“SessionFactory的缓存”。
由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。
第二级缓存是可选的,是一个可配置的插件,默认下SessionFactory不会启用这个插件。
Hibernate提供了org.hibernate.cache.CacheProvider接口,它充当缓存插件与Hibernate之间的适配器。
什么样的数据适合存放到第二级缓存中?
1) 很少被修改的数据 2) 不是很重要的数据,允许出现偶尔并发的数据 3) 不会被并发访问的数据 4) 常量数据
不适合存放到第二级缓存的数据?
1) 经常被修改的数据 2) 绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发 3) 与其他应用共享的数据。
Hibernate查找对象如何应用缓存?
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;
查不到,如果配置了二级缓存,那么从二级缓存中查;
如果都查不到,再查询数据库,把结果按照ID放入到缓存删除、更新、增加数据的时候,同时更新缓存。
一级缓存与二级缓存的对比表
|
|
一级缓存 |
二级缓存 |
|
存放数据的形式 |
相互关联的持久化对象 |
对象的散装数据 |
|
缓存的范围 |
事务范围,每个事务都拥有单独的一级缓存 |
进程范围或集群范围,缓存被同一个进程或集群范围内所有事务共享 |
|
并发访问策略 |
由于每个事务都拥有单独的一级缓存不会出现并发问题,因此无须提供并发访问策略 |
由于多个事务会同时访问二级缓存中的相同数据,因此必须提供适当的并发访问策略,来保证特定的事务隔离级别 |
|
数据过期策略 |
处于一级缓存中的对象永远不会过期,除非应用程序显示清空或者清空特定对象 |
必须提供数据过期策略,如基于内存的缓存中对象的最大数目,允许对象处于缓存中的最长时间,以及允许对象处于缓存中的最长空闲时间 |
|
物理介质 |
内存 |
内存和硬盘,对象的散装数据首先存放到基于内存的缓存中,当内存中对象的数目达到数据过期策略的maxElementsInMemory值,就会把其余的对象写入基于硬盘的缓存中 |
|
缓存软件实现 |
在Hibernate的Session的实现中包含 |
由第三方提供,Hibernate仅提供了缓存适配器,用于把特定的缓存插件集成到Hibernate中 |
|
启用缓存的方式 |
只要通过Session接口来执行保存,更新,删除,加载,查询,Hibernate就会启用一级缓存,对于批量操作,如不希望启用一级缓存,直接通过JDBCAPI来执行 |
用户可以再单个类或类的单个集合的粒度上配置第二级缓存,如果类的实例被经常读,但很少被修改,就可以考虑使用二级缓存,只有为某个类或集合配置了二级缓存,Hibernate在运行时才会把它的实例加入到二级缓存中 |
|
用户管理缓存的方式 |
一级缓存的物理介质为内存,由于内存的容量有限,必须通过恰当的检索策略和检索方式来限制加载对象的数目,Session的evit()方法可以显示的清空缓存中特定对象,但不推荐 |
二级缓存的物理介质可以使内存和硬盘,因此第二级缓存可以存放大容量的数据,数据过期策略的maxElementsInMemory属性可以控制内存中的对象数目,管理二级缓存主要包括两个方面:选择需要使用第二级缓存的持久化类,设置合适的并发访问策略;选择缓存适配器,设置合适的数据过期策略。SessionFactory的evit()方法也可以显示的清空缓存中特定对象,但不推荐
|
Hibernate的缓存机制如何应用?
一级缓存的管理:
evit(Object obj) 将指定的持久化对象从一级缓存中清除,释放对象所占用的内存资源,指定对象从持久化状态变为脱管状态,从而成为游离对象。
clear() 将一级缓存中的所有持久化对象清除,释放其占用的内存资源。
contains(Object obj) 判断指定的对象是否存在于一级缓存中。
flush() 刷新一级缓存区的内容,使之与数据库数据保持同步。
一级缓存应用
save()。当session对象调用save()方法保存一个对象后,该对象会被放入到session的缓存中。
get()和load()。当session对象调用get()或load()方法从数据库取出一个对象后,该对象也会被放入到session的缓存中。
使用HQL和QBC等从数据库中查询数据。
public class Client { public static void main(String[] args) { Session session = HibernateUtil.getSessionFactory().openSession(); Transaction tx = null; try { /*开启一个事务*/ tx = session.beginTransaction(); /*从数据库中获取id="402881e534fa5a440134fa5a45340002"的Customer对象*/ Customer customer1 = (Customer)session.get(Customer.class, "402881e534fa5a440134fa5a45340002"); System.out.println("customer.getUsername is"+customer1.getUsername()); /*事务提交*/ tx.commit(); System.out.println("-------------------------------------"); /*开启一个新事务*/ tx = session.beginTransaction(); /*从数据库中获取id="402881e534fa5a440134fa5a45340002"的Customer对象*/ Customer customer2 = (Customer)session.get(Customer.class, "402881e534fa5a440134fa5a45340002"); System.out.println("customer2.getUsername is"+customer2.getUsername()); /*事务提交*/ tx.commit(); System.out.println("-------------------------------------"); /*比较两个get()方法获取的对象是否是同一个对象*/ System.out.println("customer1 == customer2 result is "+(customer1==customer2)); } catch (Exception e) { if(tx!=null) { tx.rollback(); } } finally { session.close(); } } }
结果
Hibernate: select customer0_.id as id0_0_, customer0_.username as username0_0_, customer0_.balance as balance0_0_ from customer customer0_ where customer0_.id=? customer.getUsername islisi ------------------------------------- customer2.getUsername islisi ------------------------------------- customer1 == customer2 result is true
输出结果中只包含了一条SELECT SQL语句,而且customer1 == customer2 result is true说明两个取出来的对象是同一个对象。其原理是:第一次调用get()方法, Hibernate先检索缓存中是否有该查找对象,发现没有,Hibernate发送SELECT语句到数据库中取出相应的对象,然后将该对象放入缓存中,以便下次使用,第二次调用get()方法,Hibernate先检索缓存中是否有该查找对象,发现正好有该查找对象,就从缓存中取出来,不再去数据库中检索。
session关闭方案
采用getCurrentSession()创建的session在commit或rollback时会自动关闭
而采用openSession(),创建的session必须手动关闭
二级缓存的管理:
evict(Class arg0, Serializable arg1)将某个类的指定ID的持久化对象从二级缓存中清除,释放对象所占用的资源。
sessionFactory.evict(Customer.class, new Integer(1));
evict(Class arg0) 将指定类的所有持久化对象从二级缓存中清除,释放其占用的内存资源。
sessionFactory.evict(Customer.class);
evictCollection(String arg0) 将指定类的所有持久化对象的指定集合从二级缓存中清除,释放其占用的内存资源。
sessionFactory.evictCollection("Customer.orders");
常用的二级缓存插件
EHCache org.hibernate.cache.EhCacheProvider
OSCache org.hibernate.cache.OSCacheProvider
SwarmCahe org.hibernate.cache.SwarmCacheProvider
JBossCache org.hibernate.cache.TreeCacheProvider
启用二级缓存插件
<!-- EHCache的配置,hibernate.cfg.xml --> <hibernate-configuration> <session-factory> <!-- 设置二级缓存插件EHCache的Provider类--> <property name="hibernate.cache.provider_class"> org.hibernate.cache.EhCacheProvider </property> <!-- 启动"查询缓存" --> <property name="hibernate.cache.use_query_cache"> true </property> </session-factory> </hibernate-configuration>
缓存xml配置EHCACHE为例
<!-- ehcache.xml --> <?xml version="1.0" encoding="UTF-8"?> <ehcache> <!-- 缓存到硬盘的路径 --> <diskStore path="d:/ehcache"></diskStore> <!-- 默认设置 maxElementsInMemory : 在內存中最大緩存的对象数量。 eternal : 缓存的对象是否永远不变。 timeToIdleSeconds :可以操作对象的时间。 timeToLiveSeconds :缓存中对象的生命周期,时间到后查询数据会从数据库中读取。 overflowToDisk :内存满了,是否要缓存到硬盘。 --> <defaultCache maxElementsInMemory="200" eternal="false" timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></defaultCache> <!-- 指定缓存的对象。 下面出现的的属性覆盖上面出现的,没出现的继承上面的。 --> <cache name="com.suxiaolei.hibernate.pojos.Order" maxElementsInMemory="200" eternal="false" timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></cache> </ehcache>
标记需要使用二级缓存模型包括使用二级缓存的并发策略等(在每个.hbm.xml中)
<!-- *.hbm.xml --> <?xml version="1.0" encoding=‘UTF-8‘?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" > <hibernate-mapping> <class> <!-- 设置该持久化类的二级缓存并发访问策略 read-only read-write nonstrict-read-write transactional--> <cache usage="read-write"/> </class> </hibernate-mapping>
若存在一对多的关系,想要在在获取一方的时候将关联的多方缓存起来,需要在集合属性下添加<cache>子标签,这里需要将关联的对象的hbm文件中必须在存在<class>标签下也添加<cache>标签,不然Hibernate只会缓存OID。
<hibernate-mapping> <class name="com.suxiaolei.hibernate.pojos.Customer" table="customer"> <!-- 主键设置 --> <id name="id" type="string"> <column name="id"></column> <generator class="uuid"></generator> </id> <!-- 属性设置 --> <property name="username" column="username" type="string"></property> <property name="balance" column="balance" type="integer"></property> <set name="orders" inverse="true" cascade="all" lazy="false" fetch="join"> <cache usage="read-only"/> <key column="customer_id" ></key> <one-to-many class="com.suxiaolei.hibernate.pojos.Order"/> </set> </class> </hibernate-mapping>
session的缓存机制
当Session的save()方法持久化一个Customer对象时,Customer对象被加入到Session的缓存中,以后即使应用程序中的引用变量不再引用Customer对象,只要Session的缓存还没有被清空,Customer对象仍然处于生命周期中。 当Session的load()方法试图从数据库中加载一个Customer对象时,Session先判断缓存中是否已经存在这个Customer对象,如果存在,就不需要再到数据库中检索。 这样就大大提高了hibernate查询的时间效率,只有当事务提交,session关闭之后,session缓存才会失效
下面我们来通过一段代码来理解一下session缓存:
tx = session.beginTransaction(); Customer c1=new Customer(“zhangsan",new HashSet()); //Customer对象被持久化,并且加入到Session的缓存中 session.save(c1); Long id=c1.getId(); //c1变量不再引用Customer对象 c1=null; //从Session缓存中读取Customer对象,使c2变量引用Customer对象 Customer c2=(Customer)session.load(Customer.class,id); tx.commit(); //关闭Session,清空缓存 session.close(); //访问Customer对象 System.out.println(c2.getName()); // c2变量不再引用Customer对象,此时Customer对象结束生命周期。 c2=null;
当session调用save保存一个对象时,这个对象就被加载到session缓存当中,其实调用save方法这里有个细节,很多人都忽略了这个细节,就是save方法有一个返回值,返回一个seriaseble接口类型的数据,我们知道像基本数据类型的包装类型都实现了这个接口,其实这个返回值我们可以理解为保存对象的id,我们在很多时候都能用到这个返回值,这是一个应该注意的地方。当对象被save到缓存中时,我们就可以调用对象的getid方法来获得他的id了。在上面的示例中我们可以看到,虽然c1被复位null了,但是此时在session缓存里面还是有一个变量指向着该对象,所以该对象才不被垃圾回收器回收,当我们在此利用该对象的id去用load查询时,其实还是去到session缓存去找并且返回该对象,当session关闭后。缓存清空。
下面我们在来看一个例子,来看一下get和load的另一个不同点:
tx = session.beginTransaction(); Customer c1=(Customer)session.load(Customer.class,new Long(1)); Customer c2=(Customer)session.load(Customer.class,new Long(1)); System.out.println(c1==c2); // true or false ?? tx.commit(); session.close();
很明显,这个示例最后打印出来的是true,因为他们获得的是同一个实例,我们具体来分析一下,我们在运行这段代码时,细心的童鞋应该会发现,利用load去查询对象时,没有生成sql语句,这是为什么呢?既然查询到结果了,为什么没有生成出来sql语句呢。这就是我们要说的load和get方法的第二个不同的地方了,load方法在查询时,其实是获得的该对象的一个代理的对象,当我们用到查询到的对象时,他才会去数据库进行查询,如上,如果我们调用c1.getName方法,这时就会打印出sql语句来,这时候他才真正的去数据库查询,而get方法,他在执行get的方法的时候就会去数据库查询,产生sql语句
Session缓存的作用
(1)减少访问数据库的频率。应用程序从内存中读取持久化对象的速度显然比到数据库中查询数据的速度快多了,因此Session的缓存可以提高数据访问的性能。
(2)保证缓存中的对象与数据库中的相关记录保持同步。当缓存中持久化对象的状态发生了变化,Session并不会立即执行相关的SQL语句,这使得Session能够把几条相关的SQL语句合并为一条SQL语句,以便减少访问数据库的次数,从而提高应用程序的性能。
Session的清理缓存
清理缓存是指按照缓存中对象的状态的变化来同步更新数据库,下面我们还是具体来看一段代码:以下程序代码对Customer的name属性修改了两次:
tx = session.beginTransaction(); Customer customer=(Customer)session.load(Customer.class, new Long(1)); customer.setName("Jack"); customer.setName("Mike"); tx.commit();
当Session清理缓存时,只需执行一条update语句:
update CUSTOMERS set NAME= ‘Mike‘…… where ID=1;
其实第一次调用setName是无意义的,完全可以省略掉。
Session缓存在什么时候才清理?
Session会在下面的时间点清理缓存:
1.当应用程序调用org.hibernate.Transaction的commit()方法的时候,commit()方法先清理缓存,然后再向数据库提交事务。
2.当应用程序显式调用Session的flush()方法的时候,其实这个方法我们几乎很少用到,因为我们一般都是在完成一个事务才去清理缓存,提交数据更改,这样我们直接提交事务就可以。
Hibernate中java对象的三种状态:
1、临时状态(transient):刚刚用new语句创建,还没有被持久化,不处于Session的缓存中。处于临时状态的Java对象被称为临时对象。
2、持久化状态(persistent):已经被持久化,加入到Session的缓存中。处于持久化状态的Java对象被称为持久化对象。
3、游离状态(detached):已经被持久化,但不再处于Session的缓存中。处于游离状态的Java对象被称为游离对象。
持久化状态和临时状态的不同点在于:
1、对象持久化状态时,他已经和数据库打交道了,在数据库里面存在着该对象的一条记录。
2、持久化状态的对象存在于session的缓存当中。
3、持久化状态的对象有自己的OID。
游离状态的对象与持久化状态的对象不同体现在游离状态的对象已经不处于session的缓存当中,并且在数据库里面已经不存在该对象的记录,但是他依然有自己的OID。
对象的状态转换
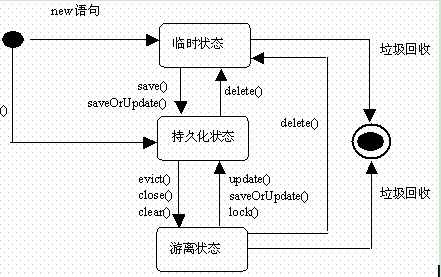
我们一起来分析一下这个状态转换图,首先一个对象被new出来之后,他是出于临时状态的,然后调用save或者saveOrUpdate方法把对象转换为持久化状态,这里的saveOrUpdate方法其实是一个偷懒的方法,我们以前用的所有的save方法的地方都可以修改为该方法,这个方法是在保存数据之前先查看一下这个对象是什么状态,如果是临时状态就保存,如果是游离状态就进行更新。持久化状态转换成游离状态可以是在session关闭或者被清理缓存时,在或者就是调用evict方法,这个方法就是强行把对象从session缓存中清除。游离状态装换为持久化状态可以调用update方法,其实update方法主要的功能就是把对象从游离状态装换成持久化状态的,因为一般的更新其实不用这个方法也可以。
下面我们举一个具体实例的看一下状态转换过程:
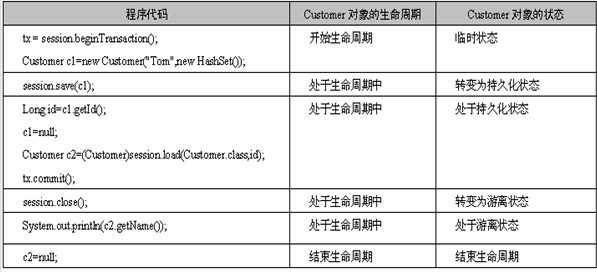
这个图需要大家仔细的理解一下,他很好的体现了对象生命周期的进程和对象状态的转换。
下面我们在用一个示例来看一下session的update方法是怎么把一个游离状态的对象装换成持久化的:
Customer customer=new Customer(); customer.setName("Tom"); Session session1=sessionFactory.openSession(); Transaction tx1 = session1.beginTransaction(); session1.save(customer); tx1.commit(); session1.close(); //此时Customer对象变为游离对象 Session session2=sessionFactory.openSession(); Transaction tx2 = session2.beginTransaction(); customer.setName(“zhangsan") //在和session2关联之前修改Customer对象的属性 session2.update(customer); customer.setName(“lisi"); //在和session2关联之后修改Customer对象的属性 tx2.commit(); session2.close();
当session1保存完对象,然后事务关闭时,对象就变为游离状态了,此时我们在打开一个session,利用update方法,在把对象和session关联起来,然后修改他的属性,提交事务之后,游离状态的对象一样可以修改保存到数据库中,这里虽然修改了两次对象的属性,但只会发送一条sql语句,因为update在修改对象数据时,只有在事务提交时,他才会发送sql语句进行提交。所以只有最后一条修改信息管用。
总结一下Session的update()方法完成以下操作:
(1)把Customer对象重新加入到Session缓存中,使它变为持久化对象。
(2)计划执行一个update语句。值得注意的是,Session只有在清理缓存的时候才会执行update语句,并且在执行时才会把Customer对象当前的属性值组装到update语句中。因此,即使程序中多次修改了Customer对象的属性,在清理缓存时只会执行一次update语句。
Web应用程序客户层和业务逻辑层之间传递临时对象和有利对象的过程:
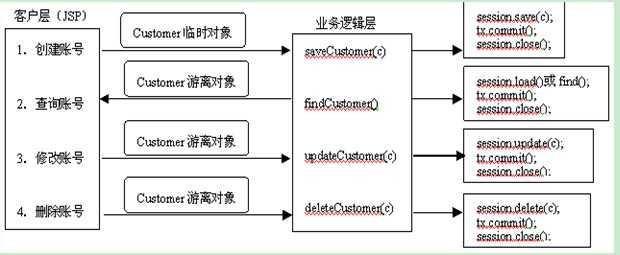
标签:
原文地址:http://www.cnblogs.com/hwaggLee/p/4502168.html