标签:des class blog code http tar
在以前的项目中周公曾有解析HTML的情况,当时是采用正则表达式一步步将无关的HTML注释及JS代码部分删除掉,然后再用正则表达式找出需要提取的部分,可以说使用正则表达式来做是一个比较繁琐的过程,特别是对于正则表达式不是很熟悉或者要处理的HTML很复杂的情况下。前一阵子周公还是通过这个办法将http://wz.csdn.net/zhoufoxcn上保存的网址导入到http://cang.baidu.com,本来还想将周公博客上的文章好好整理一下,但是考虑到使用正则真的是很繁琐也很麻烦,所以就一直没有动手。
直到前两天在网上发现了一个.NET下的HTML解析类库HtmlAgilityPack。HtmlAgilityPack是一个支持用XPath来解析HTML的类库,在花了一点时间学习了解HtmlAgilityPack的API和XPath之后,周公就做了一个简单的工具完成了这个功能,目前在CSDN上周公博文的收集地址为:http://blog.csdn.net/zhoufoxcn/archive/2011/06/23/6564578.aspx,在51CTO上周公博文的收集地址为http://zhoufoxcn.blog.51cto.com/792419/595327。HtmlAgilityPack是一个开源的.NET类库,它的主页是http://htmlagilitypack.codeplex.com/,在这里可以下载到最新版的类库及API手册,此外还可以下载到一个用于调试的辅助工具。
XPath简明介绍
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
下面列出了最有用的路径表达式:
nodename:选取此节点的所有子节点。
/:从根节点选取。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.:选取当前节点。
..:选取当前节点的父节点。
例如有下面一段XML:
- <?xml version="1.0" encoding="utf-8"?>
- <Articles>
- <Article>
- <Title>在ASP.NET中使用Highcharts js图表</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/537324</Url>
- <CreateAt type="en">2011-04-07</price>
- </Article>
- <Article>
- <Title lang="eng">Log4Net使用详解(续)</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2010/11/23/6029021.aspx</Url>
- <CreateAt type="zh-cn">2010年11月23日</price>
- </Article>
- <Article>
- <Title>J2ME开发的一般步骤</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2011/06/12/6540223.aspx</Url>
- <CreateAt type="zh-cn">2011年06月12日</price>
- </Article>
- <Article>
- <Title lang="eng">PowerDesign高级应用</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/166415</Url>
- <CreateAt type="zh-cn">2007-09-08</price>
- </Article>
- </Articles>
针对上面的XML文件,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
/Articles/Article[1]:选取属于Articles子元素的第一个Article元素。
/Articles/Article[last()]:选取属于Articles子元素的最后一个Article元素。
/Articles/Article[last()-1]:选取属于Articles子元素的倒数第二个Article元素。
/Articles/Article[position()<3]:选取最前面的两个属于 bookstore 元素的子元素的Article元素。
//title[@lang]:选取所有拥有名为lang的属性的title元素。
//CreateAt[@type=‘zh-cn‘]:选取所有CreateAt元素,且这些元素拥有值为zh-cn的type属性。
/Articles/Article[Order>2]:选取Articles元素的所有Article元素,且其中的Order元素的值须大于2。
/Articles/Article[Order<3]/Title:选取Articles元素中的Article元素的所有Title元素,且其中的Order元素的值须小于3。
HtmlAgilityPack API简明介绍
在HtmlAgilityPack中常用到的类有HtmlDocument、HtmlNodeCollection、
HtmlNode和HtmlWeb等。
其流程一般是先获取HTML,这个可以通过HtmlDocument的Load()或LoadHtml()来加载静态内容,或者也可以HtmlWeb的Get()或Load()方法来加载网络上的URL对应的HTML。
得到了HtmlDocument的实例之后,就可以用HtmlDocument的DocumentNode属性,这是整个HTML文档的根节点,它本身也是一个HtmlNode,然后就可以利用HtmlNode的SelectNodes()方法返回多个HtmlNode的集合对象HtmlNodeCollection,也可以利用HtmlNode的SelectSingleNode()方法返回单个HtmlNode。
HtmlAgilityPack实战
下面是一个解析CSDN博客的代码实例:
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
-
- namespace CrawlPageApplication
- {
-
-
-
-
-
-
- public class CSDN_Parser
- {
- private const string CategoryListXPath = "//html[1]/body[1]/div[1]/div[1]/div[2]/div[1]/div[1]/dl[1]/dd[3]/div[1]/ul[1]/li";
- private const string CategoryNameXPath = "//li[1]/a[2]";
-
-
-
-
-
-
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory=null;
- List<Category> list = new List<Category>(40);
-
- HtmlDocument document = new HtmlDocument();
-
-
-
- document.Load("CSDN_index.html", Encoding.UTF8);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat=category.IndexUrl+"?PageNumber={0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- return list;
- }
-
- }
- }
当然实现类似的解析51CTO的博客文章数据的代码如下:
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
-
- namespace CrawlPageApplication
- {
-
-
-
-
-
-
- public class CTO_Parser
- {
- private static Encoding PageEncoding = Encoding.GetEncoding("gb2312");
- private static readonly Uri UriBase = new Uri("http://zhoufoxcn.blog.51cto.com");
- private static string CategoryListXPath = "/html[1]/body[1]/div[5]/div[1]/div[1]/div[2]/ul[1]/li";
- private static string CategoryNameXPath = "/li[1]/a[1]";
-
-
-
-
-
-
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory = null;
- List<Category> list = new List<Category>(40);
-
- HtmlDocument document = new HtmlDocument();
-
-
- document.Load("51cto_index.html", PageEncoding);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- if (temp.SelectSingleNode(CategoryNameXPath).InnerText != "全部文章")
- {
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat = category.IndexUrl + "/page/{0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- }
- return list;
- }
- }
- }
在上面的代码中出现了一个Category类,该类的定义如下:
为了鼓励大家动手尝试以及在本项目中使用了周公的私家类库,所以不提供全部源代码下载,这里提供周公操作的最终软件界面:
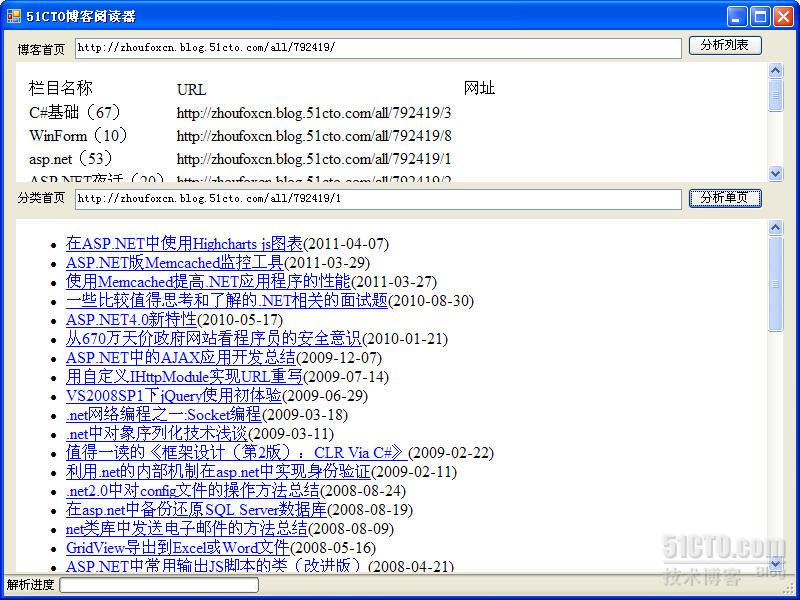
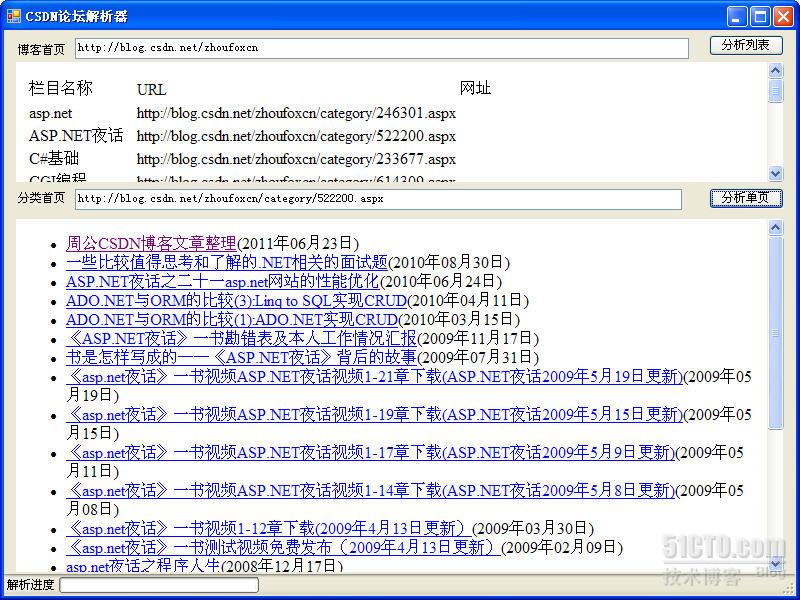
总结:HtmlAgilityPack确实是一个功能强大、体积小的开源HTML解析类库,在本篇仅仅是介绍了其中几个类的用法,但光这些就足以供周公快速实现了许久没有实现的功能,如果让周公用正则表达式来实现类似的功能,时间肯定要比用这个长得多。
说明:周公最近也在琢磨一些关于微博的应用,如果有相同爱好者或者在使用微博的读者,请围观周公的微博,网址是:http://weibo.com/zhoufoxcn。
2011-06-24
周公
本文出自 “周公(周金桥)的专栏” 博客,请务必保留此出处http://zhoufoxcn.blog.51cto.com/792419/595344
HTML解析利器HtmlAgilityPack,布布扣,bubuko.com
HTML解析利器HtmlAgilityPack
标签:des class blog code http tar
原文地址:http://www.cnblogs.com/soundcode/p/3785161.html