标签:
一般的网站都会有都会有搜索的功能,一般实现搜索主要有三种方案
第一种是最差的,也是最不推荐的,使用数据库的模糊查询例如select * form table where 字段 like XXX,这种查询的缺点很明显:
(1) 无法查找几个关键词不连在一起的情况
(2) 全表扫描 效率低下
第二种:使用SqlServer的全文本检索功能
举例:select * form table where msg = ‘江苏南京’
这是就可以写成select * form table where msg.contains(‘江苏南京’);
这样搜索出来的结果就可以既包含江苏也可以包含南京,并且匹配的速度也快,还可以实现分词。
缺点:
(1):只有正版的SqlServer才支持上面的技术
(2):数据库的分词不太灵活,不能自己修改词库
第三种:使用lucene.Net(本文重点讲解)
Lucene.Net只是一个全文检索开发包,不是一个成熟的搜索引擎,他的功能就是:将数据交给Lucene.Net, 查询数据的时候从Lucene.Net查询数据,可以看成是一个提供了全文检索功能的数据库,lucene.net只对文本信息进行检索,如果不是文本信息,要转换为文本信息。lucene会将扔给他的词切词保存,因为是保存的时候分词(切词),所以搜索速度非常快。
分词是搜索结果好坏的关键:
lucene不同的分词算法就是不同的类,所有的分词算法类都从Analyzer类继承,不同的分词算法有不同的优缺点。
例如:内置的StandardAnalyzer是将英文按照空格,标点符号等进行分词,讲中文按照单个字进行分词,一个汉字算一个词(就是所谓的一元分词)
二元分词:每两个汉字算一个单词,“欢迎你们大家”会分为“欢迎”,迎你,你们,们大,大家 要在网上下载一个二元分词的算法:CJKAnalyzer
基于词库的分词算法:基于一个词库进行分词,可以提高分词的成功率,有庖丁解牛,盘古分词等。效率低(相对于一元分词与二元分词)但准确度较高
注意:lucene.Net对汉语的分词效果不好,需要借助于第三方的分词算法:开源的盘古分词(可以在开源中国社区下载,里面有详细的Demo,以及dll文件)
编写代码如下(体验盘古分词):
在中国开源社区下载Pangu分词forLucene
第一步:将WebDemo里的bin文件夹下的Dictionaries文件夹复制到项目的根目录下,然后改文件夹名为Dict并设置里面的内容的属性的如果较新则复制到输出目录
第二部:添加引用Lucene.net.dll文件和PanGu.Lucene.Analyzer.dll文件
Analyzer analyzer = new Lucene.Net.Analysis.PanGu.PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new System.IO.StringReader("北京,Hi欢迎你们大家"));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
ListBox1.Items.Add(token.TermText());
}
既然是分词,那就肯定有词库,有词库就可以修改,使用刚才的Bin文件夹下的PanGu.Lucene.ImportTool.exe文件打开词库修改词库的内容,就可以实现最新的分词效果。
可以理解为:
先建立一个索引系统,然后打开索引系统,使用lucene的IndexWriter类向里面写入索引(document对象),该对象从盘古分词对已有的文章的分词得到
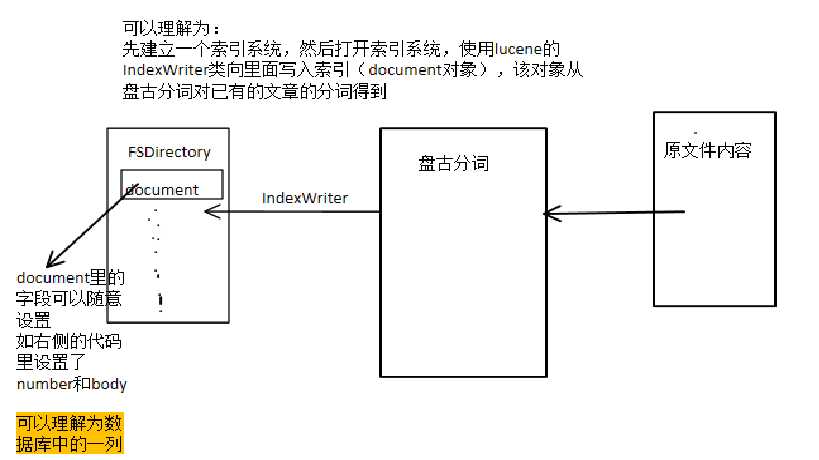
基本思想如上图
lucene+PanGu
建立lucene词库:(将数据交给lucene,使用Pangu分词),并实现搜索的功能(第二段代码)
1 protected void Button4_Click(object sender, EventArgs e) 2 { 3 string indexPath = Server.MapPath(@"/Demo/lucenedir");//注意和磁盘上文件夹的大小写一致,否则会报错。将创建的分词内容放在该目录下。 4 5 //指定索引文件(打开索引目录) FS指的是就是FileSystem 我的理解:索引系统 6 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory()); 7 8 //IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在。 9 bool isUpdate = IndexReader.IndexExists(directory); 10 if (isUpdate) 11 { 12 //同时只能有一段代码对索引库进行写操作。当使用IndexWriter打开directory时会自动对索引库文件上锁。 13 //如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁 14 //(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决) 15 if (IndexWriter.IsLocked(directory)) 16 { 17 IndexWriter.Unlock(directory); 18 } 19 } 20 21 //向索引库中写索引。这时在这里加锁。 22 IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED); 23 for (int i = 1; i <= 10; i++) 24 { 25 string txt = File.ReadAllText(Server.MapPath(@"/Demo/测试文件/" + i + ".txt"), System.Text.Encoding.Default);//注意这个地方的编码 26 Document document = new Document();//表示一篇文档。 27 //Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number")取出值来.Field.Index. NOT_ANALYZED:不进行分词保存 28 document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); 29 30 //Field.Index. ANALYZED:进行分词保存:也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询) 31 32 //Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离。 33 document.Add(new Field("body", txt, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS)); 34 writer.AddDocument(document); 35 36 } 37 writer.Close();//会自动解锁。 38 directory.Close();//不要忘了Close,否则索引结果搜不到 39 }
1 protected void Button5_Click(object sender, EventArgs e) 2 { 3 //创建的分词的内容所存放的目录 4 string indexPath = Server.MapPath(@"/Demo/lucenedir"); ; 5 string kw = "C#"; 6 kw = kw.ToLower(); 7 8 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); 9 IndexReader reader = IndexReader.Open(directory, true); 10 IndexSearcher searcher = new IndexSearcher(reader); 11 12 //搜索条件 13 PhraseQuery query = new PhraseQuery(); 14 //foreach (string word in kw.Split(‘ ‘))//先用空格,让用户去分词,空格分隔的就是词“计算机 专业” 15 //{ 16 // query.Add(new Term("body", word)); 17 //} 18 //query.Add(new Term("body","语言"));--可以添加查询条件,两者是add关系.顺序没有关系. 19 // query.Add(new Term("body", "大学生")); 20 query.Add(new Term("body", kw));//body中含有kw的文章 21 query.SetSlop(100);//多个查询条件的词之间的最大距离.在文章中相隔太远 也就无意义.(例如 “大学生”这个查询条件和"简历"这个查询条件之间如果间隔的词太多也就没有意义了。) 22 //TopScoreDocCollector是盛放查询结果的容器 23 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true); 24 searcher.Search(query, null, collector);//根据query查询条件进行查询,查询结果放入collector容器 25 26 //得到所有查询结果中的文档,GetTotalHits():表示总条数 TopDocs(300, 20);//表示得到300(从300开始),到320(结束)的文档内容. 27 //可以用来实现分页功能 28 ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs; 29 this.ListBox1.Items.Clear(); 30 for (int i = 0; i < docs.Length; i++) 31 { 32 //搜索ScoreDoc[]只能获得文档的id,这样不会把查询结果的Document一次性加载到内存中。 33 //降低了内存压力,需要获得文档的详细内容的时候通过searcher.Doc来根据文档id来获得文档的详细内容对象Document. 34 //得到查询结果文档的id(Lucene内部分配的id) 35 int docId = docs[i].doc; 36 37 //找到文档id对应的文档详细信息 38 Document doc = searcher.Doc(docId); 39 40 // 取出放进字段的值 41 this.ListBox1.Items.Add(doc.Get("number") + "\n"); 42 this.ListBox1.Items.Add(doc.Get("body") + "\n"); 43 this.ListBox1.Items.Add("-----------------------\n"); 44 } 45 }
注意事项:搜索的时候是区分大小写的,要想不区分,可以在建立词库的时候直接将所有的词都转换为大写或小写的,搜索的时候做出相应的转换即可
标签:
原文地址:http://www.cnblogs.com/yzgyjyw/p/4504557.html