标签:
InputFormat是用来对我们的输入数据进行格式化的.TextInputFormat是默认的.
DBInputFormat,DelegatingInputFormat,FileInputFormat,常用的就是DBInputFormat,FileInputFormat .
DBInputFormat:接我们的关系型数据库的,比如mysql和oracle,
FileInputFormat是和文件相关的,又有很多子类:
最常见的就是我们的TextInputFormat,最常见的是处理我们普通的文件文件,一行是一条记录的情况下.还有
CombinerFileInputFormat:指的是有多个输入文件,意味着这些文件的输入格式会不一样,如果输入格式是相同的格式内容的话,用原来讲的,只要把输入的路径指定一个目录,那么里边多个文件就同时被处理.CombineFileInputFormat指的是可能格式不一样.比如里边有普通文件,还有SequenceFile文件,这样就不好确定是使用TextFile或者是SequenceFile,这样就可以使用CombineFileInputFormat.使用CombinerFileInputFormat可以指定,对于哪些文件,记录,使用不同的处理格式,也就是说包括这两种处理格式的方法.
KeyValueTextInputFormat:和TextInput不同,TextInputFormat中的key表示的是行的偏移量,单位是字节,我们的value是我们行文本的内容.KeyValueTextInputFormat看样子属于TextInputFormat的一个子类.表示key和value是通过第一个制表符划分的.
NLineInputFormat:指的是把多少行作为一条记录,默认的TextInputFormat是一行一个记录,NLineInputFormat可以指定2行是一条记录还是3行是一条记录.
SequenceFileInputFormat:数据存放格式叫SequenceFile,不是我们普通的文本文件.是hadoop中自己定义的一种格式.是一种比较高效的数据存储格式.这里的高效指的是存储更节省空间,并且他的处理效率也不低.
key,value的值不一样,TextInputFormat它的key的值是行的偏移量,value值是行文本内容.后边的KeyValueInputFormat是根据这一行中第一个制表符划分出来的.
每一个split是根据我们的文件长度进行划分的,按照默认InputSplit和block的大小是一致的,所以是按照文件进行划分的.这里边文件的行有可能特别大,也有可能特别小,这一行一条记录有的特别长,有的特别短,所以每一个InputSplit处理的数据量,一行一行的记录是不一样的.
NLineInputFormat就是用来指定我们平均几行放到一起,相对于TextInputFormat而言,处理的粒度更粗了,因为是多行放在一起.相对而言执行起来,会快一些.
KeyValueTextInputFormat应该是和数据有关的,我们拿过来的数据,有的是使用制标符进行划分的,一般使用TextInputFormat的时候指的我们的记录是被处理过的,统一使用逗号分隔,或者是统一使用制表符分隔.
CombinerFileInputFormat它的格式指的是多种格式在一起.
SequenceFileInputFormat数据特点,数据格式与前边的是不一样的,
DBOutputFormat:指的是要写到数据库中,框架sqoop就是把数据写出到数据库中,使用DBOutputFormat.
FileOutputFormat:是我们使用的最多的,课堂上使用的是TextInputFormat.SequenceFileOutputFormat:也是数据格式不一样.
FilterOutputFotmat,
NullOutputFormat:指的是什么都不输出,有可能是只做处理,或这是使用其他的格式输出出去.
我们说的InputSplit是在MapReduce中,map阶段,每个map任务单独处理的一个数据单位.默认情况下,与block一样大.
InputSplit是我们MapReduce范畴,在hdfs中叫block.可以决定单个map任务处理的数据量大小,在前边wordCount例子中使用的是InputSplit的一个子类,叫FileInputSplit.
InputSpit的大小这个是可以配置的.产生是各个作业都不一样.
jobtracker是一个RPC的服务端,服务端的话就有对外开放的接口,那些接口中有哪些函数,JobSubmissionProtocol和TaskTrackerProtocol接口.
JobSubmissionProtocol是我们客户端用来把作业提交给JobTracker的,里边有submit方法,有getJobId方法.
TaskTrackerProtocol接口是TaskTracker与JobTracker通信用的.有个很重要的方法,sendheatbeat发送心跳.
taskTracker是我们MapReduce的客户端,主从式结构从的那部分,在我们的mapReduce中可以有很多的节点.taskTracker是用来接收JobTracker发送的指令.并且执行任务的.
我们跑的一次程序就是一个Job.job在运行的时候,至少划分为mapTask和ReduceTask,Task是Job运行作业重要的组成部分.只有不同的task连续运行完之后,那么我们的job才会运行完.
hadoop有容错机制.在mapred-default.xml文件中会有mapreduce的一个重试机制,就是说当一个maptask和一个reducetask执行的时候失败了,失败了之后,jobtracker还是会发送命令让它再次执行,应该是重试4次,如果4次都失败了这个job任务就真失败了.mapred.map.max.attemps设置的就是mapred中每一个map任务最大的尝试次数.mapred.reduce.max.attempts设置的是reduce的重试机制.
放弃之后不会去别的机器上启动task.
我们的多个map和多个reduce运行的时候,如果有一个map任务运行特别慢,它拖累了整个运行的速度的话,那么我们hadoop就会检测这个程序在相同时间内处理的数据量太少了,以后可能会处理不完,hadoop就会在其他节点起一个程序,来处理相同的数据,看谁处理的快,谁快就用谁的结果.跑的慢的那个就被杀死了.推测执行有的时候是好的,有的时候是差的.
在hive中通常会去关闭推测式执行,因为它会占用很多的资源.
mapreduce的推测式执行配置:map配置mapred.map.task.speculative.execution,如果为true就会有很多的map任务实例会被并行执行reduce设置:mapred.reduce.tasks.speculative.execution.
hadoop job 回车就会打印出很多的子命令出来
-submit 提交一个任务
-status 查询命令的状态
-counter 看命令执行数量
-kill 杀死一个任务
-list 列出所有的任务
-list-task 杀死某个任务
-fail-task 使某个任务失效的
-history 是查看作业的运行日志.
hadoop job -list:查看所有任务列表
hadoop job -kill:杀死一个任务
hadoop权限默认与linux权限几乎差不多,功能比较弱,真的要在生产环境中使用hadoop的话,会结合外面的一个安全的机制,单独去部署它,才能使用.
MapReduce读取我们的HDFS内容,把每一行转换成一个个的键值对,供map函数来使用,
我们的数据是放在hdfs中的,如果我们使用命令行的方式查看的话,里边可能有好几个文件,假设有三个文件,后边的mapreduce在运行的时候,需要接受这边输入文件的内容,我们知道,在mapreduce这个框架中,我们接收的传递过来的数据是<k1,v1>键值对,那么我们的数据文件是如何转化为<k1,v1>键值对的?
要想将数据转化为一个个的键值对需要有一个解析器,这个解析器的作用就是把数据里边的每一行转化成一个个的键值对,只需要确定行是什么,键是什么就可以把我们一行转化为键值对了.这个事情是让RecordRead来做的.
RecordRead作用:把我们输入数据文本文件中每一行转换为一个个的键值对.行数据从hdfs中数据中来,在hdfs中存的数据是海量数据,上T的规模,RecordRead到底取哪些数据?我们在对hdfs原始数据进行处理的时候还需要对原始数据做一下划分,划分成一个个的小单位,一个小单位供一个map来处理,这个小单位就叫做InputSplit.
InputSplit就是我们mapreduce对hdfs数据的划分.一个InputSplit默认情况下对应一个block,,每一个InputSplit对应一个map.
这样我们就将原始数据划分成一个个的InputSplit,每一个InputSplit交给一个map处理.可以看出我们的hdfs中的数据和我们的mapreduce其实不是多搭界,关系不是特别明显,因为我们的数据就是存放在hdfs中的,InputSplit这个概念是属于mapreduce这个领域的,我们的InputSplit是对原始数据的一个拆分,每一个InputSplit对应一个map,这样就会实现一个分布式的计算.如果我们的原始数据不是hdfs而是关系型数据库,那么我们也可以做一个转换工具,使用InputSplit去封装我们数据库中的数据,这样到了我们mapreduce领域,InputSplit又可以和map做映射,如果是数据库的话,里边可能对应一张表,InputSplit和RecordRead是我们mapReduce领域数据处理阶段非常重要的概念.
InputSplit的作用是对原始输入数据的一个封装,封装的是外部数据源中的数据,RecordRead就是做转换的,把我们的InputSplit转换为一个个的键值对就达到目的了.如果指的是hdfs,默认是block,在我们mapreduce看来,如果我们的输入是hdfs的话,hdfs就是一个完整的东西,在我们的mapreduce看来,hdfs这块不知道有没有什么block,没有这个概念,InputSplit中的数据就是从我们的hdfs中拿来.在我们的hdfs看来,mapreduce就是输入hdfs的一个客户端.所以hdfs有什么block不需要知道,仅仅是block的大小和InputSplit大小是一致的,仅此而已.
在我们的默认的数据源通常是使用hdfs做为默认的数据源.也可以用关系型数据库,也可以使用一些数据流作为数据源,都可以.
InputSplit就是对不同输入源的一个封装,所以InputSplit是有子类的.recordReader是把我们每一个InputSplit中的每一个数据单位转换成一个键值对,但是我们大部分用的是一个InputSplit的文本型的,如果我们的原始文件要求2行转换为1个键值对的话,需要我们RecordRead定制.压缩文件也是用RecordRead去做处理,RecordRead必须要知道原始输入数据的内容是什么,否则它是无法工作的,但是对于InputSplit不一定,因为InputSplit是按照大小进行划分的,数据到底是什么不关心.InputSplite和block除了大小一样之外没有联系.
我们的map中指定的TextInputFormat实际上是InputSplit,RecordRead封装之后的.
TextInputFormat父类是FileInputFormat,RecordReder实际上是创建了一个RecordRead一个子类LineRecordReader:处理一行的.
FileInputFormat是一个抽象类,继承了InputFormat
map任务的数量是由我们InputSplit的数量来决定的.
FileInputFormat中getSplits(),将我们的输入转换为InputSplit,产生了一些文件列表,并且把他们做成FileSplit,FileSplit是InputSplit的子类.
mapred.min.split.size:配置的是InputSplit的最小值,如果没有配置使用最小1.
mapred.max.split.size:配置的是InputSplit的最大值,如果没有配置使用long的最大值.
每个输入文件至少有一个切片.所以小文件很多,每一个小文件都是一个切片,意味着就有很多的map,那么你的数据量是1个T,如果每个文件都是10k,或者1兆的话,文件量很大,切片很大,map也就意味着很大.所以我们说mapreduce不适合小文件在这里,
如果每个文件都是1M,我们把64个文件合并到一起,意味着文件的数据量缩小了63倍,那么我们的map任务的数量也缩小了63倍.
切片大小默认是64兆,可能不是64兆,改变最小值设置,和最大值设置就会改变split的大小的.
当文件很大,并且允许被切分的时候,我们的split的产生是从0字节开始,以64兆为长度,这个切分的东西,是以64兆为单位的.并且,我们在生产FileSplit这个对象的时候,传递的参数,第一个是路径,第二个是文件的起始位置,第一次切分开始的位置是0,文件的长度就是blockSize.
FileSplit中是没有存文件内容的地方,如果能存,最少有一个字节数组,从这个角度讲,我们的FileSplit对hdfs文件的切分仅仅是一种逻辑切分,没有真的切,FileSplit没有真的存放数据.仅仅是1T的数据,按照64兆去设计一个标记一个标记,我们在讲的这个地方使用的FileSplit,FileSplit中存放的我们的文件路径,起始位置,处理的数据长度,FileSplit本身不存储数据,只是存储了原始数据的位置和要处理的长度.
所以我们的RecordRead要想读取FileSplit中的数据是读不到的,只能读hdfs,要从哪个字节来处理等等.
RecordRead真要把输入数据的每一行转化为键值对的话,还要去读hdfs,InputSplit只是做了一个封装,封装了它的位置.因为我们的hdfs特别大,所以我们没有办法对hdfs做封装,只能封装一些位置.如果我们自己去定义InputFormat的时候,可以在InputSplit中产生数据.
拆分InputSplit这个运算是在map运行的时候,map运行的节点上.
InputSplit是说数据没有真的被切分,只是做了几个标志,原始数据还是在那.意味着有几个InputSplit就有几个RecordRead.
我们的任务到job.waitForCompletion(),才会真的被执行,将任务提交给JobTracker之后,JobTracker分发到各个TaskTracker上去执行,也就是我们的map任务.
我们的作业Job运行的时候,job map的数量由InputSplit个数决定的,有多少个InputSplit就有多少个map,默认情况下map任务的数量由block的个数决定.程序很大,还没有运行,可以使用InputSplit来推导map任务的个数.
map的个数由InputSplit的数量决定的,InputSplit的数量由block的大小决定的.默认当我们的block有多少个.InputSplit就有多少个,InputSplit是对原始数据的切分.map的数量就由block的数量来决定的.
每一个键值对调用一次map函数,
RecordRead是通过in.readLine读取每一行的.
map函数的调用RecordRead:
context调用getCurrentKey(),getCurrentValue(),nextKeyValue.RecordRead作为LineRecordRead的一个父类.
Context在实例化的时候,已经把LineRecordRead给拿过来了.
运行map任务时,调用run()方法,执行context.nextKeyValue方法,内部调用的是RecordRead的方法.
Mapper实现类是通过反射实例化这个对象,然后调用run()方法.
我们的代码在运行的时候,已经把jar上传到hdfs中去了,然后交给jobTracker仅仅是这个jar的url,一个地址.
map运行的数量:mapred.map.tasks 默认2个
reduce运行的数量:mapred.reduce.tasks 默认1个
taskTracker上运行的最大map数量:mapred.tasktracker.map.task.maximum 默认2个
tasktracker上运行reduce最大数量:mapred.tasktracker.reduce.task.maximum 默认2个
jobtracker根据slot分配task,mapreduce在运行的时候分为job和task,job由jobtracker根据调度器进行分配的.map和task下面的这些任务是由slot决定分配.
1.将我们的原始数据处理,封装成一个InputSplit.
2.通过一个RecordRead,把InputSplit中的记录读取,然后解析成一个个的键值对,供map处理.
TextInputFormat key是每一行的偏移量,value就是每一行的内容,也就是说TextInputFormat是按行进行处理的.每一行是一条记录.
我们的mapreduce就是用来做海量计算的,海量计算就是为了解决我们的业务,既然我们的业务可以通过mapreduce的海量计算来解决,那么我们只需要把他们的输入部分,和输出部分,输入源明晰了,那么我们hadoop的这个mapreduce应用框架就很厉害了.
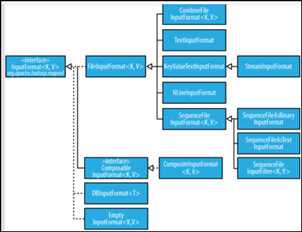
InputFormat有一些子类,首先有一个FileInputFormat,和我们的DBInputFormat,用到最多的就是FileInputFormat.
FileInputFormat指的是对文件的一种操作,
DBInputFormat指的是对数据库的一种操作,也就是说我们的mapreduce可以处理关系型数据库中的数据.
FileInputFormat指的是处理文件,这个文件可能是普通的文本文件,也有可能是一些格式不是很好的一些文件,这些文件的内容有的是已经标准化的,有的没有标准化的,不管怎么着,只要是文件就由FileInputFormat.
FileInputFormat根据处理的文件的类型不一样,又分为TextInputFotmat,
还有普通文本文件中的每一行,它使用了制表符进行处理,也就是说一行中分隔是使用制表符进行分隔的.这个时候可以使用keyValuTextInputFormat.
KeyValueTextInputFormat是TextInputFormat的一个特例,KeyValueTextInputFormat和TextInputFormat处理的只有一行记录,换一句话说,就是我们的每一行交给一个map执行,
在我们程序运行的过程,如果程序源有几条记录,比如有3五条,每一行的内容又特别长,这个时候我们的InputFormat在切分InputSplit的时候,按照大小切分,如果有的记录中有几行内容特别长,那么我们这个InputSplit中的键值对的数量就少了,也就是说我们根据大小切分出的InputSplit,有的产生的数量特多,有的数量特别少,这个时候对于运行map而言,有的map执行快,有的map执行慢,这个时候我们可以使用NLineInputFormat进行处理,它可以根据行来 指定一下处理几行,也就是说可以将几行记录作为一个键值对,这个都是可以设置的.
我们的输入的文件有的文件是经过压缩过的,我们可以使用SequenceFile进行处理.
还有一个就是有很多的小文件,或者是说我们输入的数据源是好几个,比如有的是数据库,有的是普通文件,有的是SequenceFile这种格式的,这个时候可以使用CompositeInputFormat.
这个就是几种常见的InputFormat.
InputFormat中包含两个类,InputSplit,RecordRead,我们在自定义InputFormat的时候也需要去覆盖InputSplit和RecordRead.
mapReaduce处理TextInputFormat之外还有其他的输入类,数据库DBInputFormat,CombineInputFormat,还有KeyValueTextInputFormat,NLineInputFormat,SequenceFileInputFormat
DBOutputFormat:输出的类会发送一个reduce的输出结果到sql的表中,DBOutputFormat会接收这个键值对,键是一个DBWritable,value是什么已经不重要了,我们写出去的只需要把键写出去,值用不着.map的输出是在本地运行的,如果没有reduce,就会通过shuffle直接写入到hdfs中
我们在开发的时候数据来源不可能那么单一,是多样的,有的数据,由于历史的原因,应用很多是在关系型数据库,中的,有些是在hdfs中的,这时候,如果关系型数据库和hdfs数据发生关系的时候,这时候只能使用这种基于数据库的这种方式,通过数据库进行格式化,
有这些输入处理的类,就把我们的mapreduce应用的范围给扩大了,不会仅仅读取hdfs中的数据,也可以读取普通关系型数据库.直接读取数据库中的内容.
在测试代码之前需要先在linux上安装mysql,我是在64位centos linux上使用yum安装MySql,做一个记录,留作以后复习使用:
1.查看有没有安装过:
yum list installed mysql*
rpm -qa | grep mysql*
查看有没有安装包:yum list mysql*
安装mysql客户端: yum install mysql
安装mysql 服务器端: yum install mysql-server
yum install mysql-devel
2、启动&&停止
启动mysql mysqld_safe &
查看mysql是否启动 ps -ef | grep mysql
3. 配置
mysql_secure_installation
1).键入当前的root密码
2).是否设置密码?y 设置新密码
3).是否删除匿名用户?n 不删除
4).是否关闭远程登录?n 不关闭
5).是否删除测试数据库?n 不删除
6).是否重新加载权限机制?y
4. 登录: mysql -uroot -padmin

/** * 要运行本示例 * 1.把mysql的jdbc驱动放到各TaskTracker节点的lib目录下. * 2.重启集群. * 数据库到我们的MapReduce,MapReduce可以不把数据输出到hdfs中,也可以输出其他的地方都可以. * 将mapReduce中的数据传输到hdfs中还是使用FileSystem * @author Administrator * */ public class MyDBInputFormatApp { private static final String OUT_PATH = "hdfs://hadoop1:9000/out";// 输出路径,reduce作业输出的结果是一个目录 public static void main(String[] args) { Configuration conf = new Configuration();// 配置对象 DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://hadoop1:3306/test", "root", "admin"); try { FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf); fileSystem.delete(new Path(OUT_PATH), true); Job job = new Job(conf, WordCountApp.class.getSimpleName());// jobName:作业名称 job.setJarByClass(WordCountApp.class); job.setInputFormatClass(DBInputFormat.class); //指定转化的实体类,数据库表,需要转化的字段 DBInputFormat.setInput(job, MyUser.class, "myuser", null, null, "id","name"); job.setMapperClass(MyMapper.class);// 指定自定义map类 job.setMapOutputKeyClass(Text.class);// 指定map输出key的类型 job.setMapOutputValueClass(NullWritable.class);// 指定map输出value的类型 job.setNumReduceTasks(0);//指定不需要reduce,直接把map输出写入到HDFS中 job.setOutputKeyClass(Text.class);// 设置Reduce输出key的类型 job.setOutputValueClass(NullWritable.class);// 设置Reduce输出的value类型 FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));// Reduce输出完之后,就会产生一个最终的输出,指定最终输出的位置 job.waitForCompletion(true);// 提交给jobTracker并等待结束 } catch (Exception e) { e.printStackTrace(); } } public static class MyMapper extends Mapper<LongWritable, MyUser, Text, NullWritable> { @Override protected void map(LongWritable key, MyUser value, Context context) throws IOException, InterruptedException { context.write(new Text(value.toString()), NullWritable.get());// 把每个单词出现的次数1写出去. } } /** * Writable:hadoop运行时进行序列化的类 * DBWritable:hadoop和数据库交互时使用到的序列化类 * */ public static class MyUser implements Writable,DBWritable{ int id ; String name ; @Override public void write(PreparedStatement statement) throws SQLException { statement.setInt(1, id); statement.setString(2, name); } @Override public void readFields(ResultSet resultSet) throws SQLException { this.id = resultSet.getInt(1); this.name = resultSet.getString(2); } @Override public void write(DataOutput out) throws IOException { out.writeInt(id); Text.writeString(out, name); } @Override public void readFields(DataInput in) throws IOException { this.id = in.readInt(); this.name = Text.readString(in); } @Override public String toString() { return id + "\t" + name ; } } }
InputFormat,OutputFormat,InputSplit,RecordRead(一些常见面试题),使用yum安装64位Mysql
标签:
原文地址:http://www.cnblogs.com/xiaolong1032/p/4504992.html
