标签:
(感谢网友 @我的上铺叫路遥 翻译投稿)
CPU cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点,而且相关参考资料如同过江之鲫,浩瀚繁星,阅之如临深渊,味同嚼蜡,三言两语难以入门。正好网上有人推荐了微软大牛Igor Ostrovsky一篇博文《漫游处理器缓存效应》,文章不仅仅用7个最简单的源码示例就将CPU cache的原理娓娓道来,还附加图表量化分析做数学上的佐证,个人感觉这种案例教学的切入方式绝对是俺的菜,故而忍不住贸然译之,以飨列位看官。
原文地址:Gallery of Processor Cache Effects
大多数读者都知道cache是一种快速小型的内存,用以存储最近访问内存位置。这种描述合理而准确,但是更多地了解一些处理器缓存工作中的“烦人”细节对于理解程序运行性能有很大帮助。
在这篇博客中,我将运用代码示例来详解cache工作的方方面面,以及对现实世界中程序运行产生的影响。
下面的例子都是用C#写的,但语言的选择同程序运行状况以及得出的结论几乎没什么影响。
你认为相较于循环1,循环2会运行多快?
第一个循环将数组的每个值乘3,第二个循环将每16个值乘3,第二个循环只做了第一个约6%的工作,但在现代机器上,两者几乎运行相同时间:在我机器上分别是80毫秒和78毫秒。
两个循环花费相同时间的原因跟内存有关。循环执行时间长短由数组的内存访问次数决定的,而非整型数的乘法运算次数。经过下面对第二个示例的解释,你会发现硬件对这两个循环的主存访问次数是相同的。
让我们进一步探索这个例子。我们将尝试不同的循环步长,而不仅仅是1和16。
下图为该循环在不同步长(K)下的运行时间:
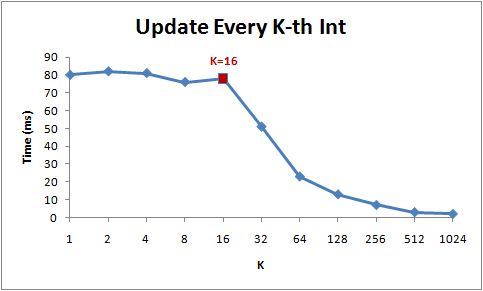
注意当步长在1到16范围内,循环运行时间几乎不变。但从16开始,每次步长加倍,运行时间减半。
背后的原因是今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
由于16个整型数占用64字节(一个缓存行),for循环步长在1到16之间必定接触到相同数目的缓存行:即数组中所有的缓存行。当步长为32,我们只有大约每两个缓存行接触一次,当步长为64,只有每四个接触一次。
理解缓存行对某些类型的程序优化而言可能很重要。比如,数据字节对齐可能决定一次操作接触1个还是2个缓存行。那上面的例子来说,很显然操作不对齐的数据将损失一半性能。
今天的计算机具有两级或三级缓存,通常叫做L1、L2以及可能的L3(译者注:如果你不明白什么叫二级缓存,可以参考这篇精悍的博文lol)。如果你想知道不同缓存的大小,你可以使用系统内部工具CoreInfo,或者Windows API调用GetLogicalProcessorInfo。两者都将告诉你缓存行以及缓存本身的大小。
在我的机器上,CoreInfo现实我有一个32KB的L1数据缓存,一个32KB的L1指令缓存,还有一个4MB大小L2数据缓存。L1缓存是处理器独享的,L2缓存是成对处理器共享的。
Logical Processor to Cache Map:
*— Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
*— Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
-*- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
-*- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
**- Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64
-*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
-*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
—* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
—* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
-** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64
(译者注:作者平台是四核机,所以L1编号为0~3,数据/指令各一个,L2只有数据缓存,两个处理器共享一个,编号0~1。关联性字段在后面例子说明。)
让我们通过一个实验来验证这些数字。遍历一个整型数组,每16个值自增1——一种节约地方式改变每个缓存行。当遍历到最后一个值,就重头开始。我们将使用不同的数组大小,可以看到当数组溢出一级缓存大小,程序运行的性能将急剧滑落。
下图是运行时间图表:
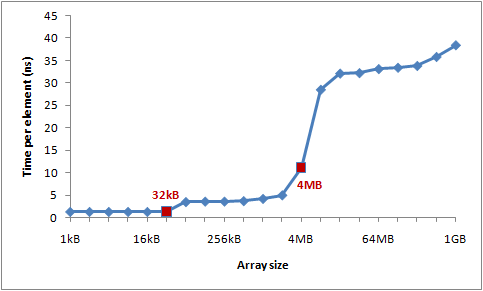
你可以看到在32KB和4MB之后性能明显滑落——正好是我机器上L1和L2缓存大小。
现在让我们看一看不同的东西。下面两个循环中你以为哪个较快?
结果是第二个循环约比第一个快一倍,至少在我测试的机器上。为什么呢?这跟两个循环体内的操作指令依赖性有关。
第一个循环体内,操作做是相互依赖的(译者注:下一次依赖于前一次):

但第二个例子中,依赖性就不同了:

现代处理器中对不同部分指令拥有一点并发性(译者注:跟流水线有关,比如Pentium处理器就有U/V两条流水线,后面说明)。这使得CPU在同一时刻访问L1两处内存位置,或者执行两次简单算术操作。在第一个循环中,处理器无法发掘这种指令级别的并发性,但第二个循环中就可以。
[原文更新]:许多人在reddit上询问有关编译器优化的问题,像{ a[0]++; a[0]++; }能否优化为{ a[0]+=2; }。实际上,C#编译器和CLR JIT没有做优化——在数组访问方面。我用release模式编译了所有测试(使用优化选项),但我查询了JIT汇编语言证实优化并未影响结果。
缓存设计的一个关键决定是确保每个主存块(chunk)能够存储在任何一个缓存槽里,或者只是其中一些(译者注:此处一个槽位就是一个缓存行)。
有三种方式将缓存槽映射到主存块中:
直接映射(Direct mapped cache)
每个内存块只能映射到一个特定的缓存槽。一个简单的方案是通过块索引chunk_index映射到对应的槽位(chunk_index % cache_slots)。被映射到同一内存槽上的两个内存块是不能同时换入缓存的。(译者注:chunk_index可以通过物理地址/缓存行字节计算得到)
N路组关联(N-way set associative cache)
每个内存块能够被映射到N路特定缓存槽中的任意一路。比如一个16路缓存,每个内存块能够被映射到16路不同的缓存槽。一般地,具有一定相同低bit位地址的内存块将共享16路缓存槽。(译者注:相同低位地址表明相距一定单元大小的连续内存)
完全关联(Fully associative cache)
每个内存块能够被映射到任意一个缓存槽。操作效果上相当于一个散列表。
直接映射缓存会引发冲突——当多个值竞争同一个缓存槽,它们将相互驱逐对方,导致命中率暴跌。另一方面,完全关联缓存过于复杂,并且硬件实现上昂贵。N路组关联是处理器缓存的典型方案,它在电路实现简化和高命中率之间取得了良好的折中。

(此图由译者给出,直接映射和完全关联可以看做N路组关联的两个极端,从图中可知当N=1时,即直接映射;当N取最大值时,即完全关联。读者可以自行想象直接映射图例,具体表述见参考资料。)
举个例子,4MB大小的L2缓存在我机器上是16路关联。所有64字节内存块将分割为不同组,映射到同一组的内存块将竞争L2缓存里的16路槽位。
L2缓存有65,536个缓存行(译者注:4MB/64),每个组需要16路缓存行,我们将获得4096个集。这样一来,块属于哪个组取决于块索引的低12位bit(2^12=4096)。因此缓存行对应的物理地址凡是以262,144字节(4096*64)的倍数区分的,将竞争同一个缓存槽。我机器上最多维持16个这样的缓存槽。(译者注:请结合上图中的2路关联延伸理解,一个块索引对应64字节,chunk0对应组0中的任意一路槽位,chunk1对应组1中的任意一路槽位,以此类推chunk4095对应组4095中的任意一路槽位,chunk0和chunk4096地址的低12bit是相同的,所以chunk4096、chunk8192将同chunk0竞争组0中的槽位,它们之间的地址相差262,144字节的倍数,而最多可以进行16次竞争,否则就要驱逐一个chunk)。
为了使得缓存关联效果更加明了,我需要重复地访问同一组中的16个以上的元素,通过如下方法证明:
该方法每次在数组中迭代K个值,当到达末尾时从头开始。循环在运行足够长(2^20次)之后停止。
我使用不同的数组大小(每次增加1MB)和不同的步长传入UpdateEveryKthByte()。以下是绘制的图表,蓝色代表运行较长时间,白色代表较短时间:
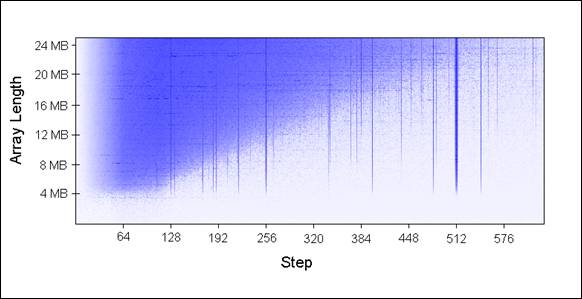
蓝色区域(较长时间)表明当我们重复数组迭代时,更新的值无法同时放在缓存中。浅蓝色区域对应80毫秒,白色区域对应10毫秒。
让我们来解释一下图表中蓝色部分:
1.为何有垂直线?垂直线表明步长值过多接触到同一组中内存位置(大于16次)。在这些次数里,我的机器无法同时将接触过的值放到16路关联缓存中。
一些糟糕的步长值为2的幂:256和512。举个例子,考虑512步长遍历8MB数组,存在32个元素以相距262,144字节空间分布,所有32个元素都会在循环遍历中更新到,因为512能够整除262,144(译者注:此处一个步长代表一个字节)。
由于32大于16,这32个元素将一直竞争缓存里的16路槽位。
(译者注:为何512步长的垂直线比256步长颜色更深?在同样足够多的步数下,512比256访问到存在竞争的块索引次数多一倍。比如跨越262,144字节边界512需要512步,而256需要1024步。那么当步数为2^20时,512访问了2048次存在竞争的块而256只有1024次。最差情况下步长为262,144的倍数,因为每次循环都会引发一个缓存行驱逐。)
有些不是2的幂的步长运行时间长仅仅是运气不好,最终访问到的是同一组中不成比例的许多元素,这些步长值同样显示为蓝线。
2.为何垂直线在4MB数组长度的地方停止?因为对于小于等于4MB的数组,16路关联缓存相当于完全关联缓存。
一个16路关联缓存最多能够维护16个以262,144字节分隔的缓存行,4MB内组17或更多的缓存行都没有对齐在262,144字节边界上,因为16*262,144=4,194,304。
3.为何左上角出现蓝色三角?在三角区域内,我们无法在缓存中同时存放所有必要的数据,不是出于关联性,而仅仅是因为L2缓存大小所限。
举个例子,考虑步长128遍历16MB数组,数组中每128字节更新一次,这意味着我们一次接触两个64字节内存块。为了存储16MB数组中每两个缓存行,我们需要8MB大小缓存。但我的机器中只有4MB缓存(译者注:这意味着必然存在冲突从而延时)。
即使我机器中4MB缓存是全关联,仍无法同时存放8MB数据。
4.为何三角最左边部分是褪色的?注意左边0~64字节部分——正好一个缓存行!就像上面示例1和2所说,额外访问相同缓存行的数据几乎没有开销。比如说,步长为16字节,它需要4步到达下一个缓存行,也就是说4次内存访问只有1次开销。
在相同循环次数下的所有测试用例中,采取省力步长的运行时间来得短。
将图表延伸后的模型:
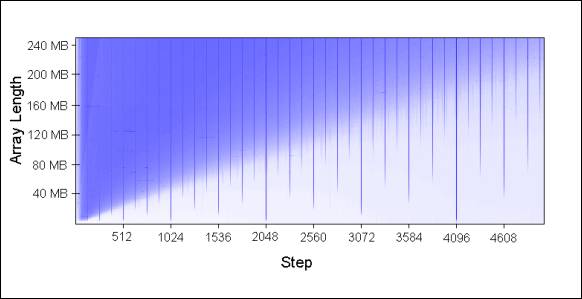
缓存关联性理解起来有趣而且确能被证实,但对于本文探讨的其它问题比起来,它肯定不会是你编程时所首先需要考虑的问题。
在多核机器上,缓存遇到了另一个问题——一致性。不同的处理器拥有完全或部分分离的缓存。在我的机器上,L1缓存是分离的(这很普遍),而我有两对处理器,每一对共享一个L2缓存。这随着具体情况而不同,如果一个现代多核机器上拥有多级缓存,那么快速小型的缓存将被处理器独占。
当一个处理器改变了属于它自己缓存中的一个值,其它处理器就再也无法使用它自己原来的值,因为其对应的内存位置将被刷新(invalidate)到所有缓存。而且由于缓存操作是以缓存行而不是字节为粒度,所有缓存中整个缓存行将被刷新!
为证明这个问题,考虑如下例子:
在我的四核机上,如果我通过四个线程传入参数0,1,2,3并调用UpdateCounter,所有线程将花费4.3秒。
另一方面,如果我传入16,32,48,64,整个操作进花费0.28秒!
为何会这样?第一个例子中的四个值很可能在同一个缓存行里,每次一个处理器增加计数,这四个计数所在的缓存行将被刷新,而其它处理器在下一次访问它们各自的计数(译者注:注意数组是private属性,每个线程独占)将失去命中(miss)一个缓存。这种多线程行为有效地禁止了缓存功能,削弱了程序性能。
即使你懂得了缓存的工作基础,有时候硬件行为仍会使你惊讶。不用处理器在工作时有不同的优化、探试和微妙的细节。
有些处理器上,L1缓存能够并发处理两路访问,如果访问是来自不同的存储体,而对同一存储体的访问只能串行处理。而且处理器聪明的优化策略也会使你感到惊讶,比如在伪共享的例子中,以前在一些没有微调的机器上运行表现并不良好,但我家里的机器能够对最简单的例子进行优化来减少缓存刷新。
下面是一个“硬件怪事”的奇怪例子:
当我在循环体内进行三种不同操作,我得到如下运行时间:
操作 时间
A++; B++; C++; D++; 719 ms
A++; C++; E++; G++; 448 ms
A++; C++; 518 ms
增加A,B,C,D字段比增加A,C,E,G字段花费更长时间,更奇怪的是,增加A,C两个字段比增加A,C,E,G执行更久!
我无法肯定这些数字背后的原因,但我怀疑这跟存储体有关,如果有人能够解释这些数字,我将洗耳恭听。
这个例子的教训是,你很难完全预测硬件的行为。你可以预测很多事情,但最终,衡量及验证你的假设非常重要。
Goz:我询问Intel的工程师最后的例子,得到以下答复:
“很显然这涉及到执行单元里指令是怎样终止的,机器处理存储-命中-加载的速度,以及如何快速且优雅地处理试探性执行的循环展开(比如是否由于内部冲突而多次循环)。但这意味着你需要非常细致的流水线跟踪器和模拟器才能弄明白。在纸上预测流水线里的乱序指令是无比困难的工作,就算是设计芯片的人也一样。对于门外汉来说,没门,抱歉!”
程序的运行存在时间和空间上的局部性,前者是指只要内存中的值被换入缓存,今后一段时间内会被多次引用,后者是指该内存附近的值也被换入缓存。如果在编程中特别注意运用局部性原理,就会获得性能上的回报。
比如C语言中应该尽量减少静态变量的引用,这是因为静态变量存储在全局数据段,在一个被反复调用的函数体内,引用该变量需要对缓存多次换入换出,而如果是分配在堆栈上的局部变量,函数每次调用CPU只要从缓存中就能找到它了,因为堆栈的重复利用率高。
再比如循环体内的代码要尽量精简,因为代码是放在指令缓存里的,而指令缓存都是一级缓存,只有几K字节大小,如果对某段代码需要多次读取,而这段代码又跨越一个L1缓存大小,那么缓存优势将荡然无存。
关于CPU的流水线(pipeline)并发性简单说说,Intel Pentium处理器有两条流水线U和V,每条流水线可各自独立地读写缓存,所以可以在一个时钟周期内同时执行两条指令。但这两条流水线不是对等的,U流水线可以处理所有指令集,V流水线只能处理简单指令。
CPU指令通常被分为四类,第一类是常用的简单指令,像mov, nop, push, pop, add, sub, and, or, xor, inc, dec, cmp, lea,可以在任意一条流水线执行,只要相互之间不存在依赖性,完全可以做到指令并发。
第二类指令需要同别的流水线配合,像一些进位和移位操作,这类指令如果在U流水线中,那么别的指令可以在V流水线并发运行,如果在V流水线中,那么U流水线是暂停的。
第三类指令是一些跳转指令,如cmp,call以及条件分支,它们同第二类相反,当工作在V流水线时才能通U流水线协作,否则只能独占CPU。
第四类指令是其它复杂的指令,一般不常用,因为它们都只能独占CPU。
如果是汇编级别编程,要达到指令级别并发,必须要注重指令之间的配对。尽量使用第一类指令,避免第四类,还要在顺序上减少上下文依赖。
上海交通大学师生制作的一个关于cache映射功能、命中率计算的教学演示程序,模拟了不同关联模式下cache的映射和命中几率,形象直观。
网易数据库大牛@何_登成自制PPT《CPU Cache and Memory Ordering》,信息量超大!
南京大学计算机教学公开PPT,温馨提示,地址域名里面改变字段”lecture”后面的数字编号可切换课程;-)
最后一次修改:2010年11月11日
本文所讨论的计算机模型是Shared Memory Multiprocessor,即我们现在常见的共享内存的多核CPU。本文适合的对象是想用C++或者Java进行多线程编程的程序员。本文主要包括对Sequential Consistency和Cache Coherence的概念性介绍并给出了一些相关例子,目的是帮助程序员明白为什么需要在并行编程时关注Sequential Consistency。
Sequential Consistency(下文简称SC)是Java内存模型和即将到来的C++0x内存模型的一个关键概念,它是一个最直观最易理解的多线程程序执行顺序的模型。Cache Coherence(下文简称CC)是多核CPU在硬件中已经实现的一种机制,简单的说,它确保了对在多核CPU的Cache中一个地址的读操作一定会返回那个地址最新的(被写入)的值。
那么为什么程序员需要关心SC呢?因为现在的硬件和编译器出于性能的考虑会对程序作出违反SC的优化,而这种优化会影响多线程程序的正确性,也就是说你用C++编写的多线程程序可能会得到的不是你想要的错误的运行结果。Java从JDK1.5开始加入SC支持,所以Java程序员在进行多线程编程时需要注意使用Java提供的相关机制来确保你程序的SC。程序员之所以不需要关心CC的细节是因为现在它已经被硬件给自动帮你保证了(不是说程序员完全不需要关心CC,实际上对程序员来说理解CC的大致工作原理也是很有帮助的,典型的如避免多线程程序的伪共享问题,即False Sharing)。
那么什么是SC,什么是CC呢?
SC的作者Lamport给的严格定义是:
“… the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.”
这个概念初次理解起来拗口,不过不要紧,下面我会给出个很直观的例子帮助理解。
假设我们有两个线程(线程1和线程2)分别运行在两个CPU上,有两个初始值为0的全局共享变量x和y,两个线程分别执行下面两条指令:
初始条件: x = y = 0;
| 线程 1 | 线程 2 |
| x = 1; | y=1; |
| r1 = y; | r2 = x; |
因为多线程程序是交错执行的,所以程序可能有如下几种执行顺序:
| Execution 1 | Execution 2 | Execution 3 |
|
x = 1;
r1 = y;
y = 1;
r2 = x;
结果:r1==0 and r2 == 1
|
y = 1;
r2 = x;
x = 1;
r1 = y;
结果: r1 == 1 and r2 == 0
|
x = 1;
y = 1;
r1 = y;
r2 = x;
结果: r1 == 1 and r2 == 1
|
当然上面三种情况并没包括所有可能的执行顺序,但是它们已经包括所有可能出现的结果了,所以我们只举上面三个例子。我们注意到这个程序只可能出现上面三种结果,但是不可能出现r1==0 and r2==0的情况。
SC其实就是规定了两件事情:
(1)每个线程内部的指令都是按照程序规定的顺序(program order)执行的(单个线程的视角)
(2)线程执行的交错顺序可以是任意的,但是所有线程所看见的整个程序的总体执行顺序都是一样的(整个程序的视角)
第一点很容易理解,就是说线程1里面的两条语句一定在该线程中一定是x=1先执行,r1=y后执行。第二点就是说线程1和线程2所看见的整个程序的执行顺序都是一样的,举例子就是假设线程1看见整个程序的执行顺序是我们上面例子中的Execution 1,那么线程2看见的整个程序的执行顺序也是Execution 1,不能是Execution 2或者Execution 3。
有一个更形象点的例子。伸出你的双手,掌心面向你,两个手分别代表两个线程,从食指到小拇指的四根手指头分别代表每个线程要依次执行的四条指令。SC的意思就是说:
(1)对每个手来说,它的四条指令的执行顺序必须是从食指执行到小拇指
(2)你两个手的八条指令(八根手指头)可以在满足(1)的条件下任意交错执行(例如可以是左1,左2,右1,右2,右3,左3,左4,右4,也可以是左1,左2,左3,左4,右1,右2,右3,右4,也可以是右1,右2,右3,左1,左2,右4,左3,左4等等等等)
其实说简单点,SC就是我们最容易理解的那个多线程程序执行顺序的模型。
那么CC是干什么用的呢?这个要详细说的话就复杂了,写一本书绰绰有余。简单来说,我们知道现在的多核CPU的Cache是多层结构,一般每个CPU核心都会有一个私有的L1级和L2级Cache,然后多个CPU核心共享一个L3级缓存,这样的设计是出于提高内存访问性能的考虑。但是这样就有一个问题了,每个CPU核心之间的私有L1,L2级缓存之间需要同步啊。比如说,CPU核心1上的线程A对一个共享变量global_counter进行了加1操作,这个被写入的新值存到CPU核心1的L1缓存里了;此时另一个CPU核心2上的线程B要读global_counter了,但是CPU核心2的L1缓存里的global_counter的值还是旧值,最新被写入的值现在还在CPU核心1上呢!怎么把?这个任务就交给CC来完成了!
CC是Cache之间的一种同步协议,它其实保证的就是对某一个地址的读操作返回的值一定是那个地址的最新值,而这个最新值可能是该线程所处的CPU核心刚刚写进去的那个最新值,也可能是另一个CPU核心上的线程刚刚写进去的最新值。举例来说,上例的Execution 3中,r1 = y是对y进行读操作,该读操作一定会返回在它之前已经执行的那条指令y=1对y写入的最新值。可能程序员会说这个不是显而意见的么?r1肯定是1啊,因为y=1已经执行了。其实这个看似简单的”显而易见“在多核processor的硬件实现上是有很多文章的,因为y=1是在另一个CPU上发生的事情,你怎么确保你这个读操作能立刻读到别的CPU核心刚刚写入的值?不过对程序员来讲你不需要关心CC,因为CPU已经帮你搞定这些事情了,不用担心多核CPU上不同Cache之间的同步的问题了(感兴趣的朋友可以看看体系结构的相关书籍,现在的多核CPU一般是以MESI protocol为原型来实现CC)。总结一下,CC和SC其实是相辅相承的,前者保证对单个地址的读写正确性,后者保证整个程序对多个地址读写的正确性,两者共同保证多线程程序执行的正确性。
好,回到SC的话题。为什么说程序员需要关心SC?因为现在的CPU和编译器会对代码做各种各样的优化,有时候它们可能会为了优化性能而把程序员在写程序时规定的代码执行顺序(program order)打乱,导致程序执行结果是错误的。
例如编译器可能会做如下优化,即把线程1的两条语序调换执行顺序:
初始条件: x=y=0;
| 线程 1 | 线程 2 |
| r1 = y; | y=1; |
| x = 1; | r2 = x; |
那么这个时候程序如果按如下顺序执行就可能就会出现r1==r2==0这样程序员认为”不正确“的结果:
| Execution 4 |
| r1 = y;
y = 1; r2 = x; x = 1; |
为什么编译器会做这样的优化呢?因为读一个在内存中而不是在cache中的共享变量需要很多周期,所以编译器就”自作聪明“的让读操作先执行,从而隐藏掉一些指令执行的latency,提高程序的性能。实际上这种类似的技术是在单核时代非常普遍的优化方法,但是在进入多核时代后编译器没跟上发展,导致了对多线程程序进行了违反SC的错误优化。为什么编译器很难保证SC?因为对编译器来讲它很难知道多个线程在执行时会按照什么样的交错顺序执行,因为这需要一个整个程序运行时的视角,而只对一份静态的代码做优化的编译器是很难得到这种运行时的上下文的。那么为什么硬件也保证不了呢?因为CPU硬件中的写缓冲区(store buffer)会把要写入memory的值缓存起来,然后当前线程继续往下执行,而这个被缓存的值可能要很晚才会被其他线程“看见”,从而导致多线程程序逻辑出错。其实硬件也提供了一些例如Memory Barrier等解决方案,但是开销是一个比较大的问题,而且很多需要程序员手动添加memory barrier,现在还不能指望CPU或者编译器自动帮你搞定这个问题。(感兴趣的朋友可以在本文的参考文献中发现很多硬件优化造成SC被违反的例子以及Memory Barrier等解决方案)
好了,我们发现为了保证多线程的正确性,我们希望程序能按照SC模型执行;但是SC的对性能的损失太大了,CPU硬件和编译器为了提高性能就必须要做优化啊!为了既保证正确性又保证性能,在经过十几年的研究后一个新的新的模型出炉了:sequential consistency for data race free programs。简单地说这个模型的原理就是对没有data race的程序可以保证它是遵循SC的,这个模型在多线程程序的正确性和性能间找到了一个平衡点。对广大程序员来说,我们依赖高级语言内建的内存模型来帮我们保证多线程程序的正确性。例如,从JDK1.5开始引入的Java内存模型中已经支持data race free的SC了(例如使用volatile关键字,atomic变量等),但是C++程序员就需要等待C++0x中新的内存模型的atomic类型等来帮助保证SC了(因为atomic类型的值具有acquire和release语义,它隐式地调用了memory barrier指令)。什么意思呢?说简单点,就是由程序员用同步原语(例如锁或者atomic的同步变量)来保证你程序是没有data race的,这样CPU和编译器就会保证你程序是按你所想的那样执行的(即SC),是正确的。换句话说,程序员只需要恰当地使用具有acquire和release语义的同步原语标记那些真正需要同步的变量和操作,就等于告诉CPU和编译器你们不要对这些标记出来的操作和变量做违反SC的优化,而其它未被标记的地方你们可以随便优化,这样既保证了正确性又保证了CPU和编译器可以做尽可能多的性能优化。来告诉编译器和CPU这里这里你不能做违反SC的优化,那里那里你不能做违反SC的优化,然后你写的程序就会得到正确的执行结果了。
从根源上来讲,在串行时代,编译器和CPU对代码所进行的乱序执行的优化对程序员都是封装好了的,无痛的,所以程序员不需要关心这些代码在执行时被乱序成什么样子,因为这些都被编译器和CPU封装起来了,你不用担心内部细节,它最终表现出来的行为就是按你想要的那种方式执行的。但是进入多核时代,程序员、编译器、CPU三者之间未能达成一致(例如诸如C/C++之类的编程语言没有引入多线程),所以CPU、编译器就会时不时地给你捣蛋,故作聪明的做一些优化,让你的程序不会按照你想要的方式执行,是错误的。Java作为引入多线程的先驱从1.5开始支持内存模型,等于是帮助程序员达成了与编译器、CPU(以及JVM)之间的契约,程序员只要正确的使用同步原语就可以保证程序最终表现出来的行为跟你所想的一样(即我们最容易理解的SC模型),是正确的。
本文并未详细介绍所有针对SC问题的解决方案(例如X86对SC的支持,Java对它的支持,C++对它的支持等等),如果想了解更多,可以参考本文所指出的参考文献。下一次我会写一篇关于data race free model, weak ordering, x86 memory model等相关概念的文章,敬请期待。
并行编程是非常困难的,在多核时代的程序员不能指望硬件和编译器来帮你搞定所有的事情,努力学习多核多线程编程的一些基础知识是很有必要的,至少你应该知道你的程序到底会以什么样的方式被执行。
参考文献:
[1] Hans Boehm: C++ Memory Model
[2] Bill Pugh: The Java Memory Model
[4] Wiki: Sequential Consistency
标签:
原文地址:http://blog.csdn.net/bb2b2bbb/article/details/45743823