标签:
系列文章:《机器学习》学习笔记
最近看了《机器学习实战》中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集)。正如章节标题所示,这两章讲了无监督机器学习方法中的关联分析问题。关联分析可以用于回答"哪些商品经常被同时购买?"之类的问题。书中举了一些关联分析的例子:
从大规模数据集中寻找物品间的隐含关系被称作关联分析(association analysis)或者关联规则学习(association rule learning)。这里的主要问题在于,寻找物品的不同组合是一项十分耗时的任务,所需的计算代价很高,蛮力搜索方法并不能解决这个问题,所以需要用更智能的方法在合理的时间范围内找到频繁项集。本文分别介绍如何使用Apriori算法和FP-growth算法来解决上述问题。
关联分析是在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:
频繁项集(frequent item sets)是经常出现在一块儿的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
下面用一个例子来说明这两种概念:图1给出了某个杂货店的交易清单。
交易号码 | 商品 |
0 | 豆奶,莴苣 |
1 | 莴苣,尿布,葡萄酒,甜菜 |
2 | 豆奶,尿布,葡萄酒,橙汁 |
3 | 莴苣,豆奶,尿布,葡萄酒 |
4 | 莴苣,豆奶,尿布,橙汁 |
图1 某个杂货店的交易清单
频繁项集是指那些经常出现在一起的商品集合,图中的集合{葡萄酒,尿布,豆奶}就是频繁项集的一个例子。从这个数据集中也可以找到诸如尿布->葡萄酒的关联规则,即如果有人买了尿布,那么他很可能也会买葡萄酒。(扩展阅读:尿布与啤酒?)
我们用支持度和可信度来度量这些有趣的关系。一个项集的支持度(support)被定义数据集中包含该项集的记录所占的比例。如上图中,{豆奶}的支持度为4/5,{豆奶,尿布}的支持度为3/5。支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小值尺度的项集。
可信度或置信度(confidence)是针对关联规则来定义的。规则{尿布}->{啤酒}的可信度被定义为"支持度({尿布,啤酒})/支持度({尿布})",由于{尿布,啤酒}的支持度为3/5,尿布的支持度为4/5,所以"尿布->啤酒"的可信度为3/4。这意味着对于包含"尿布"的所有记录,我们的规则对其中75%的记录都适用。
假设我们有一家经营着4种商品(商品0,商品1,商品2和商品3)的杂货店,2图显示了所有商品之间所有的可能组合:
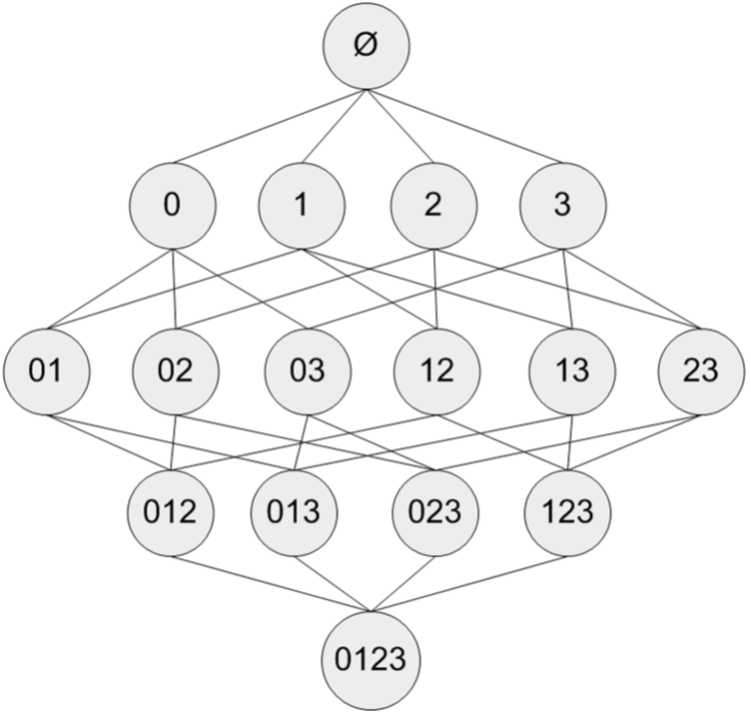
图2 集合{0,1,2,3,4}中所有可能的项集组合
对于单个项集的支持度,我们可以通过遍历每条记录并检查该记录是否包含该项集来计算。对于包含N中物品的数据集共有\( 2^N-1 \)种项集组合,重复上述计算过程是不现实的。
研究人员发现一种所谓的Apriori原理,可以帮助我们减少计算量。Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。更常用的是它的逆否命题,即如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
在图3中,已知阴影项集{2,3}是非频繁的。利用这个知识,我们就知道项集{0,2,3},{1,2,3}以及{0,1,2,3}也是非频繁的。也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的后,就可以紧接着排除{0,2,3}、{1,2,3}和{0,1,2,3}。
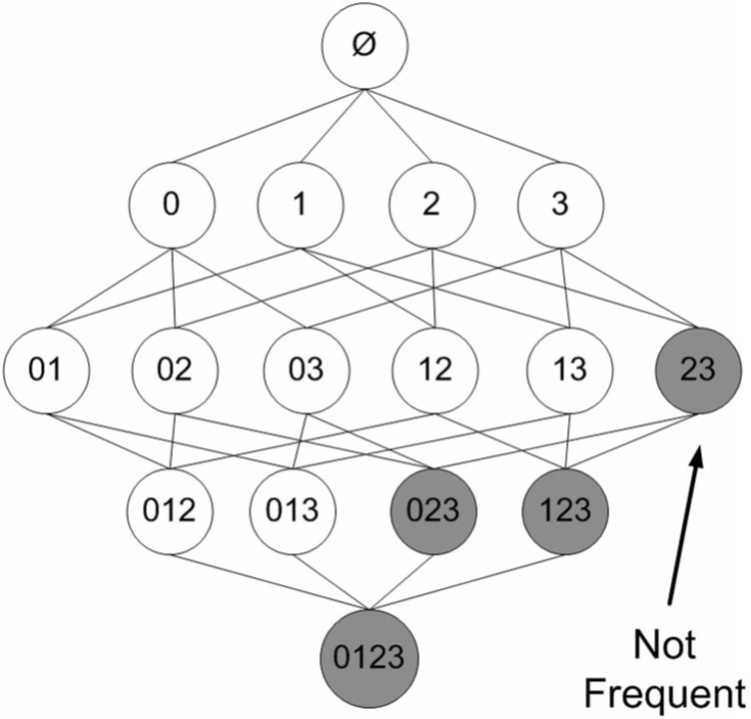
图3图中给出了所有可能的项集,其中非频繁项集用灰色表示。
前面提到,关联分析的目标包括两项:发现频繁项集和发现关联规则。首先需要找到频繁项集,然后才能获得关联规则。
Apriori算法是发现频繁项集的一种方法。Apriori算法的两个输入参数分别是最小支持度和数据集。该算法首先会生成所有单个元素的项集列表。接着扫描数据集来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉。然后,对剩下来的集合进行组合以生成包含两个元素的项集。接下来,再重新扫描交易记录,去掉不满足最小支持度的项集。该过程重复进行直到所有项集都被去掉。
数据集扫描的伪代码大致如下:
对数据集中的每条交易记录tran:
????对每个候选项集can:
????????检查can是否是tran的子集
????如果是,则增加can的计数
对每个候选项集:
????如果其支持度不低于最小值,则保留该项集
返回所有频繁项集列表
标签:
原文地址:http://www.cnblogs.com/qwertWZ/p/4510857.html