标签:
开始学iptables,因为它是和路由器技术紧密结合在一起的。
iptables的命令看起来眼花缭乱,随便找两个:
iptables -A FORWARD -p tcp -s 192.168.1.0/24 -d 192.168.1.234 --dport 80 -j ACCEPT iptables -A FORWARD -f -p tcp -s 192.168.1.0/24 -d 192.168.1.234 --dport 80 -j ACCEPT
看了一些博客,还是云里雾里的,所以开始看内核里面的实现。看了内核的实现之后,再回过来
看别人的博客,整个框架就清晰多了。
实际上iptables这个工具在新版的kernel已经换成nftable了,但是通过看kernel里面的实现,可以
掌握linux数据包控制的大体实现。
这里以3.10.79 kernel为例,这里采用的工具仍然还是iptables。
首先要搞清楚iptables的整体架构:
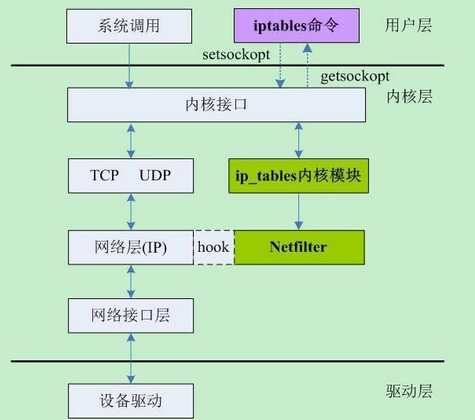
(上图转自http://segmentfault.com/a/1190000002540601)
所以说iptables对应内核的Netfilter,搞懂Netfilter是怎么工作的话,那么iptables也就容易理解了。
下面分析一个样例,从ip_rcv开始:
/* * Main IP Receive routine. */ int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { ... return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish); }
可以看到最后return的时候使用了NF_HOOK。接下来继续调用NF_HOOK_THRESH,nf_hook_thresh。
/** * nf_hook_thresh - call a netfilter hook * * Returns 1 if the hook has allowed the packet to pass. The function * okfn must be invoked by the caller in this case. Any other return * value indicates the packet has been consumed by the hook. */ static inline int nf_hook_thresh(u_int8_t pf, unsigned int hook, struct sk_buff *skb, struct net_device *indev, struct net_device *outdev, int (*okfn)(struct sk_buff *), int thresh) { if (nf_hooks_active(pf, hook)) return nf_hook_slow(pf, hook, skb, indev, outdev, okfn, thresh); return 1; }
这里先判断,再决定。
static inline bool nf_hooks_active(u_int8_t pf, unsigned int hook) { return !list_empty(&nf_hooks[pf][hook]); }
这里很简单,检查nf_hooks表中对应的项是否为0。这里若发现这个表为空的话会立马返回,也就是不进行检查。
下面整理了一下这个表里面可能的值,这个表有两部分,左边的部分是表的第一维,右边部分是表的第二维。
|
pf |
hook |
hook example function(ipv4) |
|
NFPROTO_UNSPEC |
NF_INET_PRE_ROUTING |
ip_rcv |
|
NFPROTO_IPV4 |
NF_INET_LOCAL_IN |
ip_local_deliver |
|
NFPROTO_ARP |
NF_INET_FORWARD |
ip_forward |
|
NFPROTO_BRIDGE |
NF_INET_LOCAL_OUT |
__ip_local_out |
|
NFPROTO_IPV6 |
NF_INET_POST_ROUTING |
ip_output |
|
NFPROTO_DECNET |
|
|
这里第二列举了一个例子,是关于NFPROTO_IPV4 的。
这个表是Netfilter里面最关键的一个部分,这个数组的每一个单元都是一个链表。
struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS];
这里存储了对于各种协议、各个钩子的规则信息。iptables用户层将用户定义的规则设置到对应链表里面。
接下来是一个关键的函数,nf_hook_slow。这个函数里面进行主要的检查过程。
next_hook: verdict = nf_iterate(&nf_hooks[pf][hook], skb, hook, indev, outdev, &elem, okfn, hook_thresh); if (verdict == NF_ACCEPT || verdict == NF_STOP) { ret = 1; } else if ((verdict & NF_VERDICT_MASK) == NF_DROP) { kfree_skb(skb); ret = NF_DROP_GETERR(verdict); if (ret == 0) ret = -EPERM; } else if ((verdict & NF_VERDICT_MASK) == NF_QUEUE) { int err = nf_queue(skb, elem, pf, hook, indev, outdev, okfn, verdict >> NF_VERDICT_QBITS); if (err < 0) { if (err == -ECANCELED) goto next_hook; if (err == -ESRCH && (verdict & NF_VERDICT_FLAG_QUEUE_BYPASS)) goto next_hook; kfree_skb(skb); } }
这里检查的返回结果有多个,总结表格如下:
|
Filter result |
meaning |
|
NF_DROP |
丢弃报文 |
|
NF_ACCEPT/ NF_STOP |
继续正常的报文处理 |
|
NF_STOLEN |
由钩子函数处理了该报文 |
|
NF_QUEUE |
将报文入队,交由用户程序 |
|
NF_REPEAT |
再次调用该钩子函数 |
总的来说,在数据表处理的某个阶段,Netfilter会将这个数据包遍历nf_hooks对应单元的链表的规则,然后根据规则作出相应的处理结果。
Netfilter在报文流经的一些地方做了拦截处理,可以从下图中得知:
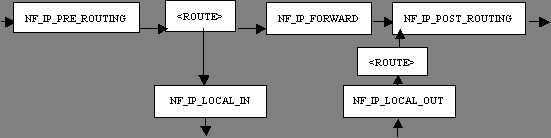
(图片转自http://www.ibm.com/developerworks/cn/linux/l-ntflt/)
前面分析的是ip_rcv,也就是NF_INET_PRE_ROUTING,这个参数和上图的名字不太一样,可能是kernel版本的问题。
我将上面的部分和代码对应起来:
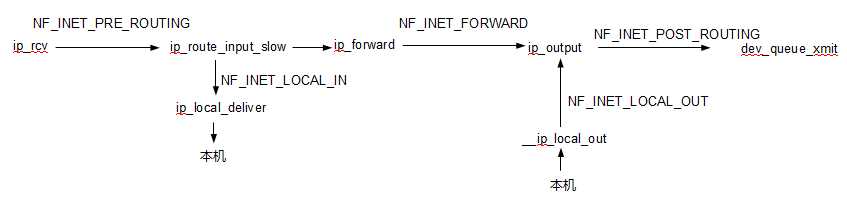
另外又仔细分析了一下代码的详细流程:
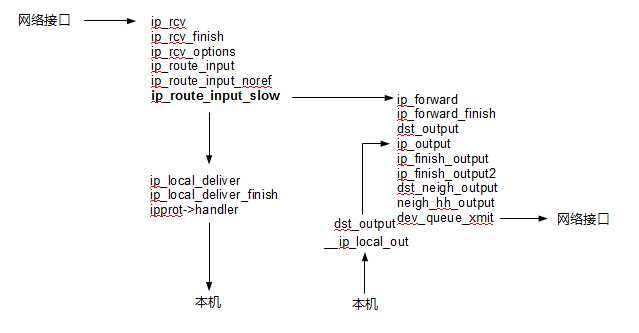
到这里为止,iptables内核部分已经可以大致了解到是怎么回事了。
关于用户层的iptables,一般是这样划分的:
表 -> 链 -> 规则
但是这样看的话一开始也不容易理解,而且不同表和不同链容易混在一起理解。
当理解了内核的Netfilter的时候,这个规则就可以这样划分了:
链 -> (表 + 规则)
因为根本上以链为主体,数据是在链之间流动的。
关于iptables网上的资料太多了,所以随便找几篇看看就可以开始上手,关于这个东西
用多了就会慢慢熟悉,另外要注意到自己设置的规则的先后顺序,如果顺序不对的话会事与愿违。
参考资料:
1.http://www.ibm.com/developerworks/cn/linux/l-ntflt/
2.http://www.360doc.com/content/08/1225/18/36491_2197786.shtml
标签:
原文地址:http://www.cnblogs.com/tanhangbo/p/4518254.html