标签:
6.1点估计及R实现
6.1.1矩估计
R中的解方程函数:
函数及所在包:功能
uniroot()@stats:求解一元(非线性)方程
multiroot()@rootSolve:给定n个(非线性)方程,求解n个根
uniroot.all()@rootSolve:在一个区问内求解一个方程的多个根
BBsolve()@BB:使用Barzilai-Borwein步长求解非线性方程组
uniroot(f,interval, ...,lower = min(interval), upper = max(interval),f.lower = f(lower,...), f.upper = f(upper, ...),extendInt = c("no", "yes","downX", "upX"), check.conv = FALSE,tol =.Machine$double.eps^0.25, maxiter = 1000, trace = 0)
其中f指定所要求解方程的函数:interval是一个数值向量,指定要求解的根的区间范围:或者用lower和upper分别指定区间的两个端点;tol表示所需的精度(收敛容忍度):maxiter为最人迭代次数。
如果遇到多元方程的求解,就需要利用rootSolve包的函数multiroot()来解方程组。multiroot()用于对n个非线性方程求解n个根,其要求完整的雅可比矩阵,采用Newton-Raphson方法。其调用格式为:
multiroot(f, start, maxiter = 100,
rtol = 1e-6, atol = 1e-8, ctol = 1e-8,
useFortran = TRUE, positive = FALSE,
jacfunc = NULL, jactype = "fullint",
verbose = FALSE, bandup = 1, banddown = 1,
parms = NULL, ...)
f指定所要求解的函数;由于使用的是牛顿迭代法,因而必须通过start给定根的初始值,其中的name属性还可以标记输出变量的名称;maxiter是允许的最大迭代次数;rtol和atol分别为相对误差和绝对误差,一般保持默认值即可;ctol也是一个用于控制迭代次数的标量,如果两次迭代的最大变化值小于ctol,那么迭代停止,得到方程组的根。
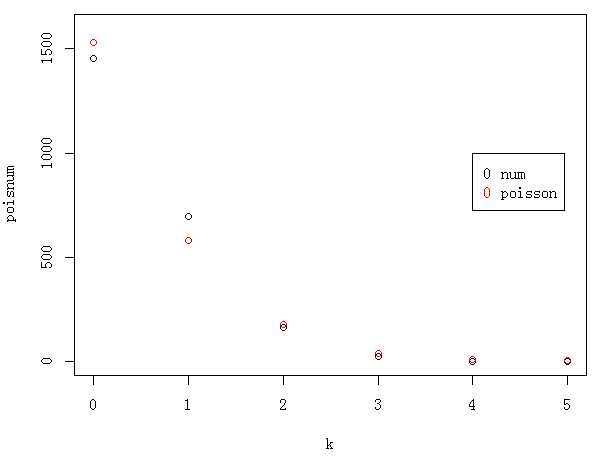
例如,己知某种保险产品在一个保单年度内的损失情况如下所示,其中给出了不同损失次数下的保单数,我们对损失次数的分布进行估计。已知分布类型是泊松(Poisson ) ,其样本均值即为参数λ的矩估计。
|
损失次数 |
0 |
1 |
2 |
3 |
4 |
5 |
|
保单数 |
1532 |
581 |
179 |
41 |
10 |
4 |
> num=c(rep(0:5,c(1532,581,179,41,10,4)))#用rep()函数生成样本,样本值有。一5的数字构成,函数中的第二个向量对应表示每个数字的重复次数 > lambda=mean(num) > lambda [1] 0.4780571
画图比较损失次数的估计值和样本值之间的差别
> k=0:5
> ppois=dpois(k,lambda)
> poisnum=ppois*length(num)#由poisson分布生成的损失次数
> plot(k,poisnum,ylim=c(0,1600))#画图比较,为图形效果更好,用参数ylim设置纵轴的范围,最小值为0,最大值要大于样本的最值,选取1600
> samplenum=as.vector(table(num))#样本的损失次数
> points(k,samplenum,type="p",col=2)
> legend(4,1000,legend=c("num","poisson"),col=1:2,pch="0")
rootSolve包的函数multiroot()用于解方程组:
> x=c(4,5,4,3,9,9,5,7,9,8,0,3,8,0,8,7,2,1,1,2)
> m1=mean(x)
> m2=var(x)
> model=function(x,m1,m2){}
> model=function(x,m1,m2){
+ c(f1=x[1]+x[2]-2*m1,
+ f2=(x[2]-x[1])^2/12-m2)
+ }
> library(rootSolve)
> multiroot(f=model,start=c(0,10),m1=m1,m2=m2)
$root
[1] -0.7523918 10.2523918
#均匀分布的两个参数值[0.75, 10.25]
$f.root
f1 f2
-5.153211e-12 1.121688e-09
$iter
[1] 4
$estim.precis
[1] 5.634204e-10
验证一下:
> m1-sqrt(3*m2);m1+sqrt(3*m2) [1] -0.7523918 [1] 10.25239
6.1.2极大似然估计
R中计算极值的函数(stats包)
optimize( ) 计算单参数分布的极人似然估计值
optim() 计算多个参数分布的极大似然估计值
nlm() 计算非线性函数的最小值点
nlminb( ) 非线性最小化函数
1.函数optimize()
当分布只包含一个参数时,我们可以使用R中计算极值的函数optimize()求极大似然估计值。
optimize(f = , interval = , ..., lower = min(interval),upper = max(interval), maximum = FALSE,tol = .Machine$double.eps^0.25)
其中f是似然函数:interval指定参数的取值范围;lower/upper分别是参数的下界和上界:maximum默认为FALSE,表示求似然函数的极小值,若为TRUE则求极大值:tol表示计算的精度。
2.函数optim()和nlm()
当分布包含多个参数时,用函数optim()或nlm()计算似然函数的极大值点。
optim(par, fn, gr = NULL, ...,method = c("Nelder-Mead", "BFGS", "CG", "L-BFGS-B", "SANN","Brent"),lower = -Inf, upper = Inf,control = list(), hessian = FALSE)
par设置参数的初始值;fn为似然函数;method提供了5种计算极值的方法
nlm(f, p, ..., hessian = FALSE, typsize = rep(1, length(p)),fscale = 1, print.level = 0, ndigit = 12, gradtol = 1e-6,stepmax = max(1000 * sqrt(sum((p/typsize)^2)), 1000),steptol = 1e-6, iterlim = 100, check.analyticals = TRUE)
nlm是非线性最小化函数,仅使用牛顿一拉夫逊算法,通过迭代计算函数的最小值点。一般只布要对前两个参数进行设置:f是需要最小化的函数:P设置参数初始值。
3.函数nlminb()
在实际应用中,上面这三个基本函数在遇到数据量较大或分布较复杂的计算时,就需要使用优化函数nlminb()
nlminb(start, objective, gradient = NULL, hessian = NULL, ...,scale = 1, control = list(), lower = -Inf, upper = Inf)
参数start是数值向量,用于设置参数的初始值;objective指定要优化的函数:gradient和hess用于设置对数似然的梯度,通常采用默认状态;control是一个控制参数的列表:lower和upper设置参数的下限和上限,如果未指定,则假设所有参数都不受约束。
例:
> library(MASS) > head(geyser,5) waiting duration 1 80 4.016667 2 71 2.150000 3 57 4.000000 4 80 4.000000 5 75 4.000000 > attach(geyser) > hist(waiting,freq=FALSE)#通过直方图了解数据分布的形态
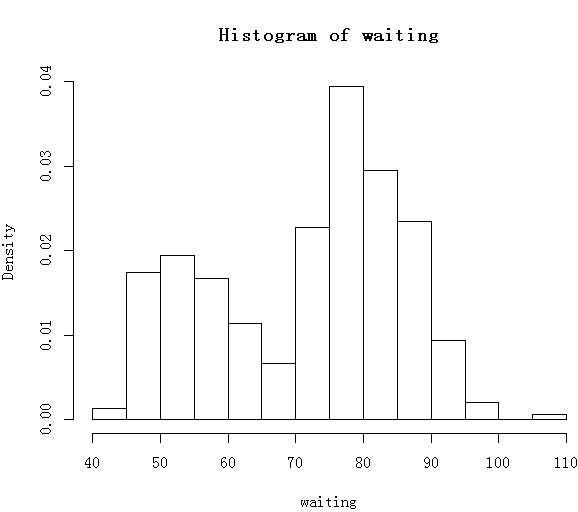

猜测分布是两个正态分布的混合,需要估计出函数中的5个参数:p、μ1、μ2、σ1、σ2。
在R中编写对数似然函数时,5个参数都存放在向量para中,由于nlminb()是计算极小值的,因此函数function中最后返回的是对数似然函数的相反数。
> l1=function(para)
+ {
+ f1=dnorm(waiting,para[2],para[3])
+ f2=dnorm(waiting,para[4],para[5])
+ f=para[1]*f1+(1-para[1])*f2
+ l1=sum(log(f))
+ return(-11)
+ }
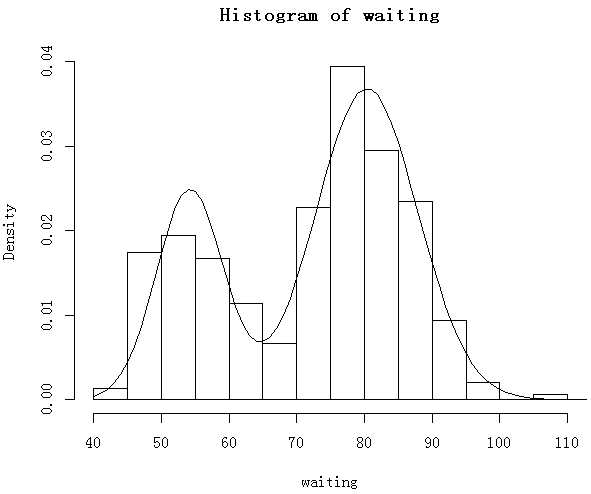
做参数估计,使用nlminb()之前最大的要点是确定初始值,初始值越接近真实值,计算的结果才能越精确。我们猜想数据的分布是两个正态的混合,概率P直接用0.5做初值即可。通过直方图中两个峰对应的x轴数值(大概为50和80>,就可以将初值设定为μ1和μ2。而概率P处于((0,1)区间内,参数σ1,σ2是正态分布的标准差,必须大于0,所以通过lower和upper两个参数进行一定的约束。
> geyser.est=nlminb(c(0.5,50,10,80,10),l1,lower=c(0.0001,-Inf,0.0001,-Inf,0.0001),upper=c(0.9999,Inf,Inf,Inf,Inf)) > options(digits=3) > geyser.est$par [1] 0.308 54.203 4.952 80.360 7.508 > p=geyser.est$par[1] > mu1=geyser.est$par[2];sigma1=geyser.est$par[3] > mu2=geyser.est$par[4];sigma2=geyser.est$par[5] > x=seq(40,120) >#将估计的参凌丈函数代入原密度函数 > f=p*dnorm(x,mu1,sigma1)+(1-p)*dnorm(x,mu2,sigma2) > hist(waiting,freq=F) > lines(x,f)
(2)使用极大似然估计函数maxLik()计算
程序包maxLik中同名的函数maxLik()可以直接计算极大似然估计值,调用格式如下:
maxLik(logLik, grad = NULL, hess = NULL, start, method,constraints=NULL, ...)
logLik是对数似然函数,grad和hess用于设置对数似然的梯度,通常不需要进行设置,采用默认值NULL即可;start是一个数值向量,设置参数的初始值;method选择求解最大化的方法,包括“牛顿-拉夫逊”、"BFGS". "BFGSR", "BHHH","SANK”和“Nelder-Mead",如果不设置,将自动选择一个合适的方法;constraints指定对似然估计的约束。
例:
采用两参数的负二项分布做极大似然估计,具体说明离散分布的拟合:
编写R程序时首先要写出对数似然函数loglik,用到R中的负二项函数dnbinom(),它的参数是r、p。如果要估计β的值,应当转换一下形式。
> num=c(rep(0:5,c(1532,581,179,41,10,4)))
> loglik=function(para)
+ {
+ f=dnbinom(num,para[1],1/(1+para[2]))
+ l1=sum(log(f))
+ return(l1)
+ }
> library(maxLik)
> para=maxLik(loglik,start=c(0.5,0.4))$estimate
> r=para[1];beta=para[2]
通过图形来观察估计的效果,比较损失次数的样本值和估计值:
> l=length(num)
> nbinomnum=dnbinom(0:5,r,1/(1+beta))*l;nbinomnum
[1] 1530.12 588.08 170.66 44.17 10.74 2.51
> plot(0:5,nbinomnum,ylim=c(0,1600))
> points(0:5,nbinomnum,type="p",col=2)
> legend(3,1000,legend=c("num","poisson"),col=1:2,lty=1)
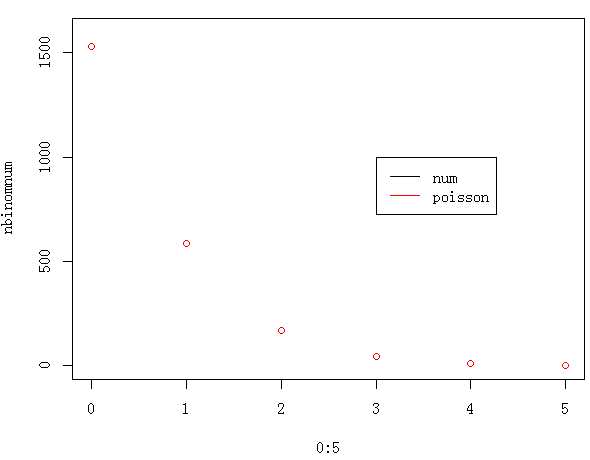
可以看出,负二项分布的极大似然估计效果非常好,估计值与样木值几乎完全重合,可以得出结论,损失次数服从负二项分布。
6.2单正态总体的区间估计
6.2.1均值μ的区间估计
(1 )σ2已知
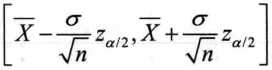
R中没有计算方差己知时均值置信区间的内置函数,需要自己编写:
conf.int=function(x,sigma,alpha){
mean=mean(x)
n=length(x)
z=qnorm(1-alpha/2,mean=0,sd=1,lower.tail=TRUE)
c(mean-sigma*z/sqrt(n),mean+sigma*z/sqrt(n))
}
其中x为数据样本;sigma是已知总体的标准差;alpha表示显著性水平。通常我们作区间估计时,都会估计出双侧的置信区间,因为它为待估参数提供了上下限两个参考值。但如果要估计单.侧的置信区间,理论上与双侧相同,只需要使用标准正态分布的α分位点即可,编写函数时也做同样变动即可。
现在基本统计和数据分析程序包BSDA (Basic Statisticsand Data Analysis )中己经提供了函数z.test(),它可以对基于正态分布的单样本和双样本进行假设检验、区间估计,其使用方法如下:
z.test(x, y = NULL, alternative = "two.sided", mu = 0, sigma.x = NULL,sigma.y = NULL, conf.level = 0.95)
其中,x和Y为数值向量,默认y=NULL,即进行单样本的假设检验;alternative用于指定所求置信区间的类型,默认为two.sided,表示求双尾的置信区间,若为less则求置信上限,为greater求置信卜限;mu表示均值,它仅在假设检验中起作用,默认为0; sigma.x和sigma.y分别指定两个样本总体的标准差:conf.level指定区间估计时的置信水平。
程序包UsingR中的函数simple.z.test(),它专门用于对方差己知的样本均值进行区间估计,与z.test()的不同点在于它只能进行置信区间估计,而不能实现Z检验。simple.z.test()
的使用方法如下:
simple.z.test (x,sigma, conf.level=0.95)
其中,x是数据向量:sigma是己知的总体标准差;conf.level指定区间估计的置信度,默认
为95% 。
例:
从均值为10、标准差为2的总体中抽取20个样本,因此这是一个方差己知
的正态分布样本。计算置信水平为95%时x的置信区间,首先调用自行编写的函数conf.int():
> conf.int=function(x,sigma,alpha){
+ mean=mean(x)
+ n=length(x)
+ z=qnorm(1-alpha/2,mean=0,sd=1,lower.tail=TRUE)
+ c(mean-sigma*z/sqrt(n),mean+sigma*z/sqrt(n))
+ }
> set.seed(111)
> x=rnorm(20,10,2)
> conf.int(x,2,0.05)
[1] 8.42 10.17
用函数z.test()也可以直接得到这一结果:
> library(BSDA) > z.test(x,sigma.x=2)$conf.int [1] 8.42 10.17 attr(,"conf.level") [1] 0.95
simple.z.test(),可以直接得到区间估计结果:
> library(UsingR) > simple.z.test(x,2) [1] 8.42 10.17
三种方法的结果均显示,该样本的95%置信区间为[8.42, 10.17]
(2 )σ2未知
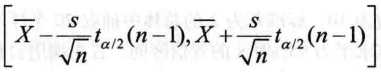
总体方差未知时,用t分布的统计量来替代z,方差也要由样本方差s2代替
t.test(x, y = NULL,alternative = c("two.sided", "less", "greater"),mu = 0, paired = FALSE, var.equal = FALSE,conf.level = 0.95, ...)
其中,x为样本数据;若x和Y同时输入,则做双样本t检验;alternative用于指定所求置信区间的类型,默认为two.sided,表示求双尾的置信区间,若为less则求置信上限,为greater求置信下限;mu表示均值,其仅在假设检验中起作用,默认为0.
仍使用上例中的向量x,假设总体方差未知时,用函数t.test()计算置信区间后:
> t.test(x)
One Sample t-test
data: x
t = 22.6, df = 19, p-value = 3.407e-15
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
8.43 10.15
sample estimates:
mean of x
9.29
如果只要区间估计的结果,则用符号“$”选取conf.int的内容:
> t.test(x)$conf.int [1] 8.43 10.15 attr(,"conf.level") [1] 0.95
6.2.2方差σ2的区间估计
(1)μ已知
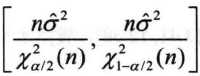
(2) μ未知
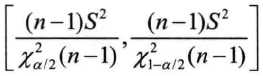
在R中没有直接计算方差的置信区间的函数,我们可以把上面两种情况写在一个函数里,通过一个if语句进行判断,只要是方差的区间估计,都调用这个函数即可。在R中写函数时,参数可以事先设定一个初值,例如设mu=Inf,代表均值未知的情况,调用函数时如果没有特殊说明mu的值,将按照均值未知的方法计算;如果均值己知,在调用函数时应该对mu重新赋值。
> var.conf.int=function(x,mu=Inf,alpha){
+ n=length(x)
+ if(mu<Inf){
+ s2=sum((x-mu)^2)/n
+ df=n
+ }
+ else{
+ s2=var(x)
+ df=n-1
+ }
+ c(df*s2/qchisq(1-alpha/2,df),df*s2)/qchisq(alpha/2,df)
+ }
> var.conf.int(x,alpha=0.05)
[1] 5.35 39.50
计算得到总体方差的置信区间为【5.35,39.5],置信水平是95%

【数据分析 R语言实战】学习笔记 第六章 参数估计与R实现(上)
标签:
原文地址:http://www.cnblogs.com/jpld/p/4523326.html