Apache Flink是一个可伸缩的开源批处理和流处理平台。其核心模块是一个数据流引擎,该引擎在分布式的流数据处理的基础上提供数据分发、交流、以及容错的功能,其架构图如下:
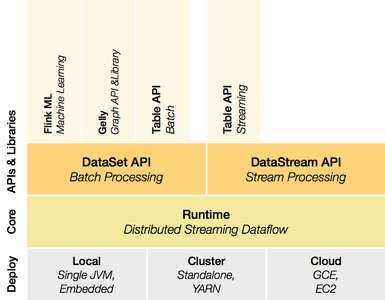
该引擎包含如下APIs:
1. DataSet API for static data embedded in Java, Scala, and Python
2. DataStream API for unbounded streams embedded in Java and Scala, and
3. Table API with a SQL-like expression language embedded in Java and Scala.
Flink也包含了一些其他领域的组件:
1.Machine Learning library
2.Gelly, a graph processing API and library
Flink支持java和scala语言的数据处理API,有一个优化的分布式运行自定义内存管理。
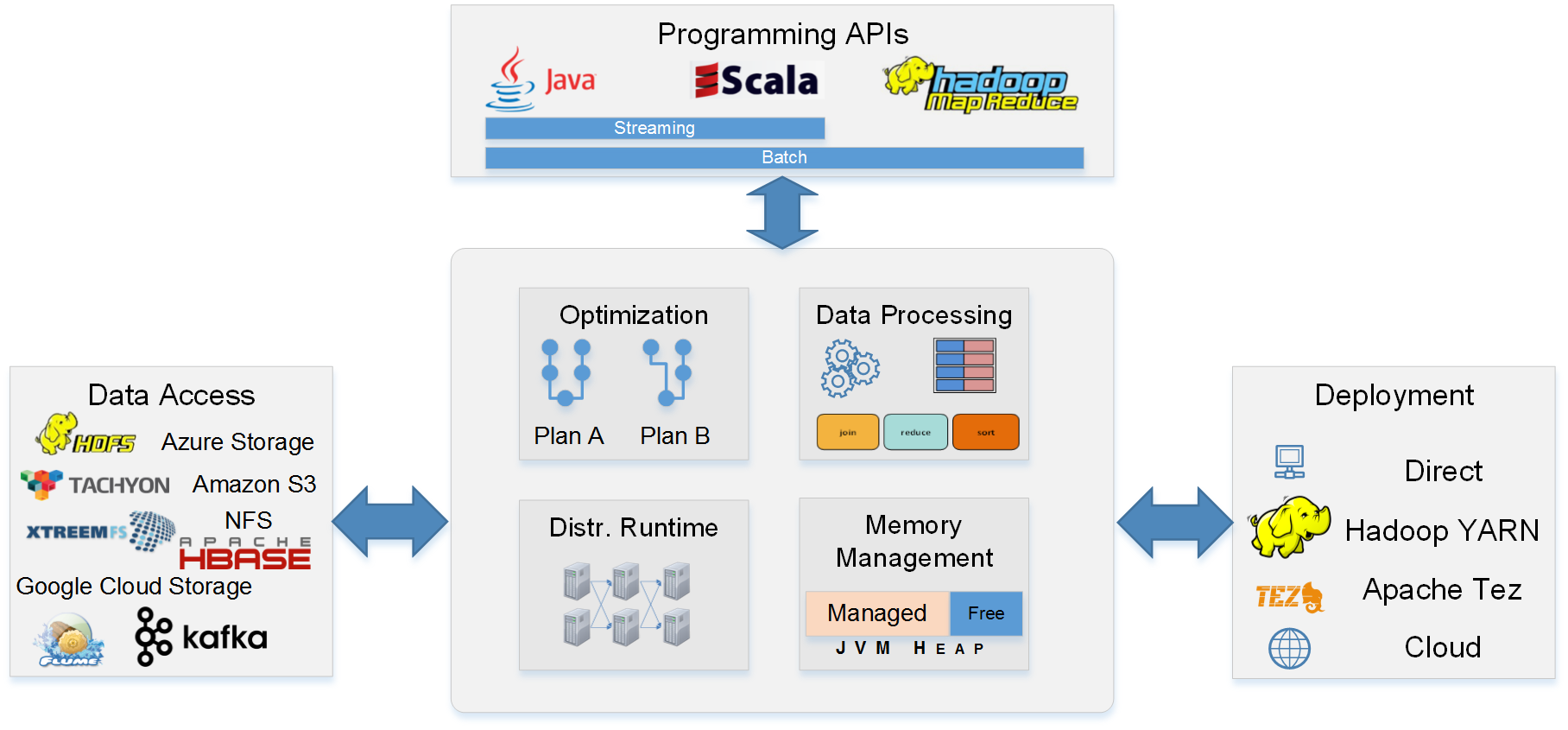
1、Fast,Flink在运行时利用内存数据流和集成迭代处理,这样对于数据密集型计算和迭代计算变的很快
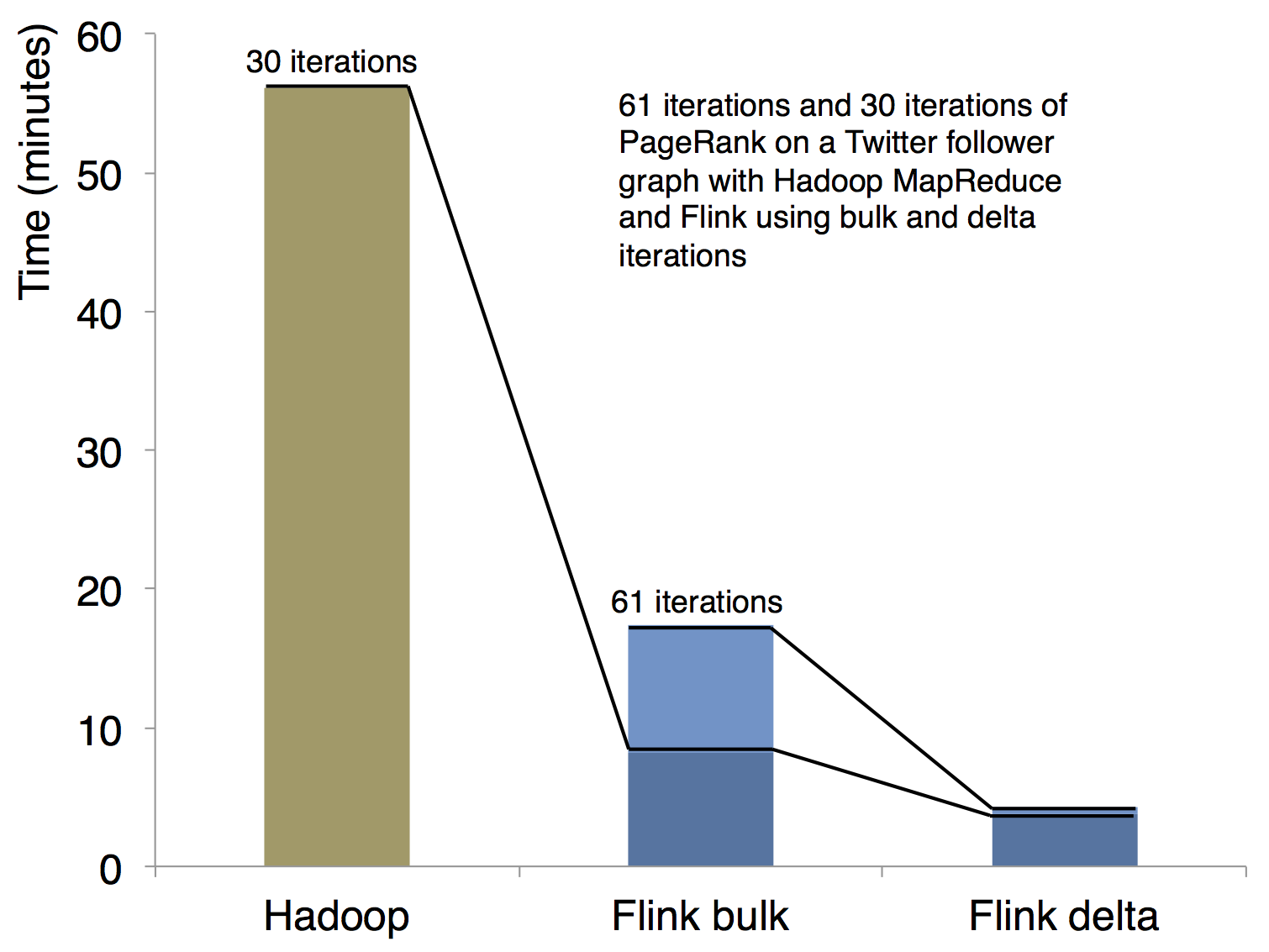
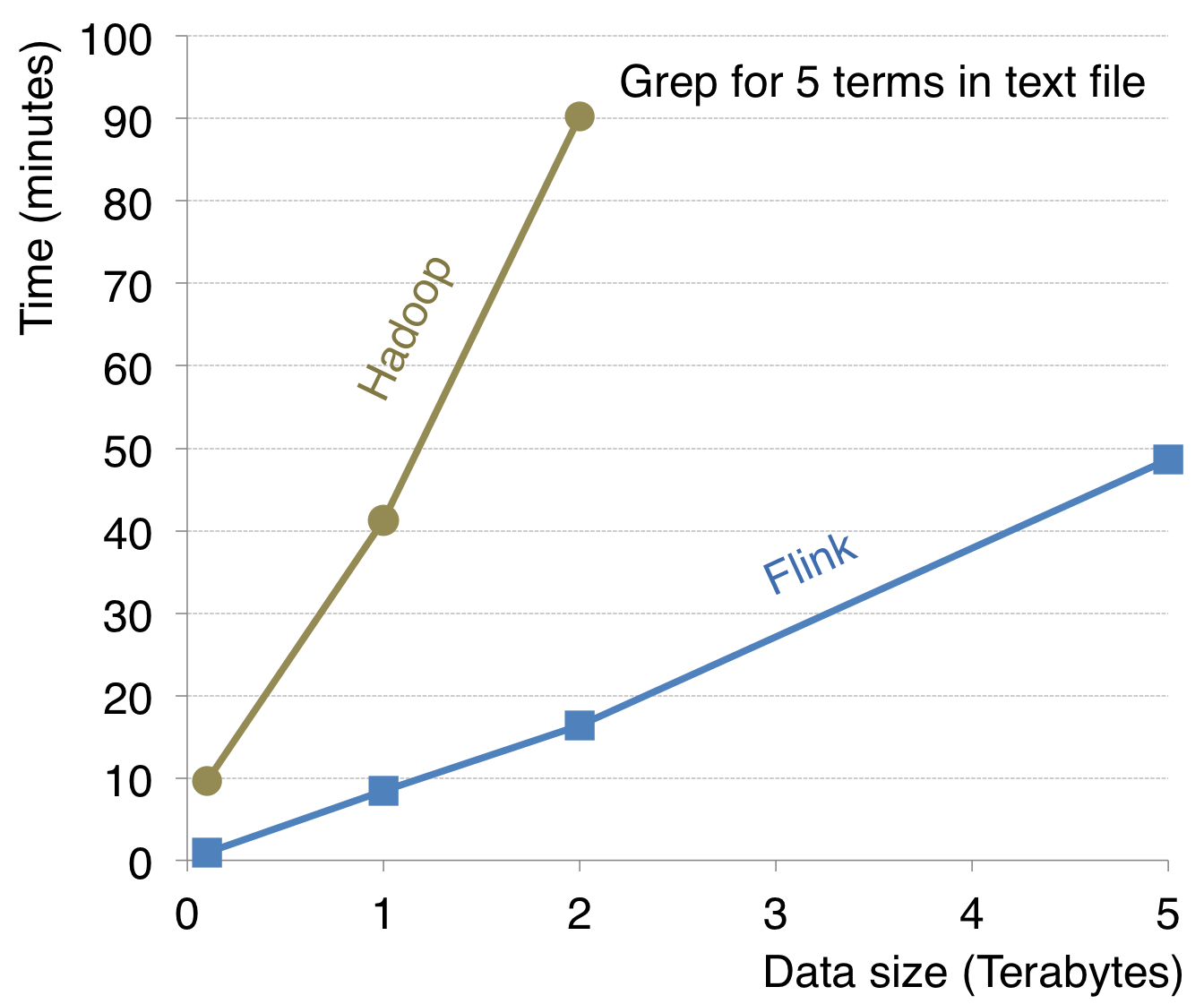
2、高可靠性和高伸缩性。Flink包含自己的内存管理组件,序列化组件和type inference组件。
3、优雅美观的API设计
workcount scala示例
case class Word (word: String, frequency: Int)
val counts = text
.flatMap {line => line.split(" ").map(
word => Word(word,1))}
.groupBy("word").sum("frequency"
Closure代码示例
case class Path (from: Long, to: Long)
val tc = edges.iterate(10) { paths: DataSet[Path] =>
val next = paths
.join(edges).where("to").equalTo("from") {
(path, edge) => Path(path.from, edge.to)
}
.union(paths).distinct()
next
}
4、可兼容Hadoop,可在YARN上运行
原文地址:http://blog.csdn.net/wzhg0508/article/details/45968577