标签:
要实现的部分为:forward prop, softmax函数的cost function,每一层的gradient,以及penalty cost和gradient。
forward prop是输入sample data,使sample data通过神经网络后得到神经网络输出的过程。
以分类问题来说,不同层的输入和输出如下表所示:
| 层 | 输入 | 输出 |
| 输入层 | sample data | feature map |
| 隐藏层 | feature map | feature map |
| 输出层 | feature map | probabilities of each potential class |
所以输入层的输出是sigmoid(W1X+b1),隐藏层的输出是sigmoid(Wlzl-1+bl),而输出层的输出是最终的概率:exp(Wz+b)。代码如下
1 %% forward prop 2 %%% YOUR CODE HERE %%% 3 %隐藏层 4 5 for l = 1:numHidden 6 if(l == 1) 7 z = stack{l}.W * data; 8 else 9 z = stack{l}.W * hAct{l-1}; 10 end 11 z = bsxfun(@plus,z,stack{l}.b);%%z:256*60000 b:256*1 12 hAct{l} = 1./(1+exp(-z)); 13 end 14 %输出层 15 h = exp(bsxfun(@plus,stack{numHidden+1}.W * hAct{numHidden},stack{numHidden+1}.b)); 16 pred_prob = bsxfun(@rdivide,h,sum(h,1)); 17 hAct{numHidden+1} = pred_prob;%最后一层输出的实际上是预测的分类结果
这一步和之前的softmax差别在教程中说的很清楚了:“Note that instead of making predictions from the input data x the softmax function takes as input the final hidden layer of the network”。即分类器的输入不是input data,而是最后一层隐藏层输出的feature map,所以softmax函数的cost function如下:
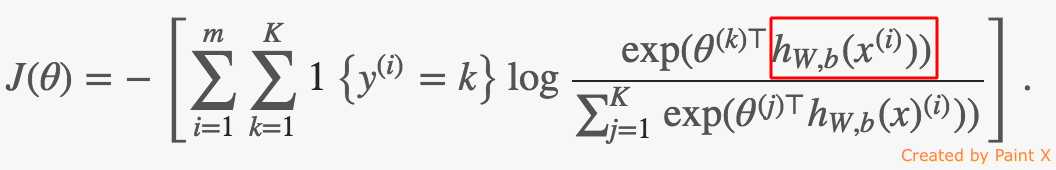
红框中的h就是输出层输出的概率向量pred_prob。代码如下,细节课参见原始的softmax
1 %% compute cost计算softmax函数的损失函数 2 %%% YOUR CODE HERE %%% 3 logp = log2(pred_prob); 4 index = sub2ind(size(logp),labels‘,1:size(pred_prob,2)); 5 ceCost = -sum(logp(index));
BP(BackPropagation)算法方便的计算了每一层的对应的梯度
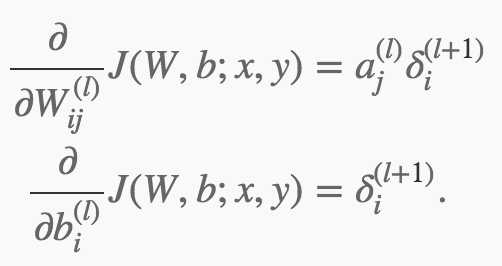
其中a是l层的激励(wx+b),δ是每一层的error。
这个公式个人认为有问题,正确的公式应该是:
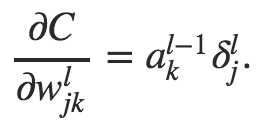 也就是说l层的W由l-1层的激励和l层的error得到,而不是上述l层的激励和l+1层的error。同样的,cost function对b的导数也应该由下述公式得到:
也就是说l层的W由l-1层的激励和l层的error得到,而不是上述l层的激励和l+1层的error。同样的,cost function对b的导数也应该由下述公式得到:
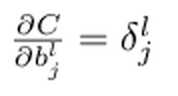 即由l层的error得到,而不是l+1层的error得到。后面代码实现的时候也是根据这两个公式。
即由l层的error得到,而不是l+1层的error得到。后面代码实现的时候也是根据这两个公式。
也有可能是我理解错了,欢迎大神指出~详细的推倒过程可以参见这里。
对于输出层,我们很容易用groun_truth_label - output的方式计算error,而对于隐藏层,则要用下面的公式计算error:
δl = Wδl+1 * f‘(zl)
其中z是wx+b,f是sigmoid函数,这个函数有一个很好的性质就是:f‘(x) = f(x) * (1-f(x)), 计算起来非常方便。代码如下:
1 %% compute gradients using backpropagation 2 3 %%% YOUR CODE HERE %%% 4 %输出层 5 output = zeros(size(pred_prob)); 6 output(index) = 1; 7 error = pred_prob - output; 8 9 for l = numHidden+1 : -1 :1 10 gradStack{l}.b = sum(error,2); 11 if(l == 1) 12 gradStack{l}.W = error * data‘; 13 break; 14 else 15 gradStack{l}.W = error * hAct{l-1}‘; 16 end 17 error = (stack{l}.W)‘*error .* hAct{l-1} .* (1-hAct{l-1});%此处的error对应是l-1层的error 18 end
这里主要是为了防止过拟合,所以对w加了一个正则项。最终的cost function由误差和对w约束的正则项共同组成,cost function对w的导数中也多了一项正则项对w的求导,代码如下:
%% compute weight penalty cost and gradient for non-bias terms %%% YOUR CODE HERE %%% %penalty cost wCost = 0; for l = 1:numHidden+1 wCost = wCost + 0.5*ei.lambda * sum(stack{l}.W(:) .^ 2); end cost = ceCost + wCost; %gradient for non-bias terms for l = numHidden:-1:1 gradStack{l}.W = gradStack{l}.W + ei.lambda * stack{l}.W; end
参考资料:
[1]http://neuralnetworksanddeeplearning.com/chap2.html
[2]http://ufldl.stanford.edu/tutorial/supervised/MultiLayerNeuralNetworks/
[3]http://blog.csdn.net/lingerlanlan/article/details/38464317
[ufldl]Supervised Neural Networks
标签:
原文地址:http://www.cnblogs.com/sunshineatnoon/p/4528803.html