标签:
假设检验及R实现
7.1假设检验概述
对总体参数的具体数值所作的陈述,称为假设;再利用样本信息判断假设足否成立,这整个过程称为假设检验。
7.1.1理论依据
假设检验之所以可行,其理沦背景是小概率理论。小概率事件在一次试验中儿乎是不可能发生的,但是它一以发生,我们就有理由拒绝原假设:反之,小概率事件没有发生,则认为原假设是合理的。这个小概率的标准由研究者事先确定,即以所谓的显著性水平α(0<α<1)作为小概率的界限,α的取值与实际问题的性质相关,通常我们取α=0.1, 0.05或0.01,假设检验也称为显著性检验。
7 .1.2检验步骤
(1) 提出假设
(2) 确定检验统计量,计算统计量的值
(3) 规定显著性水平,建立检验规则
(4) 作出统计决策
临界值规则:
双侧检验:|统计量|>临界值时,拒绝H0
左侧检验:统计量<=临界值时,拒绝H0
右侧检验:统计量>临界值时,拒绝H0
p值规则:
在一个假设检验问题中,拒绝原假设H0,的最小显著性水平称为检验的p值。p值可以告诉我们,如果原假设是正确的话,我们得到目前这个样本统计值的可能性有多人,如果这个可能性很小,就应该拒绝原假设。也就是说,P值越小,拒绝H0的可能性越大。在显著性水平α下,P值规则为:如果P≤α,则拒绝H0;如果P>a,则不拒绝原假设。
7.1.3两类错误

7.2单正态总体的检验
单正态总体的假设检验方法:
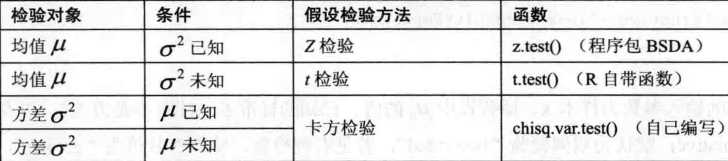
7.2.1均值μ的检验
(1) σ2已知
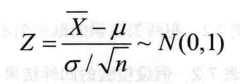
R自带的函数中只提供了t检验的函数t.test(),而没有Z检验的函数,自己编写函数z.test(),用于计算z统计量的值以及P值:
> z.test=function(x,mu,sigma,alternative="two.sided"){
+ n=length(x)
+ result=list() #构造一个空的list,用于存放输出结果
+ mean=mean(x)
+ z=(mean-mu)/(sigma/sqrt(n)) #计算z统计量的值
+ options(digits=4) #结果显示至小数点后4位
+ result$mean=mean;result$z=z #将均值、z值存入结果
+ result$P=2*pnorm(abs(z),lower.tail=FALSE) #根据z计算P值
+ #若是单侧检验,重新计算P值
+ if(alternative=="greater") result$P=pnorm(z,lower.tail=FALSE)
+ else if(alternative=="less") result$P=pnorm(z)
+ result
+ }
BSDA包提供了函数z.test( ),它可以对基于正态分布的单样本和双样本进行假设检验,其使用方法如下:
z.test(x,y=NULL,alternative="two.sided",mu=0,sigma.x=NULL,sigma.y=NULL, onf.level = 0.95)
其中,x和Y为数值向量,默认y=NULL,即进行单样本的假设检验:alternative用于指定求置信区问的类型,默认为two.sided>表示求双尾的置信区间,为less则求置信上限,greater求置信F限:mu表示均值,仅在假设检验中起作用,默认为0;sigma.x和sigma.y分别指定两个样本总体的标准差。
例:
东方财富数据中心可以获得2012年各月北京市的新建住宅价格指数,是否服从均值为102.4、方差为0.45(标准差为0.67)的正态分布
> bj=c(102.5,102.4,102.0,101.8,101.8,102.1,102.3,102.5,102.6,102.8,103.4,104.2) > z.test(x=bj,mu=102.4,sigma=0.67,alternative="two.sided") $mean [1] 102.5 $z [1] 0.6894 $P [1] 0.4906
使用程序包BSDA中的函数z.test()
> library(BSDA) > z.test(x=bj,mu=102.4,sigma=0.67,alternative="two.sided") $mean [1] 102.5 $z [1] 0.6894 $P [1] 0.4906
检验的结果是,由于P =0.4906> a =0.05,因此在0.05的显署性水平下,不能拒绝原假设,认为2012年各月北京的新建住宅价格指数服从均值为102.4的正态分布。
(2)σ2未知
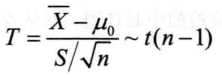
直接调用t检验函数t.test()即可:
t.test(x, y = NULL,alternative = c("two.sided", "less", "greater"),mu = 0, paired = FALSE, var.equal = FALSE,conf.level = 0.95, ...)
其中,x为样本数据,若仅出现x,则进行单样本t检验:若x和Y同时输入,则做双样本t检验;alternative用于指定所求置信区间的类型,默认为two.sided,表示求双尾的置信区问,若为less则求置信上限,greater求置信下限:mu表示均值,表示原假设中事先判断的均值,默认值为0 ; paired是逻辑值,表示是否进行配对样本t检验,默认为不配对;var.equal也是逻辑值,表示双样本检验时两个总体的方差是否相等;另外,这个函数还可以直接计算置信IX问,conf.level用来表示区间的置信水平。
> t.test(x=bj,mu=102.4,alternative="less")
One Sample t-test
data: bj
t = 0.67, df = 11, p-value = 0.7
alternative hypothesis: true mean is less than 102.4
95 percent confidence interval:
-Inf 102.9
sample estimates:
mean of x
102.5
7.2.2方差σ2的检验
(1) μ已知
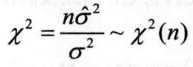
(2) μ未知
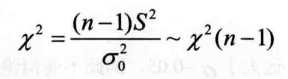
R中没有直接的函数可以做样本方差的卡方检验(只有检验卡方分布的函数),所以我们把上述两种情形写在同一个函数chisq.var.test()中,调用它就可以直接做各种情形的单样本方差检验。应用到2012年北京市新建住宅价格指数的案例中,如果样本方差保持在一定范围内,则说明房价比较稳定,l}}此我们在0.05的显著性水平下检验总体方差是否不超过0.25。
> chisq.var.test=function(x,var,mu=Inf,alternative="two.sided"){
+ n=length(x)
+ df=n-1 #均值未知时的自由度
+ v=var(x) #均值未知时的方差估计值
+ #总体均值已知的情况
+ if(mu<Inf){df=n;v=sum((x-mu)^2)/n}
+ chi2=df*v/var #卡方统计量
+ options(digits=4)
+ result=list() #产生存放结果的列表
+ result$df=df;result$var=v;result$chi2=chi2;
+ result$P=2*min(pchisq(chi2,df),pchisq(chi2,df,lower.tail=F))
+ #若是单侧检验,重新计算P值
+ if(alternative=="greater") result$P=pchisq(chi2,df,lower.tail=F)
+ else if(alternative=="less") result$P=pchisq(chi2,df)
+ result
+ }
> chisq.var.test(bj,0.25,alternative="less")
$df
[1] 11
$var
[1] 0.4752
$chi2
[1] 20.91
$P
[1] 0.9656
检验的结果为P值非常大,远大于a=0.05 ,因此不能拒绝原假设,说明新建住宅价格指数的方差大于0.25,变动很大。
7.3两正态总体的检验
单正态总体的假设检验方法:
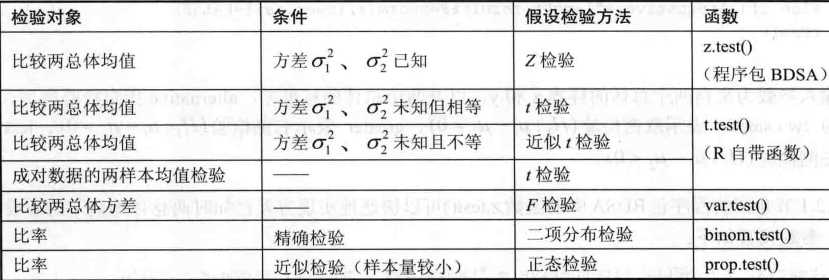
7.3.1均值差的检验
(1)两个总体的方差已知
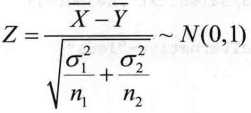
编写均值差的正态检验函数z.test2()
> z.test2=function(x,y,sigma1,sigma2,alternative="two.sided"){
+ n1=length(x);n2=length(y)
+ result=list() #构造一个空的list,用于存放输出结果
+ mean=mean(x)-mean(y)
+ z=mean/sqrt(sigma1^2/n1+sigma2^2/n2) #计算z统计量的值
+ options(digits=4) #结果显示至小数点后4位
+ result$mean=mean;result$z=z #将均值、z值存入结果
+ result$P=2*pnorm(abs(z),lower.tail=FALSE) #根据z计算P值
+ #若是单侧检验,重新计算P值
+ if(alternative=="greater") result$P=pnorm(z,lower.tail=FALSE)
+ else if(alternative=="less") result$P=pnorm(z)
+ result
+ }
程序包BDSA中的函数z.test()可以快速地实现方差己知时两总体均值差的假设检验。
以Bamberger‘s百货公司的数据为例,公司实施延长营业时间的改革计划,假设已知改革前后销售额的总体标准差分别为8和12,检验这项措施对销售业绩是否有显著影响。
> sales=read.table("D:/Program Files/RStudio/sales.txt",header=T)
> attach(sales)
> z.test2(prior,post,8,12,alternative="less")
$mean
[1] -24.54
$z
[1] -8.843
$P
[1] 4.678e-19
使用函数z.test()可以得到相同的结果,同时还可以输出置信区间估计。
> z.test(prior,post,sigma.x=8,sigma.y=12,alternative="less")
Two-sample z-Test
data: prior and post
z = -8.8, p-value <2e-16
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
NA -19.98
sample estimates:
mean of x mean of y
60.61 85.16
表明延长营业时间后销售额更高
(2)两个总体的方差未知但相等
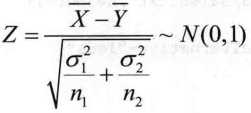
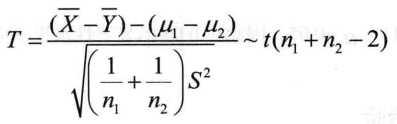
(3)两个总体的方差未知且不等
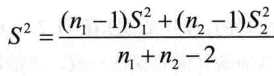
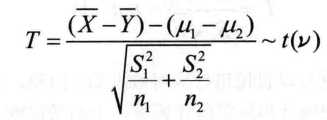
> t.test(prior,post,var.equal=FALSE,alternative="less")
Welch Two Sample t-test
data: prior and post
t = -8.4, df = 44, p-value = 6e-11
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
-Inf -19.62
sample estimates:
mean of x mean of y
60.61 85.16
7.3.2成对数据的t检验
> x=c(117,127,141,107,110,114,115,138,127,122)
> y=c(113,108,120,107,104,98,102,132,120,114)
> t.test(x,y,paired=TRUE,alternative="greater")
Paired t-test
data: x and y
t = 4.6, df = 9, p-value = 7e-04
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
6.002 Inf
sample estimates:
mean of the differences
10
p远小于a=0.05 ,拒绝原假设,说明药物组均值明显降低,该药物有降压作用。
7.3.3两总体方差的检验
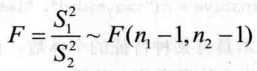
R中的函数var.rest()做方差比较的F检验以及相应的区问估计
> var.test(prior,post)
F test to compare two variances
data: prior and post
F = 0.39, num df = 26, denom df = 26, p-value = 0.02
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1772 0.8534
sample estimates:
ratio of variances
0.3889
检验结果的P =0.01914<a=0.05,故拒绝原假设,说明延长营业时间前后销售额的方差不相同。
7.4比率的检验
7.4.1比率的二项分布检验
在R中使用函数binom.test()完成:
binom.test(x,n,p=0.5,alternative=c("two.sided","less","greater"),conf.level = 0.95)
例:
2000户家庭中人均不足5平米的困难户有214个,政府希望将总体中困难户的比率控制在10%左右,判断这一目标是否达到。
> binom.test(214,2000,p=0.1)
Exact binomial test
data: 214 and 2000
number of successes = 210, number of trials = 2000,
p-value = 0.3
alternative hypothesis: true probability of success is not equal to 0.1
95 percent confidence interval:
0.09379 0.12138
sample estimates:
probability of success
0.107
由于p=0.2966>a=0.05,故不能拒绝原假设,说明总体居民的困难户比率保持在10%左右。检验结果还给出了置信区问和样本比率估计值0.107
7.4.2比率的近似检验
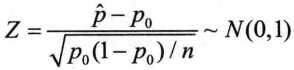
大样本,可以使用正态检验方法代替二项分布:
> prop.test(214,2000,p=0.1)
1-sample proportions test with continuity correction
data: 214 out of 2000, null probability 0.1
X-squared = 1, df = 1, p-value = 0.3
alternative hypothesis: true p is not equal to 0.1
95 percent confidence interval:
0.09396 0.12157
sample estimates:
p
0.107
7.5非参数的检验
7.5.1总体分布的c2检验
(1)理论分布已知
R软件中提供了实现Pearson拟合优度卡方检验的函数chisq.test(),其调用格式为
chisq.test(x, y = NULL, correct = TRUE,p = rep(1/length(x), length(x)), rescale.p = FALSE,simulate.p.value = FALSE, B = 2000)
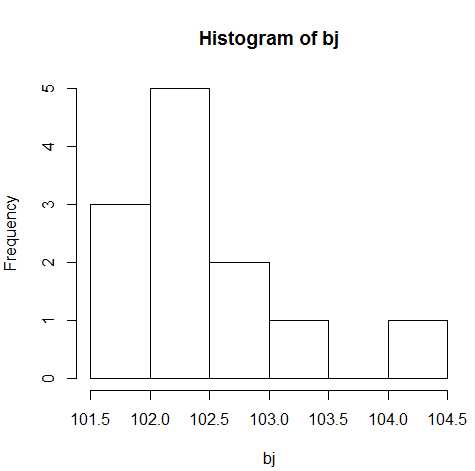
> bj=c(102.5,102.4,102.0,101.8,101.8,102.1,102.3,102.5,102.6,102.8,103.4,104.2) > hist(bj)
函数cut()用于将变量的区域分成若干区间,其调用格式为
cut(x, breaks, labels = NULL,include.lowest = FALSE, right = TRUE, dig.lab = 3,ordered_result = FALSE, ...)
函数table()可以计算因子合并后的个数,以列联表的形式展示出每个区间的数据频数。
table(..., exclude = if (useNA == "no") c(NA, NaN), useNA = c("no","ifany", "always"), dnn = list.names(...), deparse.level = 1)
> A=table(cut(bj,breaks=c(101.4,101.9,102.4,102.9,104.5))) #两个函数嵌套使用
> A
(101.4,101.9] (101.9,102.4] (102.4,102.9] (102.9,104.5]
2 4 4 2
> br=c(101.5,102,102.5,103,104.5)
> p=pnorm(br,mean(bj),sd(bj)) #注意pnorm()计算出的是分布函数
> p=c(p[1],p[2]-p[1],p[3]-p[2],1-p[3])
> options(digits=2)
> p
[1] 0.067 0.153 0.261 0.519
> chisq.test(A,p=p)
Chi-squared test for given probabilities
data: A
X-squared = 7, df = 3, p-value = 0.06
总体分布的卡方检验结果为P=0.05849> a =0.05 ,因此在0.05的显著性水平下,不能够拒绝原假设,可以认为北京市新建住宅价格指数服从正态分布。
7.5.2Kolmogrov-Smirnov检验
(1)单样本KS检验
Kolmogorov-Smirnov检验是用来检验一个数据的观测经验分布是否是已知的理论分布,当两者之间的差距很小时可以认为该样本取自己知的理论分布。KS检验通过经验分布与假设分布的上确界来构造统计量,因此它可以检验任何分布类型:
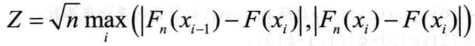
ks.test(x, y, ...,alternative = c("two.sided", "less", "greater"),exact = NULL)
对一台设备进行寿命检验,一记录10次无故障工作时间,检验其是否服从参数为1/1500的指数分布
> X=c(420,500,920,1380,1510,1650,1760,2100,2300,2350)
> ks.test(X,"pexp",1/1500) #pxep为指数分布累积分布函数的名称,1/1500为指数分布参数
One-sample Kolmogorov-Smirnov test
data: X
D = 0.3, p-value = 0.3
alternative hypothesis: two-sided
单样本KS检验的结果为P值=0.2654,其大于显著性水平0.05,因此不能拒绝原假设,说明该设备的寿命服从λ=1/1500的指数分布。
(2)两样本KS检验
假设有分别来自两个独立总体的两样本,要想检验它们背后的总体分布是否相同,就可以进行两独立样本的KS检验。原理与单样本相同,只需要把原假设中的分布换成另一个样本的经验分布即可。
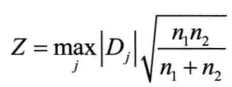
例:
有分别从两个总体抽取的25个和20个观测值的随机样本,判断它们是否来自同一分布。
> xx=c(0.61,0.29,0.06,0.59,-1.73,-0.74,0.51,-0.56,0.39,1.64,0.05,-0.06,0.64,-0.82,0.37,1.77,1.09,-1.28,2.36,1.31,1.05,-0.32,-0.40,1.06,-2.47)
> yy=c(2.20,1.66,1.38,0.20,0.36,0.00,0.96,1.56,0.44,1.50,-0.30,0.66,2.31,3.29,-0.27,-0.37,0.38,0.70,0.52,-0.71)
> ks.test(xx,yy)
Two-sample Kolmogorov-Smirnov test
data: xx and yy
D = 0.2, p-value = 0.5
alternative hypothesis: two-sided
(3) KS检验与卡方检验的比较
KS检验与卡方检验的相同之处在一于它们都是采用实际频数和期望频数之差进行检验。但不同点在于,卡方检验必须先将数据分组才能获得实际的观测频数,而KS检验法可以直接对原始数据的n个观测值进行检验,所以它对数据的利用更完整。另外在使用范围上,卡方检验主要用于分类数据,而KS检验主要用于有计量单位的连续和定量数据。
KS检验作为一种非参数方法,具有稳健性。它不依赖于均值的位置,对数据量纲不敏感,一般来讲比卡方检验更有效。与其他参数检验不同,KS检验的适用范围非常广,不像t检验一样局限于正态分布(当数据偏离较大时t检验会失效)。
标签:
原文地址:http://www.cnblogs.com/jpld/p/4529258.html