标签:
ROCK (RObust Clustering using linKs) 聚类算法是一种鲁棒的用于分类属性的聚类算法。该算法属于凝聚型的层次聚类算法。之所以鲁棒是因为在确认两对象(样本点/簇)之间的关系时考虑了他们共同的邻居(相似样本点)的数量,在算法中被叫做链接(Link)的概念。而一些聚类算法只关注对象之间的相似度。
ROCK 算法中用到的四个关键概念
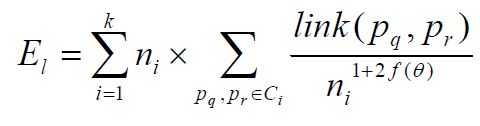
4. 相似性的度量(Goodness Measure):使用该公式计算所有对象的两两相似度,将相似性最高的两个对象合并。通过该相似性度量不断的凝聚对象至k个簇,最终计算上面目标函数值必然是最大的。
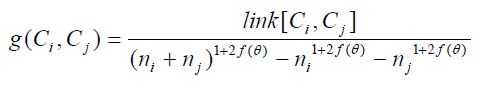 ,link[Ci,Cj]=
,link[Ci,Cj]=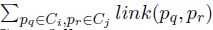
大概算法思路(伪代码请见参考文献2):
输入:需要聚类的个数-k,和相似度阈值-θ
算法:
开始每个点都是单独的聚类,根据计算点与点间的相似度,生成相似度矩阵。
根据相似度矩阵和相似度阈值-θ,计算邻居矩阵-A。如果两点相似度>=θ,取值1(邻居),否则取值0.
计算链接矩阵-L=A x A
计算相似性的度量(Goodness Measure),将相似性最高的两个对象合并。回到第2步进行迭代直到形成k个聚类或聚类的数量不在发生变换。
输出:
簇和异常值(不一定存在)
ROCK in R - cba 包:
load(‘country.RData‘) d<-dist(countries[,-1]) x<-as.matrix(d) library(cba) rc <- rockCluster(x, n=4, theta=0.2, debug=TRUE) rc$cl
参考文献:
【1】http://www.enggjournals.com/ijcse/doc/IJCSE12-04-05-248.pdf
【2】http://www.cis.upenn.edu/~sudipto/mypapers/categorical.pdf
标签:
原文地址:http://www.cnblogs.com/1zhk/p/4539645.html