标签:blog http com strong 数据 2014
推倒重来
俗话说no zuo no die why you try,这时候我又忍不住zuo了,吭哧吭哧的把解决过程发上博客,向全世界宣布,哥又搞定个难题。
剧情的发展往往是看起来主角完全掌握了局势的情况下,会突然跳出来一个很牛的反面人物,然后搞得主角很惨,搞的过程中主角开始小宇宙爆发,然后逆袭。这次也不例外。踢场子的人该出现了
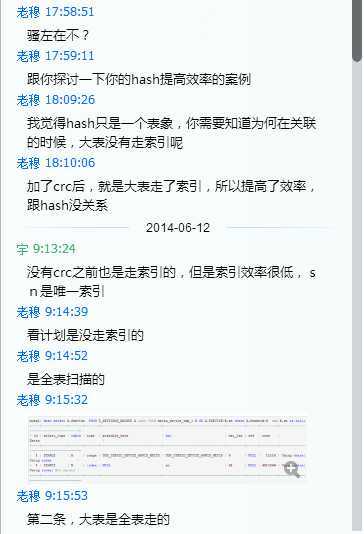
一顿狂侃之后,发现我原来牛逼的分析,完全经不起推敲。几个问题
1) 在未做HASH索引之前,为什么大表的ROWS那么大,相当于全表扫描
2) 既然SN是唯一索引,那么为什么关联查询的时候不能准确定位?
3) 在做了HASH索引之后,关联查询只是换了不同的判断字段,就能做到rows=1,这是为何?
在这里阐释一下通过索引是怎样做JOIN操作和索引定位数据的
在关系数据库里,常见的处理JOIN的方法有几种:NESTED LOOP,HASH JOIN,SORT MERGE JOIN,各种JOIN有什么差别WIKI上有详细的介绍。MYSQL实现的是NESTED LOOP,俗称嵌套循环。
结合前面的查询来看,JOIN的关联字段是FDEVICE和FSN,查询的过程是这样的
FOR FDEVICE IN A:
FOR FSN IN B:
IF A.FDEVICE=B.FSN:
Store result into record buffer
Send result
嵌套循环就是这么实现的。
在IF A.FDEVICE=B.FSN:这一步,对B表数据进行比较时,B的FSH上有索引,先通过索引查找,得到主键ID,然后根据主键ID获取整行记录的具体值。
在这个案例里,B的FSN是唯一值,A的FDEVICE在B表里,要么不存在,要么只有一条记录与之匹配,不会有第三种情况发生。
在未做自定义hash索引之前的SQL,应该就是这个执行过程才对,hash一次后,再在hash 字段做个索引,其实只是换了个实现途径,并没有解释为什么之前的方法为什么会全表扫描,潜伏在表象下的真相并不如此。
回到事件的原点,为什么最开始的那个SQL的执行计划里,ROWS等于全表,而走自定义hash索引后的rows=1?通过对索引原理的分析,它只要是用了索引,rows必然是1,如果没有用到索引,那么key这一列又必然是NULL,正是这个矛盾,从一开始就把我引向歧途,误认为是索引本身的问题,然后想当然的弄了个hash索引,然后误打误撞把问题解决。
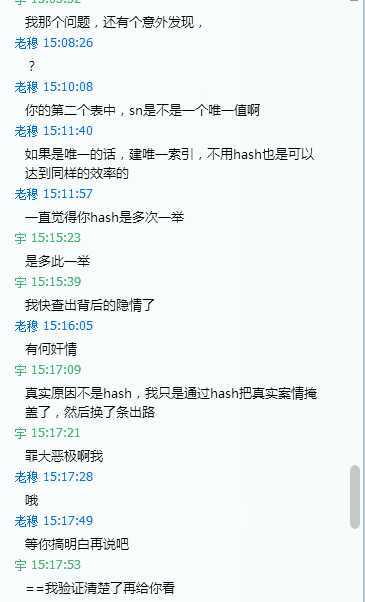
意外发现
首先要把一切不可能的事实都排除,那其余的,不管多么离奇,多么难以置信,也必然是无可辩驳的事实 夏洛克.福尔摩斯
在这个案例里,不可能的事实就是,嵌套循环的执行过程不会变,索引查找数据的过程不会变。那么还剩下什么?
1) 看到的ROWS=490W是假象 2)看到的key=sn是假象
从执行效率来看,ROWS=490W是真的,要么不会这么慢,那么KEY=SN是假的就有可能,看起来用到了索引,事实上索引完全没有起作用。
再次把视线集中到两个关联查询的表结构上,发现一个很不起眼的异常现象:`sn` varchar(20) CHARACTER SET utf8 。这个字段的字符集是utf8的,而与之关联的字段的字符集是utf8mb4的,两个不同的字段比较,是不是会引起索引失效?
很快实验结果就出来了,而这次,才是事件背后的真相。
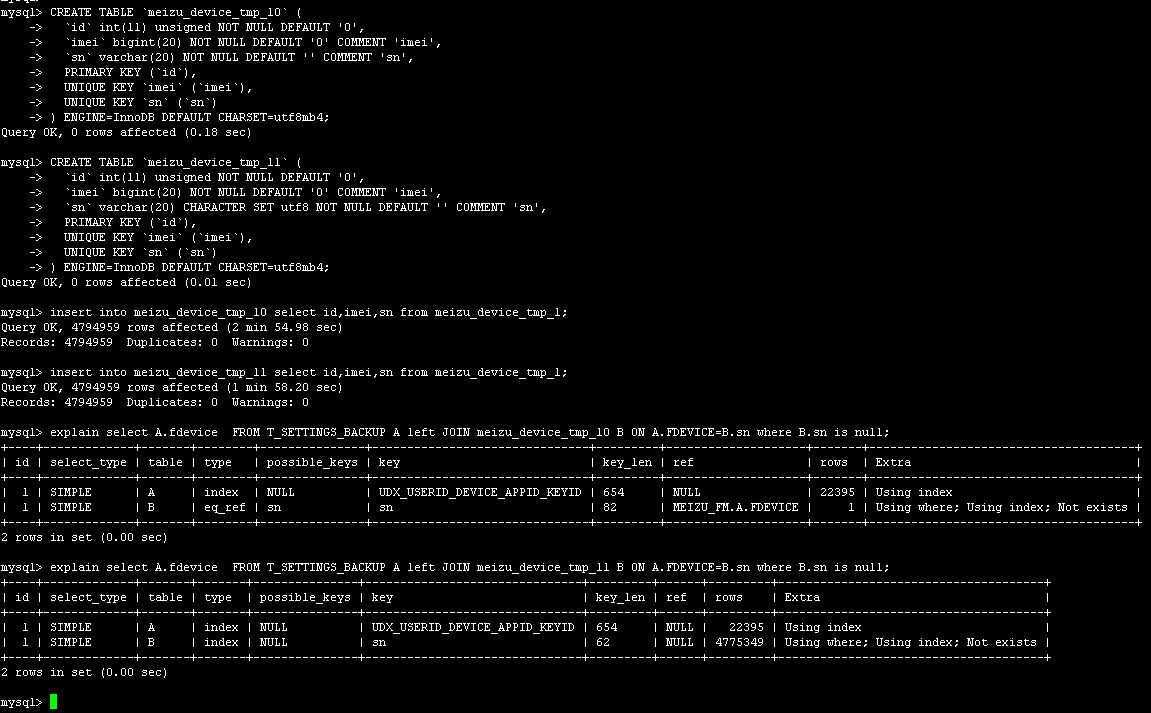
当两个关联字段的字符集相同时,索引运行如预期。
当我只有一个锤子时,很自然的把任何问题都看成钉子,先入为主的思维使一些简单而重要的细节被忽略,而这些线索能指引我们找出事情的真相。走完一圈弯路蓦然回首,其实那个苦苦寻觅的完美世界就在眼前,只是我们被偏见和愚昧蒙蔽了双眼。
Mysql 自定义HASH索引带来的巨大性能提升----[真相篇],布布扣,bubuko.com
Mysql 自定义HASH索引带来的巨大性能提升----[真相篇]
标签:blog http com strong 数据 2014
原文地址:http://www.cnblogs.com/zuoxingyu/p/3790510.html