标签:
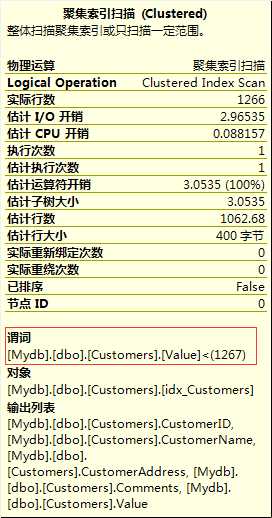
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据。我们来看看下面的表和索引定义:
1 CREATE TABLE Customers 2 ( 3 CustomerID INT NOT NULL, 4 CustomerName CHAR(100) NOT NULL, 5 CustomerAddress CHAR(100) NOT NULL, 6 Comments CHAR(185) NOT NULL, 7 Value INT NOT NULL 8 ) 9 GO 10 11 CREATE UNIQUE CLUSTERED INDEX idx_Customers ON Customers(CustomerID) 12 GO 13 14 CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value) 15 GO
我们往表里插入80000条记录:
1 DECLARE @i INT = 1 2 WHILE (@i <= 80000) 3 BEGIN 4 INSERT INTO Customers VALUES 5 ( 6 @i, 7 ‘CustomerName‘ + CAST(@i AS CHAR), 8 ‘CustomerAddress‘ + CAST(@i AS CHAR), 9 ‘Comments‘ + CAST(@i AS CHAR), 10 @i 11 ) 12 13 SET @i += 1 14 END 15 GO
执行下列查询,就会发现SQL Server完全忽略非聚集索引,而使用表扫描来获取数据,点击工具栏的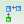 显示包含实际的执行计划:
显示包含实际的执行计划:
1 SELECT * FROM Customers 2 WHERE Value < 1267 3 GO
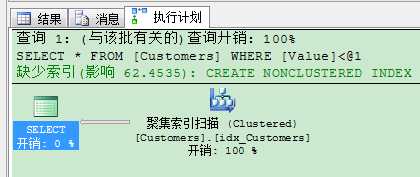
而当我们把查询条件修改为1266时,我们惊奇的发现,SQL Server又重新使用非聚集索引来获取数据了:
1 SELECT * FROM Customers 2 WHERE Value < 1266 3 GO
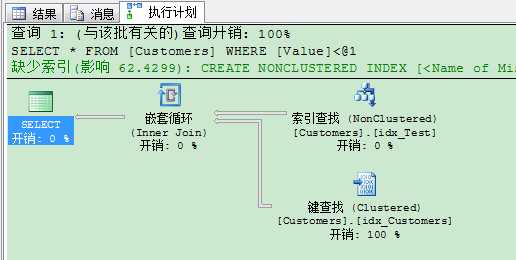
很多人估计会很兴奋,因为他们认为它们找到了SQL Server里的一个BUG,用指定索引来查询就可以避免这个问题:
1 SELECT * FROM Customers 2 WITH (INDEX(idx_Test)) 3 WHERE Value < 1267 4 GO
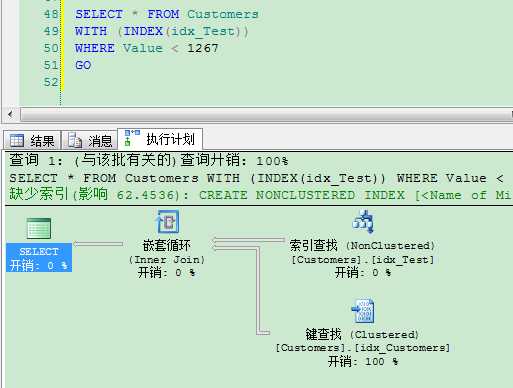
从执行计划里我们可以看到,SQL Server需要进行书签查找,因为针对这个查询,我们并没有定义对应的覆盖非聚集索引。当你进行全表聚集索引扫描时,SQL Server这里帮了你一个大忙:用书签查找获取每条记录成本太高,因此SQL Server使用了全表扫描,这样就只需要较少的IO和CPU占用,因为书签查找都要通过内循环运算符完成。
在SQL Server里,这个行为被称为临界点(Tipping Point) 。我们再详细解释下这个概念。简单来说,临界点定义了SQL Server是使用书签查找还是全表/索引扫描。这也意味着临界点只与非覆盖非聚集索引有关。一个对指定查询扮演覆盖非聚集索引的角色的话,不会有临界点,也就不会有刚才介绍的问题。
在有书签查找的查询时,SQL Server使用书签查找还是全表扫描取决于获取的页数。是的,你没看错!获取的页数决定了书签查找是好的还是不好的!这与查询返回的记录条数完全无关,唯一有关就是页数。临界点出现在查询需要读取的24%-33%页数之间。
在这范围之前,查询优化器会选择书签查找,在这范围之后,查询优化器会选择全表扫描(在全表扫描运算符里会有谓语定义)。
这也意味着你记录的大小决定了临界点的位置。在查询越过临界点进行全表扫描时,小记录,你就只能从表获取小数量的记录,大记录,你就能够获得大量的记录。下图就是对临界点的一个图示。

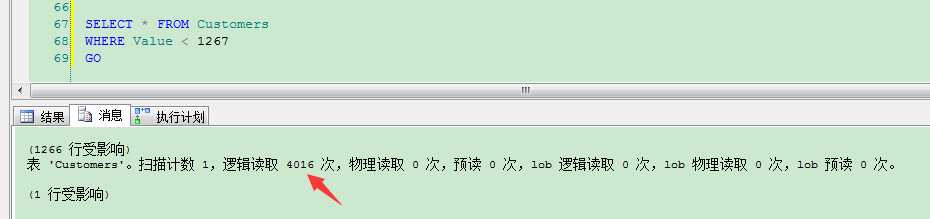
在我们刚才的例子里,每条记录是400 bytes长,因此8kb的页面里可以保存20条记录,当我们进行全表扫描时,SQL Server会产生4016个逻辑读。
1 SET STATISTICS IO ON 2 SELECT * FROM Customers

刚才的例子里,我们的表在聚集索引的叶子层有4000个数据页,也就是说临界点在1000与1333页之间的某个地方。在优化器选择进行全表扫描前,你只能读取1.25%-1.67%(1000/80000,1333/80000)的表数据。
下面这个查询会用到书签查找:
1 SET STATISTICS IO ON 2 SELECT * FROM Customers 3 WHERE Value < 1266 4 GO

可以看到,这个查询需要3887个IO操作,而全表扫描只需要4016个IO,这里的书签查找成本(IO和CPU消耗)越来越昂贵了。超过了这个点,SQL Server就决定不使用书签查找,改用全表扫描了。
1 SET STATISTICS IO ON 2 SELECT * FROM Customers 3 WHERE Value < 1267 4 GO
我们一起执行看下:
1 SELECT * FROM Customers 2 WHERE Value < 1266 3 GO 4 SELECT * FROM Customers 5 WHERE Value < 1267 6 GO
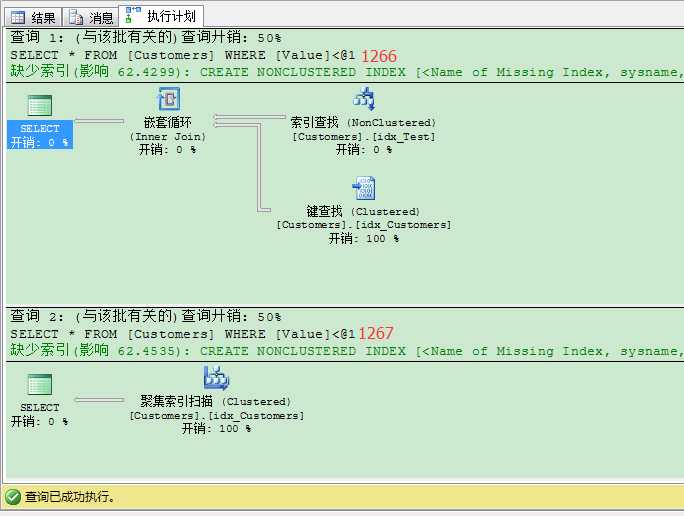
2个近乎一样的查询,却有完全不同的执行计划,这在性能调优的时候是个大问题,因为你的执行计划失去了稳定性。
针对输入参数的不同,却有完全不同的计划!这也是书签查找的重大缺陷!用了书签查找,你就不能获得稳定的执行计划。如果这个执行计划被缓存(或你的统计信息过期了),你用它获取大量数据的时候就会有性能上的问题,因为低效的书签查找被SQL Server盲目重用了!这会造成原先只要几秒的查询,要花好几分钟才能完成!
我们说过,临界点取决于查询的读取页数。我们对刚才的表做下一点改动,每条记录40 bytes长,8k的页里能存储200条的记录,同样我们也插入80000条记录(记得关掉IO统计:SET STATISTICS IO OFF和执行计划显示,否则电脑蜗牛了-_-)。
1 CREATE TABLE Customers3 2 ( 3 CustomerID INT NOT NULL, 4 CustomerName CHAR(10) NOT NULL, 5 CustomerAddress CHAR(10) NOT NULL, 6 Comments CHAR(5) NOT NULL, 7 Value INT NOT NULL 8 ) 9 GO 10 11 CREATE UNIQUE CLUSTERED INDEX idx_Customers ON Customers3(CustomerID) 12 GO 13 14 CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers3(Value) 15 GO 16 17 18 DECLARE @i INT = 1 19 WHILE (@i <= 80000) 20 BEGIN 21 INSERT INTO Customers3 VALUES 22 ( 23 @i, 24 ‘C2‘, 25 ‘C3‘, 26 ‘C4‘, 27 @i 28 ) 29 30 SET @i += 1 31 END 32 GO
这样的话,我们需要400页来存储这些数据。我们来看下临界点位置:临界点在100-133页读取的位置,也就是说通过非聚集索引,你只能读取0.125%-0.167%的数据,对于80000条数据的表来说,这几乎就是没数据!你的非聚集索引毫无用处!
我们来看下临界点的2个不同查询,这里我们可以打开执行计划显示。
1 SET STATISTICS IO ON 2 -- 书签查找会产生332个逻辑读。 3 SELECT * FROM Customers3 4 WHERE Value < 157 5 GO 6 7 -- 聚集索引扫描会产生419个逻辑读。 8 -- The query produces 419 I/Os. 9 SELECT * FROM Customers3 10 WHERE Value < 158 11 GO
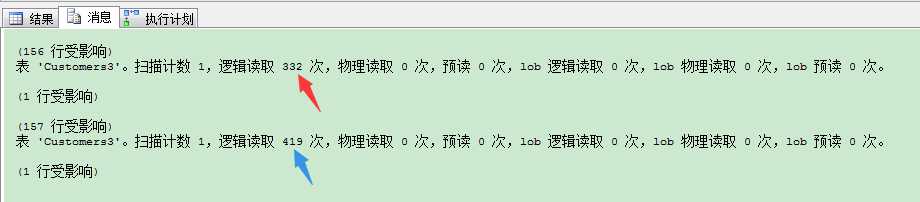
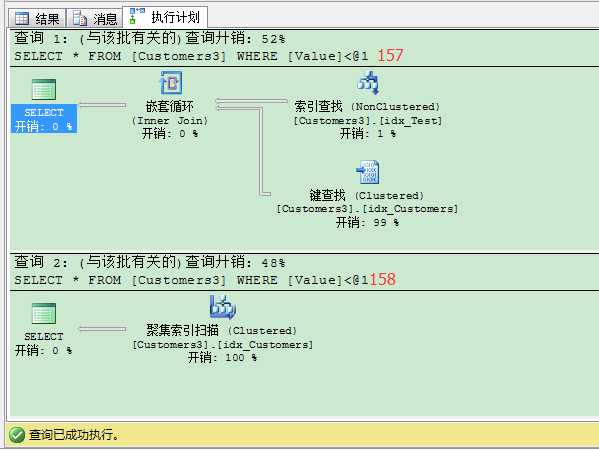
我们来看第2个查询,我们只选择80000条记录的157条,我们只选择了很少的数据,但是SQL Server在这里就非常聪明,完全忽略你的的非聚集索引,使用表扫描来获取数据。但对于整个查询来说,这个非聚集索引设计并不完美,因为不是覆盖的非聚集索引,如果有人用指定索引来查找数据,就会非常恐怖:
1 SELECT * FROM Customers3 WITH(INDEX(idx_Test)) 2 WHERE Value < 80001 3 GO

这个查询产生了165120个逻辑读,把聚集索引全表扫描需要的IO数直接秒杀!从这个例子我们可以看出,临界点是SQL Server里的性能保障,它阻止着使用书签查找,造成占用昂贵资源的查询发生。但这些和记录数完全无关。这2个例子里的表记录数都是80000。我们只修改了表记录的大小,因此我们就改变了表的大小,最后临界点也跟着改变,SQL Server就会忽略我们的非聚集索引。
寓意:非聚集索引,不是覆盖非聚集索引的话,在SQL Server里是非常,非常,非常,非常有选择性的用例!下次当你碰到这个情况的时候,想下你要怎么处理这个问题!
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4546520.html