标签:des class blog code http tar
补充:常规服务器动态管理对象包括,下面有些资料可能会应用到
dm_db_*:数据库和数据库对象
dm_exec_*:执行用户代码和关联的连接
dm_os_*:内存、锁定和时间安排
dm_tran_*:事务和隔离
dm_io_*:网络和磁盘的输入/输出
优化性能的常用方法是检索速度最慢的查询构成您 SQL Server 实例上的正常、 每日工作负载的一部分,然后调整它们,一个接一个的"Top 10"列表。 跟踪会话、 请求
和 SQL Server 基础架构中的最耗费大量资源,查询和执行时间最长。
稍微科学的方法可能会开始在较低级别,寻找特定区域,其中 SQL Server 遇到资源压力。 检查以确定其中等待进程完成后再进行一些其他操作异常长时间。 这种方式
,可以计算出是否缓慢的执行时间的主要组件是 CPU 时间 (如果系统是 cpu) 或时间所用等待 I/O (如果系统是 O 绑定) 等我们从自顶向下的方法去开始美妙的优
化过程
1) 分析实例级的等待(从最近一次SQL服务启动开始计数)
a.在实例中找到哪些等待类型占用了大部分时间
select * from sys.dm_os_wait_stats order by wait_type
b.分离出重量级等待即占总耗时80%或90%的等待类型
;with wait as
(
select
wait_type,
wait_time_ms /1000 as wait_time_ms,
100*wait_time_ms/SUM(wait_time_ms) over() as pct,
ROW_NUMBER() over(order by wait_time_ms desc) as rn
from sys.dm_os_wait_stats
where wait_type not like ‘%SLEEP%‘
)
select
a.wait_type as 等待类型,
round(a.wait_time_ms,2) as 等待时间秒,
ROUND(a.pct,2) as 占百分比,
ROUND(SUM(b.pct),2) as 百分比
from wait as a
join wait as b
on b.rn<=a.rn
group by a.rn,a.wait_type,a.wait_time_ms ,a.pct
having SUM(b.pct )-a.pct<90
order by a.rn
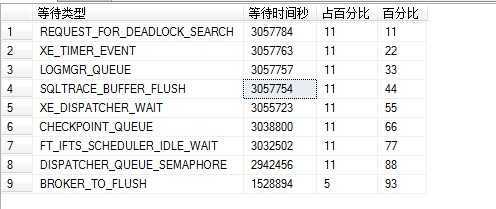
附图(服务器96上的主要等待类型统计)
c.找到对应问题的领域开始执行下一步优化(等待类型是哪个资源引起的可以参考联机丛书,里面有每个类型的详细解释ms-help://MS.SQLCC.v10/MS.SQLSVR.v10.zh-
CHS/s10de_6tsql/html/568d89ed-2c96-4795-8a0c-2f3e375081da.htm)
下面对附图我们前几个等待做一个详细的分析
REQUEST_FOR_DEADLOCK_SEARCH 联机丛书的解释是(在死锁监视器等待开始下一次死锁搜索时出现。在两次死锁检测之间可能出现该等待,长时间等待此资源并不指示出
现问题)这个系统os调度的原因我们忽略
XE_TIMER_EVENT(SQL自身的原因,这就不多解释了,具体解释可以查联机丛书)
SQLTRACE_BUFFER_FLUSH(当某任务正在等待后台任务将跟踪缓冲区每隔四秒刷新到磁盘时出现)这应该是SQL缓存中Checkpoint定时写入磁盘引起的,也是SQL自身忽略
LOGMGR_QUEUE(在日志编写器任务等待工作请求时出现)这是日志编写空间空闲等待记录日志造成,忽略
……庆幸的是,下面几个主要也是OS内部调度造成的,OK这系统实例级的等待中不存在大问题
OK,以上示例是本人针对公司一台主要服务器做的统计,没大问题不代表其它服务器不出现瓶颈问题,那实例及的等待中主要是由有哪些类型造成瓶颈呢?这边列出了几个
最可能会出现瓶颈的等待,并提出对产出该瓶颈时的优化方案,篇幅会很长
对优化分析获取 SQL Server 平稳运行时性能计数器和主要 DMV 查询输出的基线非常重要。这里我先要引出利用DMV查询来做数据透视表的方法,常见的性能计数器基线
做法我会另写一篇博文
a.创建表waitstas 用于记录各时段等待信息
use ZhouWei
select getdate() as DT,wait_type,waiting_tasks_count,wait_time_ms,max_wait_time_ms,signal_wait_time_ms
into waitstas from sys.dm_os_wait_stats where 1=2
alter table waitstas add constraint pk_waitstas primary key(dt,wait_type)
create index dt_index on waitstas(wait_type,dt)
b.建立作业收集wait消息(可以每小时执行一次)
Insert into monitor.dbo.WaitStats
(wait_type, waiting_tasks_count, wait_time_ms,
max_wait_time_ms, signal_wait_time_ms)
select wait_type, waiting_tasks_count, wait_time_ms,
max_wait_time_ms, signal_wait_time_ms
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN (N‘MISCELLANEOUS‘)
c.建立函数收集每次执行作业间隔中的wait消息
CREATE FUNCTION [dbo].[IntervalWaits]
(@fromdt AS DATETIME, @todt AS DATETIME)
RETURNS TABLE
AS
RETURN
WITH Waits AS
(
SELECT dt, wait_type, wait_time_ms,
ROW_NUMBER() OVER(PARTITION BY wait_type
ORDER BY dt) AS rn
FROM dbo.WaitStats
)
SELECT Prv.wait_type, Prv.dt AS start_time,
CAST((Cur.wait_time_ms - Prv.wait_time_ms)
/ 1000. AS NUMERIC(12, 2)) AS interval_wait_s
FROM Waits AS Cur
JOIN Waits AS Prv
ON Cur.wait_type = Prv.wait_type
AND Cur.rn = Prv.rn + 1
AND Prv.dt >= @fromdt
AND Prv.dt < DATEADD(day, 1, @todt)
d.创建视图用于透视表的数据源
CREATE VIEW [dbo].[IntervalWaitsSample]
AS
SELECT wait_type, start_time, interval_wait_s
FROM dbo.IntervalWaits(‘20111201‘, ‘20111202‘) AS F
where wait_type=‘????‘ --根据前面的实例分析中得到的,选择你要分析的wait_type类型
;
GO
e.通过EXCEL 透视表对上一步骤进行分析
附图
一. IO类型的等待是最常出现的
1.我们先对IO信息做个统计具体可以参考以下语句
select wait_type, waiting_tasks_count, wait_time_ms, signal_wait_time_ms, wait_time_ms / waiting_tasks_count as avg_waittime from
sys.dm_os_wait_stats where wait_type like ‘PAGEIOLATCH%‘ and waiting_tasks_count > 0 order by wait_type
附图2 注IO类型有些等待是破环类型长时间等待会造成磁盘损坏引起重视
2.下面我们细化到数据库(通过此查询可以分析出具体哪个数据库占用了大量的IO资源)用动态管理函数DMV来返回相关的信息
;with dbio AS
(
select DB_NAME(ivfs.database_id) as db,
case when mf.type=1 then ‘log‘ else ‘database‘ end as file_type,
SUM(ivfs.num_of_bytes_read+ivfs.num_of_bytes_written) as io,
SUM(ivfs.io_stall) as io_stall
from sys.dm_io_virtual_file_stats(null,null) as ivfs
join sys.master_files as mf on ivfs.database_id =mf.database_id and ivfs.file_id=mf.file_id
group by DB_NAME(ivfs.database_id),mf.type
)select db AS 数据库名,file_type as 文件类型,
cast(1.* io/(1024*1024) AS decimal(12,2)) AS IO流量,
CAST(io_stall/1000. as decimal(12,2)) as IO等待时间,
cast(100.*io_stall/sum(io_stall)over() as decimal(12,2)) as 占百分比,
row_number() over(order by io_stall desc) as rn
from dbio
order by io_stall desc;
附图3
分析出是否是数据库数据事物日志还是数据库数据区,如果是日志考虑是否配置合理,是否放到独立磁盘,是否磁盘驱动器够快等信息等。分析数据有两种方法:第一是要
建立跟踪具体是在Profiler中生成跟踪代码,然后自己新建脚本执行,原因是在优化器中执行其实是做了两步操作,还有怎么从分析资料中获取有效信息我后面再做整理,
第二我们建立以下代码可用于查找哪些批处理/请求生成的 I/O 最多。如下所示的 DMV 查询可用于查找可生成最多 I/O 的前15个请求。调整这些查询将提高系统性能。
select top 15(total_logical_reads/execution_count) as avg_logical_reads,
(total_logical_writes/execution_count) as avg_logical_writes,(total_physical_reads/execution_count) as avg_phys_reads,
Execution_count,statement_start_offset as stmt_start_offset,
plan_handle,
query_stats.statement_text AS "Statement Text"
from (SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE QS.statement_end_offset END - QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) as ST) as query_stats order by (total_logical_reads +total_logical_writes) Desc
二. CPU 瓶颈通常由以下原因引起:查询计划并非最优、配置不当、设计因素不良或硬件资源不足。下面的常用查询可帮助您确定导致 CPU 瓶颈的原因。
1.下面的查询代码是当前缓存中的哪些批处理或过程占用了大部分CPU资源。
SELECT TOP 50 SUM(qs.total_worker_time) AS total_cpu_time,SUM(qs.execution_count) AS total_execution_count,COUNT(*) AS number_of_statements,
(SELECT text FROM sys.dm_exec_sql_text(qs.sql_handle)) as sql_text
FROM sys.dm_exec_query_stats AS qs GROUP BY qs.sql_handle ORDER BY SUM(qs.total_worker_time) DESC
2. 下面的查询显示 CPU 平均占用率最高的前 10 个 SQL 语句。
SELECT TOP 10 total_worker_time/execution_count AS [Avg CPU Time],
SUBSTRING(st.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
ORDER BY total_worker_time/execution_count DESC;
3. 下面的查询显示哪个查询占用了最多的 CPU 累计使用率。
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
from
(select top 50
qs.plan_handle,
qs.total_worker_time
from
sys.dm_exec_query_stats qs
order by qs.total_worker_time desc) as highest_cpu_queries
cross apply sys.dm_exec_sql_text(plan_handle) as q
order by highest_cpu_queries.total_worker_time desc
三.阻塞
运行下面的查询可确定阻塞的会话。
select blocking_session_id, wait_duration_ms, session_id from
sys.dm_os_waiting_tasks
where blocking_session_id is not null
使用此调用可找出 blocking_session_id 所返回的 SQL。例如,如果 blocking_session_id 是 87,则运行此查询可获得相应的 SQL。
dbcc INPUTBUFFER(87)
若要找出哪个 spid 正在阻塞另一个 spid,可在数据库中创建以下存储过程,然后执行该存储过程。此存储过程会报告此阻塞情况。键入 sp_who 可找出 @spid;@spid
是可选参数。
create proc dbo.sp_block (@spid bigint=NULL) as select t1.resource_type, ‘database‘=db_name(resource_database_id), ‘blk object‘ =
t1.resource_associated_entity_id, t1.request_mode, t1.request_session_id, t2.blocking_session_id from sys.dm_tran_locks as t1,
sys.dm_os_waiting_tasks as t2 where t1.lock_owner_address = t2.resource_address and t1.request_session_id = isnull
(@spid,t1.request_session_id)
以下是使用此存储过程的示例。
exec sp_block exec sp_block @spid = 7
.gif)
 Figure 2 需要注意的性能计数器
Figure 2 需要注意的性能计数器| 性能计数器 | 计数器对象 | 阈值 | 注释 |
| % Processor Time | 处理器 | > 80% | 潜在因素包括内存不足、低查询计划重用率和未经优化的查询。 |
| Context Switches/sec | 系统 | > 5000 x 处理器数 | 潜在因素包括服务器上的其他应用程序、在同一服务器上运行了多个 SQL Server 实例和超线程已打开。 |
| Processor Queue Length | 系统 | > 5 x 处理器数 | 潜在因素包括服务器上的其他应用程序、频繁的编译或重新编译以及在同一服务器上运行了多个 SQL Server 实例。 |
| Compilations/sec | SQLServer:SQL Statistics | 趋势 | 与 Batch Requests/sec 进行比较。 |
| Re-Compilations/sec | SQLServer:SQL Statistics | 趋势 | 与 Batch Requests/sec 进行比较。 |
| Batch Request/sec | SQLServer:SQL Statistics | 趋势 | 与每秒编译和重新编译数进行比较。 |
| Page Life Expectancy | SQLServer:Buffer Manager | < 300 | 内存不足的潜在因素。 |
| Lazy Writes/sec | SQLServer:Buffer Manager | 趋势 | 大量数据缓存刷新或内存不足的潜在因素。 |
| Checkpoints/sec | SQLServer:Buffer Manager | 趋势 | 根据 PLE 和 Lazy Writes/sec 评估检查点。 |
| Cache Hit Ratio:SQL Plans | SQLServer:Plan Cache | < 70% | 表示计划重用率低。 |
| Buffer Cache Hit Ratio | SQLServer:Buffer Manager | < 97% | 内存不足的潜在因素。 |
USE SHIPPING_DIST01;
SELECT
Container_ID
,Carton_ID
,Product_ID
,ProductCount
,ModifiedDate
FROM Container.Carton
WHERE Carton_ID = 982350144;
Figure 3 确定服务器活动SELECT es.session_id
,es.program_name
,es.login_name
,es.nt_user_name
,es.login_time
,es.host_name
,es.cpu_time
,es.total_scheduled_time
,es.total_elapsed_time
,es.memory_usage
,es.logical_reads
,es.reads
,es.writes
,st.text
FROM sys.dm_exec_sessions es
LEFT JOIN sys.dm_exec_connections ec
ON es.session_id = ec.session_id
LEFT JOIN sys.dm_exec_requests er
ON es.session_id = er.session_id
OUTER APPLY sys.dm_exec_sql_text (er.sql_handle) st
WHERE es.session_id > 50 -- < 50 system sessions
ORDER BY es.cpu_time DESC
SELECT * INTO trc_20070401 FROM fn_trace_gettable(‘S:\Mountpoints\TRC_20070401_1.trc‘, default); GO
标签:des class blog code http tar
原文地址:http://www.cnblogs.com/cwfsoft/p/3792468.html