标签:
在这一期的性能调优培训里,我想详细谈下SQL Server里计划缓存及其副作用。在上一周你已经学到,每个提交给SQL Server的逻辑查询会编译成物理执行计划。那个执行计划然后会被缓存,即被称为计划缓存,用作后期的重用。首先我们来看下即席SQL语句(adhoc SQL statements,对应的反义词:prepared SQL statements)的副作用,即带来的性能问题。
每次当你提交一个即席SQL语句到SQL Server时,对每个唯一的查询,都会有执行计划被编译。“唯一的查询”是什么意思?答案很简单:SQL Server对完整的SQL语句(包括可能硬编码的参数值)生成一个hash值,并使用这个hash值作为在计划缓存里查找值。如果找到这个值的执行计划,这个计划就会被重用,否则的话新的计划会被编译并最后在计划缓存里缓存。看下我们提交下面这3个查询给SQL Server:

1 SELECT * FROM Sales.SalesOrderHeader
2
3 WHERE CustomerID = 11000
4
5 GO
6
7 SELECT * FROM Sales.SalesOrderHeader
8
9 WHERE CustomerID = 30052
10
11 GO
12
13 SELECT * FROM Sales.SalesOrderHeader
14
15 WHERE CustomerID = 11223
16
17 GO
对这3个查询,SQL Server会编译3个不同的执行计划,因为你提供硬编码的参数值。因此计算出来的hash值在3个查询之间是不同的,找不到被缓存的计划。作为一个副作用,对于几乎相同的查询,你有3个执行计划。这个问题被称为计划缓存污染(Plan Cache Pollution) 。
你用不同的执行计划污染了你的计划缓存,这些计划是不能被重用的(因为硬编码的参数值),并且你在浪费大量有用的内存,这些内存在SQL Server里可以被其他组件使用。缓存的目的应该是持续数次的高重用,特定SQL语句不属于这个情况。
如果你参数话你的SQL语句,或者使用存储过程。在那个情况下,SQL Server可以非常容易的重用执行计划。但是即使重用执行计划也会带来性能的问题。比如SQL Server为一个查询编译了一个需要执行书签查找的执行计划,因为用到的非聚集索引没有覆盖到查询字段。

在第8周我们说过,如果你从表获取少量数据,书签查找还是有用的。当你越过临界点时,使用全表/索引扫描将更高效。但是SQL Server如果重用缓存的执行计划,就不会考虑这个选择了——SQL Server只会盲目的重用你的计划——即使性能非常糟糕!我们看看下面的实际执行计划:
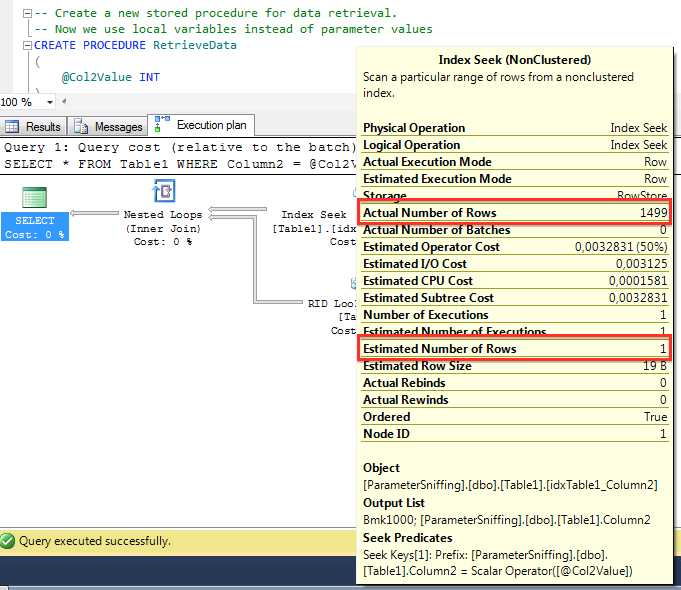
这里SQL Server盲目重用了包含书签查找的被缓存的计划。如你所见,估计行数(estimated number of rows )和实际行数(actual number of rows )完全不同。SQL Server基于假设那个查询只返回1条记录来编译和缓存了计划。但是实际上SQL Server返回了1499条记录。看看执行计划,我们会更清晰,优化器是假设只返回1条记录才执行这个操作的。
这会导致你没有计划稳定性。基于估计行数,你得到书签查找的缓存计划,要不就是如果越过临界点的话是全表/索引扫描。这个是我们在性能调优时经常碰到的性能问题。
标签:
原文地址:http://www.cnblogs.com/lykbk/p/ERY4564R5T345435.html