标签:style class blog http ext color
Linux内核源代码分析方法
一、内核源代码之我见
Linux内核代码的庞大令不少人“望而生畏”,也正由于如此,使得人们对Linux的了解仅处于泛泛的层次。假设想透析Linux,深入操作系统的本质,阅读内核源代码是最有效的途径。我们都知道,想成为优秀的程序猿,须要大量的实践和代码的编写。编程固然重要,可是往往仅仅编程的人非常easy把自己局限在自己的知识领域内。假设要扩展自己知识的广度,我们须要多接触其它人编写的代码,尤其是水平比我们更高的人编写的代码。通过这样的途径,我们能够跳出自己知识圈的束缚,进入他人的知识圈,了解很多其它甚至我们一般短期内无法了解到的信息。Linux内核由无数开源社区的“大神们”精心维护,这些人都能够称得上一顶一的代码高手。透过阅读Linux内核代码的方式,我们学习到的不光是内核相关的知识,在我看来更具价值的是学习和体会它们的编程技巧以及对计算机的理解。
我也是通过一个项目接触了Linux内核源代码的分析,从源代码的分析工作中,我受益颇多。除了获取相关的内核知识外,也改变了我对内核代码的过往认知:
1.内核源代码的分析并不是“高不可攀”。内核源代码分析的难度不在于源代码本身,而在于怎样使用更合适的分析代码的方式和手段。内核的庞大致使我们不能依照分析一般的demo程序那样从主函数開始按部就班的分析,我们须要一种从中间介入的手段对内核源代码“各个击破”。这样的“按需索取”的方式使得我们能够把握源代码的主线,而非过度纠结于详细的细节。
2.内核的设计是优美的。内核的地位的特殊性决定着内核的运行效率必须足够高才干够响应眼下计算机应用的实时性要求,为此Linux内核使用C语言和汇编的混合编程。可是我们都知道软件运行效率和软件的可维护性非常多情况下是背道而驰的。怎样在保证内核高效的前提下提高内核的可维护性,这须要依赖于内核中那些“优美”的设计。
3.奇妙的编程技巧。在一般的应用软件设计领域,编码的地位可能不被过度的重视,由于开发人员更注重软件的良好设计,而编码仅仅是实现手段问题——就像拿斧子劈柴一样,不用太多的思考。可是这在内核中并不成立,好的编码设计带来的不光是可维护性的提高,甚至是代码性能的提升。
每一个人对内核的了理解都会有所不同,随着我们对内核理解的不断加深,对其设计和实现的思想会有很多其它的思考和体会。因此本文更期望于引导很多其它徘徊在Linux内核大门之外的人进入Linux的世界,去亲自体会内核的奇妙与伟大。而我也并不是内核源代码方面的专家,这么做也仅仅是希望分享我自己的分析源代码的经验和心得,为那些须要的人提供參考和帮助,说的“冠冕堂皇”一点,也算是为计算机这个行业,尤其是在操作系统内核方面贡献自己的一份绵薄之力。闲话少叙(已经罗嗦了非常多了,囧~),下面我就来分享一下自己的Linix内核源代码分析方法。
二、内核源代码难不难?
从本质上讲,分析Linux内核代码和看别人的代码没有什么两样,由于摆在你面前的一般都不是你自己写出来的代码。我们先举一个简单的样例,一个陌生人随便给你一个程序,并要你看完源代码后解说一下程序的功能的设计,我想非常多自我感觉编程能力还能够的人肯定认为这没什么,仅仅要我耐心的把他的代码从头到尾看完,肯定能找到答案,并且事实确实是如此。那么如今换一个假设,假设这个人是Linus,给你的就是Linux内核的一个模块的代码,你还会认为依旧那么轻松吗?不少人可能会有所犹豫。相同是陌生人(Linus要是认识你的话当然不算,呵呵~)给你的代码,为什么给我们的感觉大相径庭呢?我认为有下面原因:
1.Linux内核代码在“外界”看来多少有些神奇感,并且它非常庞大,猛地摆在面前可能感觉无法下手。比方可能来源于一个非常细小的原因——找不到main函数。对于简单的demo程序,我们能够从头至尾的分析代码的含义,可是分析内核代码这招就彻底失效了,由于没有人能把Linux代码从头到尾看上一遍(由于确实没有必要,用到时看就能够了)。
2.不少人也接触过大型软件的代码,但多数属于应用型项目,代码的形式和含义都和自己常接触的业务逻辑相关。而内核代码不同,它处理的信息多数和计算机底层密切相关。比方操作系统、编译器、汇编、体系结构等相关的知识的欠缺,也会让阅读内核代码障碍重重。
3.分析内核代码的方法不够合理。面对大量的并且复杂的内核代码,假设不从全局的角度入手,非常easy陷入代码细节的泥淖中。内核代码尽管庞大,可是它也有它的设计原则和架构,否则维护它对不论什么人来说都是一个噩梦!假设我们理清代码模块的总体设计思路,再去分析代码的实现,可能分析源代码就是一件轻松快乐的事情了。
针对这些问题,我个人是这样理解的。假设没有接触过大型软件项目,可能分析Linux内核代码是一个非常好的积累大型项目经验的机会(确实,Linux代码是我眼下接触到的最大的项目了!)。假设你对计算机底层了解的不够透彻,那么我们能够选择边分析边学习的方式去积累底层的知识。可能刚開始分析代码的进度会稍显迟缓,可是随着知识的不断积累,我们对Linux内核的“业务逻辑”会逐渐明朗起来。最后一点,怎样从全局的角度把握分析的源代码,这也是我想与大家分享的经验。
三、内核源代码分析方法
第一步:资料搜集
从人认识新事物的角度来讲,在探索事物本质之前,必须有一个了解新奇事物的过程,这个过程是的我们对新奇事物产生一个初步的概念。比方我们想学习钢琴,那么我们须要先了解弹奏钢琴须要我们学习主要的乐理、简谱、五线谱等基础知识,然后学习钢琴弹奏的技巧和指法,最后才干真正的開始练习钢琴。
分析内核代码也是如此,首先我们须要定位要分析的代码涉及的内容。是进程同步和调度的代码,是内存管理的代码,还是设备管理的代码,还是系统启动的代码等等。内核的庞大决定着我们不能一次性将内核代码全部分析完毕,因此我们须要给自己一个合理的分工。正如算法设计告诉我们的,要解决一个大问题,首先要解决它所涉及的子问题。
定位好要分析的代码范围,我们就能够动用手头的一切资源,尽可能的全面了解该部分代码的总体结构和大致功能。
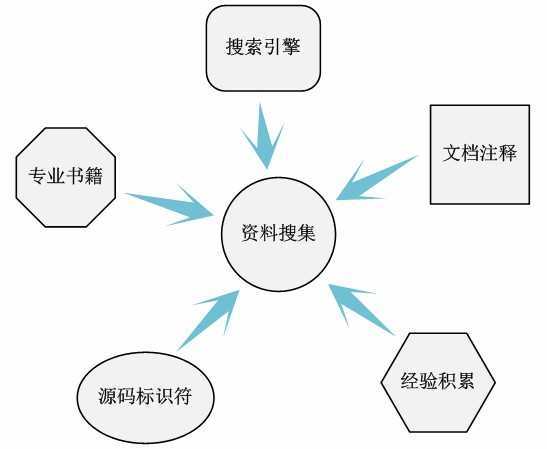
这里所说的一切资源是指不管是Baidu、Google大型网络搜索引擎,还是操作系统原理教材和专业书籍,亦或是他人提供的经验和资料,甚至是Linux源代码提供的文档、凝视和源代码标识符的名称(不要小看代码中的标识符的命名,有时它们能提供关键的信息)。总之这里的一切资源指的就是你能想到的一切可用资源。当然,我们不太可能通过这样的形式的信息搜集获得全部的我们想要的信息,我们仅仅求尽可能全面就可以。由于信息搜集的越全面,之后分析代码的过程能使用的信息就很多其它,分析过程的困难就会越小。
这里举一个简单的样例,假定我们要分析Linux的变频机制实现的代码。眼下为止我们仅仅是知道这个名词而已,透过字面含义我们能够大致推測它应该和CPU的频率调节相关。通过信息搜集,我们应该能得到例如以下的相关的信息:
1.CPUFreq机制。
2.performance、powersave、userspace、ondemand、conservative调频策略。
3./driver/cpufreq/。
4./documention/cpufreq。
5.P state和C state。
……
分析Linux内核代码假设能搜集到这些信息,应该说是非常“幸运”了。毕竟有关Linux内核的资料确实不如.NET和JQuery那么丰富,只是这相比于十数年前,没有强大的搜索引擎,没有相关的研究资料的时期应该称得上是“大丰收”时代了!我们通过简单的“搜索”(可能会花费一到两天的时间吧),甚至找到了这部分代码所在的源代码文件文件夹,不得不说这样的信息简直是“价值连城”!
第二步:源代码定位
从资料搜集中,我们“有幸”找到了源代码相关的源代码文件夹。可是这并不是意味着我们的确就是分析这个文件夹下的源代码。有时我们找到的文件夹有可能是分散的,也有时我们找到的文件夹下有非常多和详细机器相关的代码,而我们更关心的是待分析代码的主要机制,而非与机器相关的特化代码(这样更有助于我们理解内核的本质)。因此,我们须要对资料中涉及代码文件的资料进行细致甄选。当然,这一步也不太可能一次性完毕,谁也不能保证一次就能选择出全部待分析的源代码文件并且一个不漏。可是我们也不必操心,仅仅要我们能抓住大多数模块相关的核心源文件,通过后期对代码的详细分析,就非常自然的把它们全部找出来。
回到上述的样例中,我们认真的阅读/documention/cpufreq下的文档说明。眼下的Linux源代码会把模块相关的文档说明保存在源代码文件夹的documention的文件夹下,假设待分析的模块没有文档说明,这多少会添加定位关键源代码文件的难度,可是不会导致我们找不到我们要分析的源代码。通过阅读文档说明,我们至少能关注到/driver/cpufreq/cpufreq.c这个源文件。通过这个对源文件的文档说明,结合之前搜罗到的调频策略,我们非常easy关注到cpufreq_performance.c、cpufreq_powersave.c、cpufreq_userspace.c、cpufreq_ondemand、cpufreq_conservative.c这五个源文件。全部涉及的文件都找完了吗?不用操心,从它们開始分析,迟早能找到其它的源文件。假设在windows下使用sourceinsight阅读内核源代码的话,我们通过函数的调用和查找符号引用等功能,结合代码的分析能够非常方便的找到另外的文件freq_table.c、cpufreq_stats.c和/include/linux/cpufreq.h。
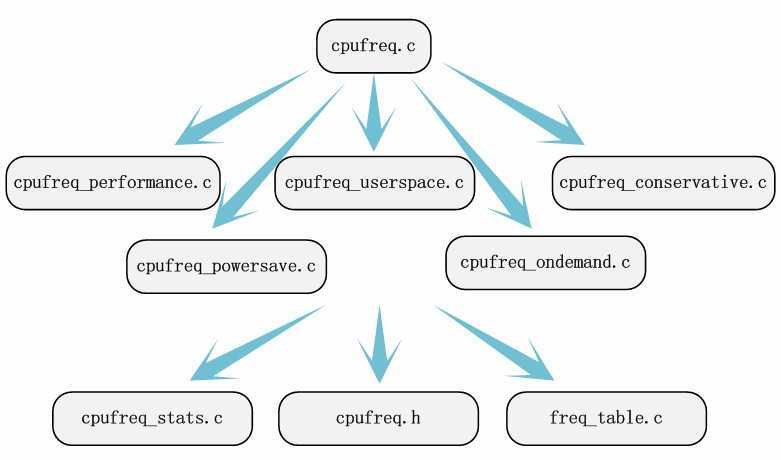
依照搜索出的信息流动方向,我们全然能够定位到须要分析的源代码文件。源代码定位这一步并不是十分关键,由于我们不须要找出全部源代码文件,我们能够把部分工作推迟到分析代码的过程中。源代码定位也比較关键,找到一部分源代码文件是分析源代码的基础。
第三步:简单凝视
在已定位好的源代码文件里,分析每一个变量、宏、函数、结构体等代码元素的大致含义和功能。之所以称此为简单凝视,并不是指这部分的凝视工作非常简单,而是指这部分的凝视能够不必过分细化,仅仅要大致描写叙述出相关代码元素的含义就可以。相反,这里的工作事实上是整个分析流程中最困难的一步。由于这是第一次深入到内核代码的内部,尤其是对于首次分析内核源代码的人来说,大量的生疏GNU的C语法和铺天盖地的宏定义会令人非常绝望。此时仅仅要沉下心来,弄清每一个关键的难点,才干保证以后碰到相似的难点不会再被困住。并且,我们对内核相关的其它知识会不断的像树一样扩展开来。
比方在cpufreq.c文件開始就会出现“DEFINE_PER_CPU”宏的使用,我们通过查阅资料能够基本弄清这个宏的含义和功能。这里使用的手段和之前搜集资料使用的方法基本一致,另外我们也能够使用sourceinsight提供的转到定义等功能查看它的定义,或者使用LKML(Linux Kernel Mail List)查阅,实在不行我们还能够到www.stackoverflow.com提问寻求解答(想了解什么是LKML和stackoverflow?搜集资料吧!)。总之利用全部可能的手段,我们总能得到这个宏的含义——为每一个CPU定义一个独立使用的变量。
我们也不要强求一次就能把凝视描写叙述的非常准确(我们甚至都不是必需弄清每一个函数的详细实现流程,仅仅要弄清大致功能含义就可以),我们结合搜集到的资料和后边代码的分析不断的完好凝视的含义(源代码中原有的凝视和标识符命名在此非常有利用价值)。通过不断的凝视,不断的查阅资料,不断的改动凝视的含义。
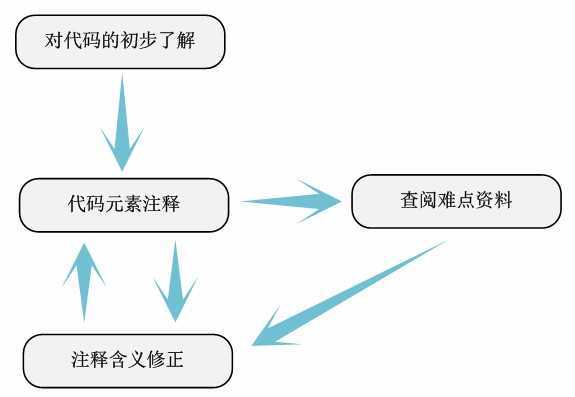
当我们把全部涉及的源代码文件简单凝视完毕后我们能够达到例如以下效果:
1.基本弄清了源代码中代码元素存在的含义。
2.找出了该模块所涉及的基本上全部的关键源代码文件。
结合之前搜集到的信息和资料对该待分析代码的总体或者架构描写叙述,我们能够将分析的结果和资料对照,以确定和修正我们对代码的理解。这样,通过一遍的简单凝视,我们就能够从总体上把握了源代码模块的主要结构。这也达到了我们简单凝视的基本目的。
第四步:详细凝视
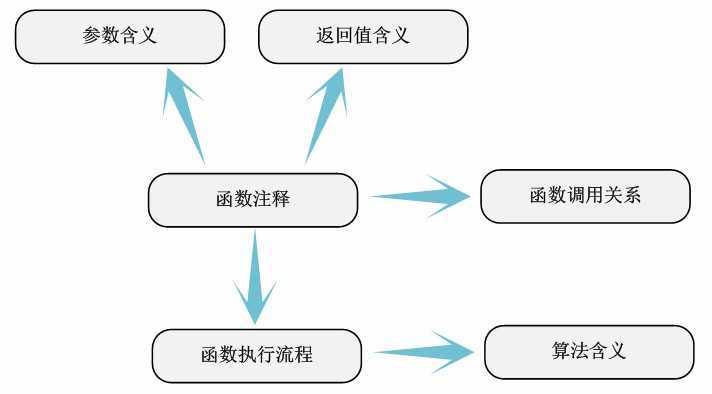
完毕代码的简单凝视后,能够认为对模块的分析工作完毕了一半了,剩下的内容就是对代码的深入分析和彻底理解。简单凝视总是不能将代码元素的详细含义描写叙述的十分精确,因此详细凝视是十分有必要的。这一步中,我们须要弄清下面内容:
1.变量定义在何时被使用。
2.宏定义的代码何时被使用。
3.函数的參数和返回值的含义。
4.函数的运行流程和调用关系。
5.结构体字段的详细含义和使用条件。
我们甚至能够把这一步称为函数详细凝视,由于函数之外的代码元素的含义基本上在简单凝视中已经比較明白了。而函数本身的运行流程、算法等是这部分凝视和分析的主要任务。
比方cpufreq_ondemand策略的实现算法(函数dbs_check_cpu中)是怎样实现的。我们须要逐步分析该函数使用的变量和调用的函数等信息,弄清算法的来龙去脉。最好的结果,我们须要这些复杂函数的运行流程图和函数调用关系图,这是最直观的表达方式。
通过这一步的凝视,我们基本上能全然把握待分析代码总体的实现机制了。而全部的分析工作能够认为完毕了80%。这一步工作尤其关键,我们必须尽量让凝视的信息足够的准确,才干更好的理解待分析代码的内部模块的划分。尽管Linux内核中使用了宏语法“module_init”和“module_exit”声明模块文件,可是对模块内部子功能的划分是建立在充分了解模块的功能基础上的。仅仅有正确划分好模块,我们才干弄清模块提供了哪些外部函数和变量(使用EXPORT_SYMBOL_GPL或者EXPORT_SYMBOL导出的符号)。才干继续下一步的模块内标识符依赖关系分析。
第五步:模块内部标识符依赖关系
通过第四步对代码模块的划分,我们就能够非常“轻松”地逐个对模块进行分析。一般的,我们能够从文件底部的模块出入口函数開始(“module_init”和“module_exit”声明的函数,一般都在文件最后),依据它们调用的函数(自定义的或者其它模块的函数)和使用的关键变量(本文件内的全局变量或者其它模块的外部变量)画出“函数-变量-函数”依赖关系图——我们称为标识符依赖关系图。
当然,模块内标识符依赖关系并不是是单纯的树形结构,非常多情况是错综复杂的网络关系。这时候,我们对代码的详细凝视的作用就体现出来了。我们依据函数本身的含义,将模块进行子功能划分,抽取出每一个子功能的标识符依赖树。
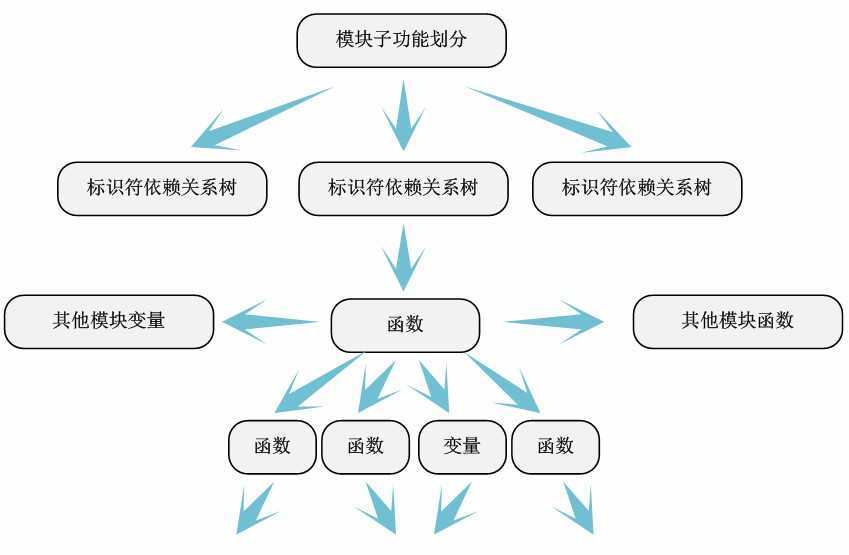
通过标识符依赖关系分析,能够非常清楚的展示模块定义的函数调用了那些函数,使用了哪些变量,以及模块子功能之间的依赖关系——公用了哪些函数和变量等。
第六步:模块间相互依赖关系
一旦将全部的模块内部标识符依赖关系图整理完毕,依据模块使用的其它模块的变量或函数,能够非常easy得到模块之间的依赖关系。
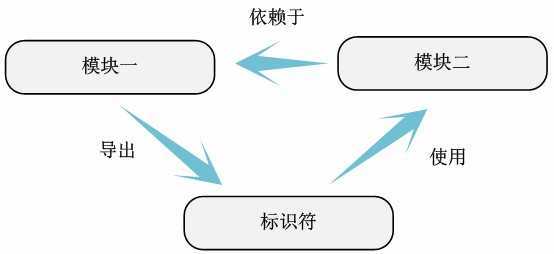
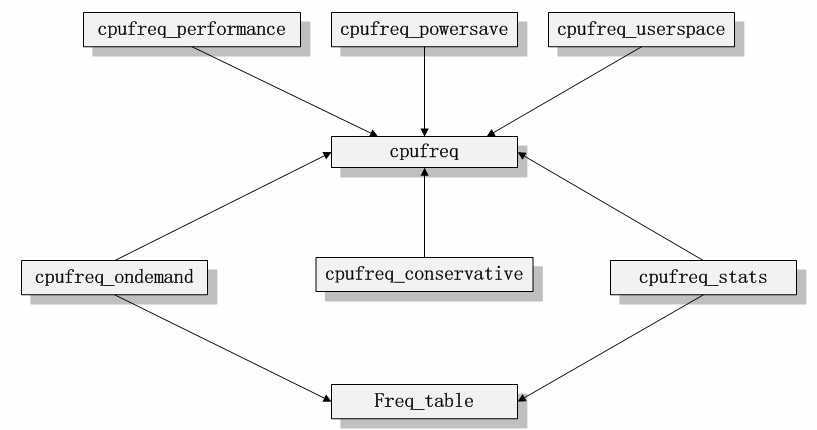
cpufreq代码的模块依赖关系能够表示为例如以下关系。
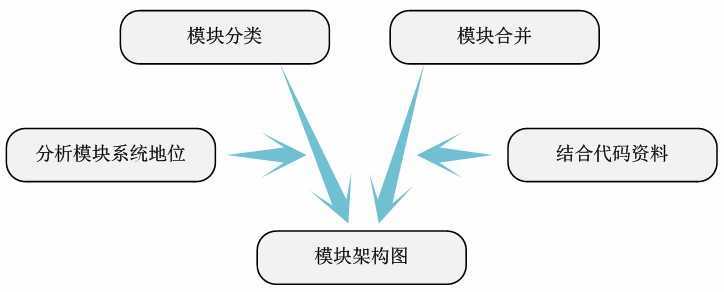
第七步:模块架构图
透过模块间的依赖关系图,能够非常清楚的表达模块在整个待分析代码中的地位和功能。基于此,我们能够将模块分类,整理出代码的架构关系。
如cpufreq的模块依赖关系图所看到的,我们能够非常清楚的看到全部的调频策略模块都是依赖于核心模块cpufreq、cpufreq_stats和freq_table的。假设我们把被依赖的三个模块抽象为代码的核心框架的话,这些调频策略模块都是建立在这个框架之上的,它们负责和用户层交互。而核心模块cpufreq提供了驱动等相关的接口负责与系统底层交互。因此,我们能够得到例如以下的模块架构图。
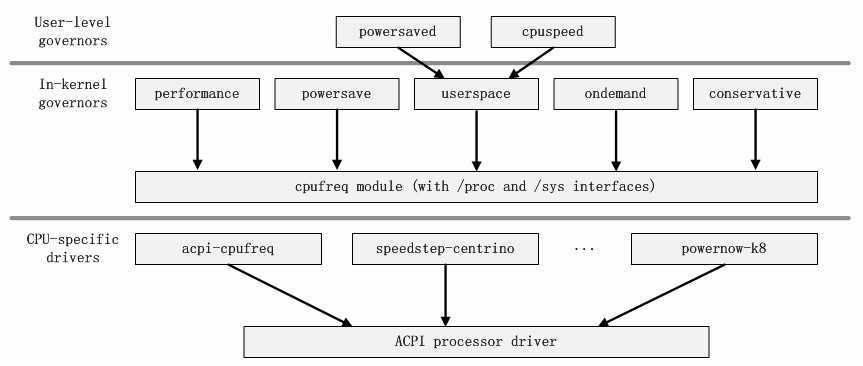
当然,架构图并不是模块的无机拼接,我们还须要结合查阅的资料去丰富架构图的含义。因此,这里的架构图的细节会随着不同的人的理解有所偏差。可是架构图主体的含义非常基本一致的。至此,我们完毕了待分析的内核代码的全部分析工作。
四、总结
正如文章開始所说,我们不可能对全部的内核代码进行分析。因此,通过对待分析的代码进行信息搜集,然后依照上述的流程分析出代码的原本始末是了解内核本质的有效手段。这样的依照详细须要分析内核代码的方式,为高速进入Linux内核的世界提供了可能。通过这样的方式,不断的对内核的其它模块分析,最后综合得到自己对Linux内核的理解,也就达到了我们学习Linux内核的目的。
最后向大家推荐两本学习内核的參考书。一本是《Linux内核的设计与实现》,该书为读者高速精简的介绍了Linux内核的主要功能和实现。但不会把读者带入Linux内核代码的深渊中,是了解内核架构和入门Linux内核代码的非常好的參考书,同一时候该书会提高读者对内核代码的兴趣。还有一本是《深入理解Linux内核》,该书的经典我不必多说。我仅仅是建议,假设想更好的学习本书,最好是结合着内核代码一起阅读。由于这本书对内核代码描写叙述的十分详细,所以结合代码进行阅读能够帮助我们更好的理解内核代码。同一时候,在分析内核代码的过程中,也能够在本书中找到具有參考价值的资料。最后,愿大家早日进入内核的世界,体验Linux带给我们的惊喜!
标签:style class blog http ext color
原文地址:http://www.cnblogs.com/gcczhongduan/p/3808436.html