标签:style class blog code http tar
作者:郝喜路 个人主页: http://www.cnicode.com 博客地址:http://haoxilu.cnblogs.com 时间:2014年6月26日 19:25:02
刚刚在博客园 看到一篇博文《使用HttpWebRequest和HtmlAgilityPack抓取网页(拒绝乱码,拒绝正则表达式)》 ,感觉不错,作者写的也挺好的,然后在看了园子里的朋友的评论后,我知道了有一个更牛x的工具——Jumony 。这个工具用起来可谓称之为简单、高效。 特此记录和分享,Jumony 的使用方法。
Jumony是开源项目,目前源代码存放咋GitHub ,源码地址: https://github.com/Ivony/Jumony 。我测试使用的是Visual Studio 2012 ,测试网页为博客园。
下面介绍使用方法:
一、在新建项目后,需要将Jumony添加到项目中,你可以下载源码使用,也可以在NugGet 中 搜索 Jumony Core 将其添加到项目中并且后自动添加所需的引用。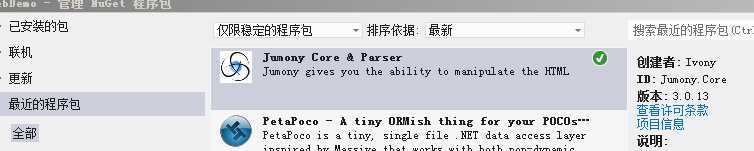
二、添加引用之后,即可写项目代码。(此处代码为获取 博客园首页文章内容)
1 public string Html = string.Empty;//为将拼接好html字符串返回给前台代码 2 protected void Page_Load(object sender, EventArgs e) 3 {
5 var htmlSource = new JumonyParser().LoadDocument("http://www.cnblogs.com").Find(".post_item a.titlelnk"); 6 int count = 0; 7 foreach (var htmlElement in htmlSource) 8 { 9 count ++; 10 Html += string.Format(" <li>{2}、 <a href=\"About.aspx?Url={0}\" target=\"_blank\">{1}</a></li>", htmlElement.Attribute("href").Value(), htmlElement.InnerText(),count); 11 } 12 }
效果图:
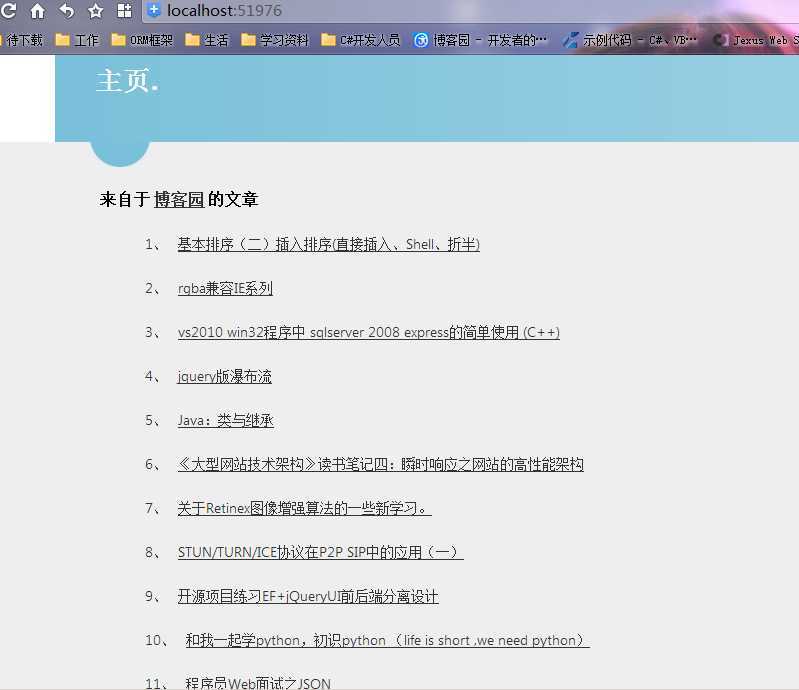
三、下面就是要在点击上图从博客园抓取的文章标题之后,在显示博客全文(并非在打开博客园的文章)
代码:
1 string html = Request["Url"]; 2 var htmlSource = 3 new JumonyParser().LoadDocument(html); 4 HtmlText = htmlSource.Find(".postTitle2").FirstOrDefault().InnerText(); 5 6 Html = htmlSource.Find("#cnblogs_post_body").FirstOrDefault().InnerHtml();
效果图:

Jumony快速抓取网页 --- Jumony使用笔记--icode,布布扣,bubuko.com
Jumony快速抓取网页 --- Jumony使用笔记--icode
标签:style class blog code http tar
原文地址:http://www.cnblogs.com/haoxilu/p/3810698.html