Lucene.net入门学习系列(2)-创建索引
Lucene.net入门学习系列(3)-全文检索
这几天在公司实习的时候闲的蛋疼,翻了一下以往的教程和博客,看到了Lucene.net。原本想学着写一个系列的博文,由于本人水平有限,一直找不到适合的内容来写,干脆就写一个简单的Lucene.net系列文章吧。希望和大家一起学习,一起进步,有什么写错了或者有什么建议欢迎提出来。
一.引言
先说一说什么是Lucene.net。Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的功能。
说完了Lucene.net,接着来说什么是全文检索。全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。
二.分词
前面的引言大概说了一下什么是全文检索,介绍了Lucene.net这个全文检索引擎。要做全文检索,首先要做的就是分词。
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。不过,前辈们已经做了很多工作,我们只要拿来用就行了。在这里,我们使用"盘古分词"。盘古分词是一个基于.net 平台的开源中文分词组件,提供lucene(.net 版本) 和HubbleDotNet的接口,采用字典和统计结合的分词算法,分词准确率较高。
说了那么多的废话,现在我们来看一看如何分词。
我们要添加对3个程序集的引用: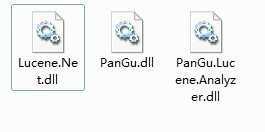
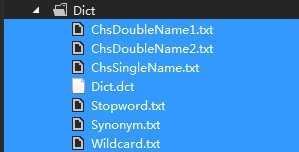
还要对字典进行设置:
1.将字典放到项目中(字典在本文末提供下载)
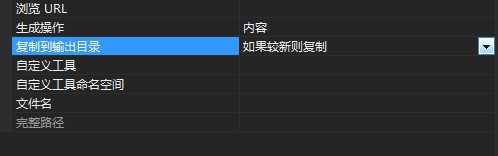
2.在属性中设置:把"复制到输出目录"这个选项改成"如果较新则复制"
上代码

1 /// <summary>
2 /// 分词
3 /// </summary>
4 /// <param name="word">要分的词</param>
5 /// <returns>string数组:分好的词的集合</returns>
6 public static string[] SplitWords(string word)
7 {
8 //创建列表,用来装分好的词
9 List<string> list = new List<string>();
10
11 //实例化一个PanGuAnalyzer对象
12 Analyzer analyzer = new PanGuAnalyzer();
13
14 //然后通过分析器得到一个TokenStream
15 TokenStream tokenStream = analyzer.TokenStream("", new StringReader(word));
16
17 Token token;
18 //遍历tokenStream中的Token,如果为空返回Null
19 while ((token = tokenStream.Next()) != null)
20 {
21 //将每一个分词添加到list中
22 list.Add(token.TermText());
23 }
24
25 return list.ToArray();
26 }
接下来,进行测试。
1 static void Main(string[] args)
2 {
3 const string s1 = "其中,崔家乡挂职队在崔家乡政府一周一次的“党员干部义工日”中";
4 const string s2 = "台球原来可以这样打的么?";
5
6 //我们使用linq来测试,遍历分词集合并输出
7 (from r in SplitWords(s1) select r).ToList().ForEach(a => Console.Write(a + " "));
8
9 Console.WriteLine();
10
11 (from r in SplitWords(s2) select r).ToList().ForEach(a => Console.Write(a + " "));
12
13 Console.Read();
14 }
测试结果:
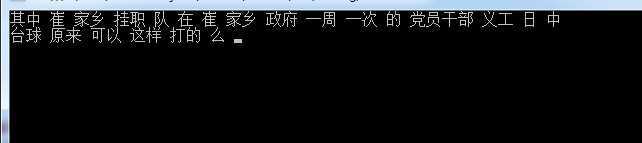
我们可以看到,分出来的效果还是比较令人满意的。像"崔家乡"这些地名词,我们可以通过盘古分词附带的一个工具将词语添加进去。
(添加后要记得保存并覆盖程序使用的那个词典,否则没有效果)
注:修改的是源程序中的那个Dict字典,生成程序之后字典会复制到输出目录中
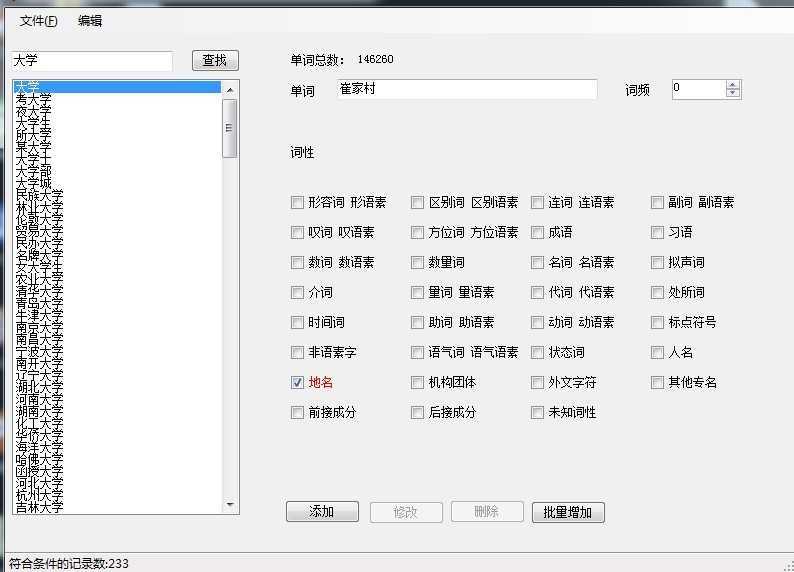
添加好词语之后我们再来进行一次测试。

我们可以看到,盘古分词已经"崔家乡"这个词当做一个词来看待了。
Dll下载地址:http://files.cnblogs.com/g1mist/SplitWords-PanGu.zip
字典下载地址:http://files.cnblogs.com/g1mist/Dict.zip
Lucene.net入门学习系列(1),布布扣,bubuko.com
原文地址:http://www.cnblogs.com/superfeeling/p/3812381.html