为了对重复数据进行实验,下面建一个设计不太好(没有主键)表并插入了一些重复数据:
create database testdb
use testdb ;
go
create table DupsNoPK
(Col1 int Null,
Col2 char(5) Null
);
go
insert DupsNoPK(Col1,Col2)
Values(1,‘abc‘),
(2,‘abc‘),
(2,‘abc‘),
(2,‘abc‘),
(7,‘xyz‘),
(7,‘xyz‘);
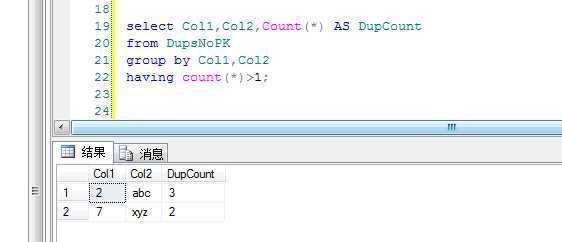
为了验证表确实有重复数据,下面查询运用了一个group by 和having 子句只返回重复行,并对副本计数:
select Col1,Col2,Count(*) AS DupCount from DupsNoPK group by Col1,Col2 having count(*)>1;
结果:
下面是运用窗口化删除重复行:
这种方法的关键是运用窗口化的,有row_number()函数和分区的over()子句。每个新分区会重新编号。设置over()子句为partition by每个要检查重复数据的列。在这种情况下每一列都会进行检查。
运行窗口化查询,首先显示方法如何应用于行号:
select Col1,Col2, row_number()over(partition by Col1,Col2 order by Col1)as rn from DupsNoPK
结果:
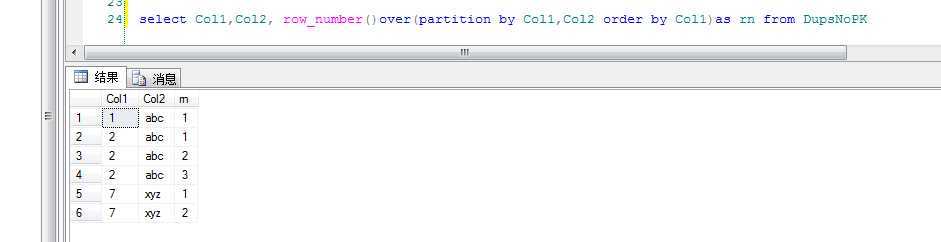
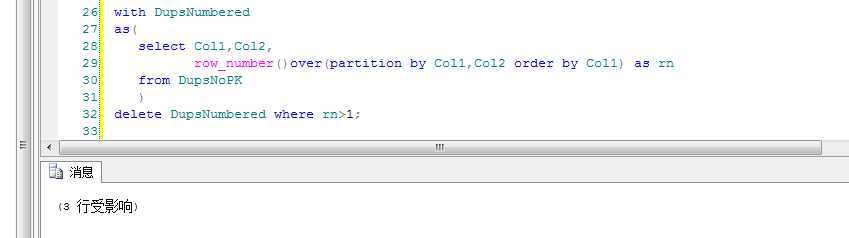
每一个重复行都有一个比1大的rn值,所以,删除副本是比较容易的:
with DupsNumbered
as(
select Col1,Col2,
row_number()over(partition by Col1,Col2 order by Col1) as rn
from DupsNoPK
)
delete DupsNumbered where rn>1;
结果:
执行完上面语句后,下面用一条select语句测试删除重复数据的结果:
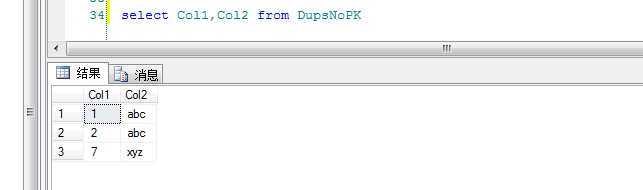
MSSQL如何在没有主键的表中删除重复数据,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/hsw-2013/p/3813014.html