标签:
倒排列表压缩算法
目前有很多种倒排列表算法可以选择,但是我们对评判算法的优劣需要定量指标。一般会考虑3个指标:压缩率、压缩速度以及解压速度。
压缩率是指数据压缩前和压缩后大小的比例,显然,压缩率越高,就越节约磁盘空间。而压缩速度是压缩单位量的数据所花的时间,但是压缩往往是在建立索引过程中进行的,这是一个后台进行的过程,不需要及时响应用户查询,即使速度慢一些也没有关系。所以普遍来说,压缩速度不是一个重要指标。
那么我们来看看解压速度。顾名思义,解压就是将压缩数据恢复到原始数据。这是一个实时响应过程。用户在运用搜索引擎查询的时候,搜索引擎从磁盘读入的数据是压缩的,需要实时解压然后快速响应给用户,所以这个时间是我们在百度搜索网页时等待的时间,其重要性不言而喻吧。
一元编码和二进制编码
这个是所有倒排列表压缩算法的基础构成元素。一元编码是非常简单直观的数据表示方式,我们对于一整数X来说,使用X-1个二进制数字1和末尾一个0来表示这个数字,比如5对应的一元编码就是11110, 3对应的一元编码就是110,但是相信大家都看出来了,这种一元编码对于处理大整数来说是非常不划算的。二进制编码不用多说了吧,就是一个整数的二进制表示法。
Elias Gamma算法和Elias Delta算法
Elias Gamma压缩算法利用分解函数将待压缩的数字分解为两个因子,之后分别用一元编码和二进制编码来表示这两个因子(刚才都说了嘛,一元编码和二进制编码是这些算法的基础构件)。
该算法的分解函数:X = 2e + d
其中,X为待压缩的数字,e和d分别为其因子,得到其因子后,我们对于因为e+1采用一元编码来表示,对于因子d采用比特宽度为e的二进制来表示。比如X为9,那么X = 23 + 1 ,对于e+1也就是4得到的一元编码就是1110,对于d用比特宽度为3的二进制表示为001,将两者拼接为1110:001,这就是十进制数字9最后的Elias Gamma编码。
Elias Delta算法是建立在Elias Gamma算法基础上的改进,实际上就是实现两次Elias Gamma算法。我们对数字X采用Elias Gamma算法得到了e 和 d ,此时我们需要对e+1再次进行Elias Gamma编码表示,而d因子表示和Elias Gamma算法一样。比如上文提到的十进制数字9,第一次Elias Gamma算法得到了9 = 23 + 1 ,此时3+1需要再次Elias Gamma:3+1 = 22 + 0 ,因此,采用Elias Delta算法得到的十进制数字9的最终编码表示出来就是110:00:001。
Golomb算法和Rice算法
Golomb算法和Rice算法大致思路和上述两个Elias算法类似,即根据分解函数将待压缩数字分解为两个因子,分别用一元编码和二进制编码表示即可,不同之处在于采取了不一样的分解函数
对于Golomb 和 Rice 算法来说:因子1 = (X-1)/b 因子2 = (X-1)mod b
然后将因子1这个数值加上1之后采用一元编码压缩,因子2使用比特宽度为log(b)的二进制编码。
那么b应该取哪个值呢?这也是Golomb和Rice算法的不同之处。假设一个待压缩数列的平均值为Avg,那么Golomb算法就设定b=0.69*Avg,这里的0.69就是一个经验参数。而Rice算法就要求b得是2的整数次幂,同时b必须是小于Avg并且最近Avg的值。比如Avg是115的话,那么b就会设定为64;如果Avg为60的话,此时b就得为32,因为64超过Avg了。
变长字节算法
不知道大家对我上一次总结中的跳跃指针还有没有印象,它是把整个倒排列表分成了好几块,然后进行分块查询处理。这个算法的思想上和跳跃指针差不多,就是把整数拆分开。
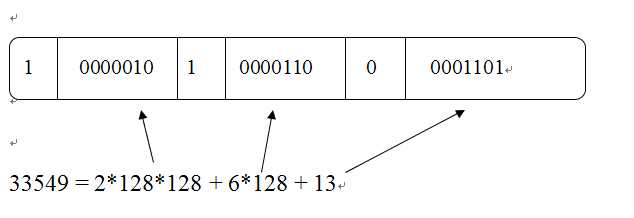
变长字节算法以字节(即比特宽度为8)为一个基本存储单位,然而之前介绍的压缩算法,都是以比特位(Bit)作为基本存储单位。之所以称之为“变长字节”,是因为对于不用的数字来说,最后压缩编码后表示的结果所占用的字节数目不一定相同,可长可短。
我们在用这个算法压缩数据的时候,为了确定两个连续数字压缩后的边界,需要利用字节中一个比特位作为边界判断。一般情况下,如果边界判断设定为0,则可以认为这个字节是数字压缩编码的最后一个字节,而如果是1,则说明后续的字节仍然是属于当前的压缩数据数字。所以每个字节里,第一个比特位是用来做边界判断,后面7个比特位采用二进制编码来存储压缩的数据,即每个字节只可以存储的数值范围为0~127。
下图表示十进制数字33549采用变长字节算法编码后的表示结果
PForDelta算法
PForDelta压缩算法是目前解压缩速度最快的一种倒排文件压缩算法。
该算法基本出发点就是尽可能一次性压缩和解压多个数值。对于待编码的连续K个数值(一般取128,即一次性压缩解压128个数值),找出其中10%比例的较大数,对剩下90%的数值采取一个设定的比特宽度,而10%的大数当做异常数据单独存储。假设一次性要压缩的数值序列为:24,40,9,13,31,67,19,44,22,10,即K取10,下图是PForDelta算法压缩以上数据序列后形成的静态结构,压缩后的数据可以划分为3块:异常数据存储区、常规数据存储区以及异常链表头。
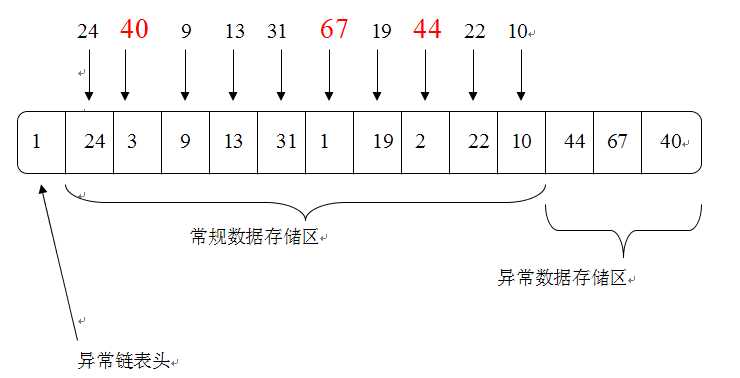
下面详解一下这个例子:除了30%的3个大数外,最大的数值为31,所以为了能够表示这70%的数值,比特宽度需要设定为5,这个可以理解吧。该算法在常规数据存储区维护了异常大数的一个顺序链表,比如对于异常数值40,其常规数据存储区对应位置设定为3,含义是指跳过后面3个数值即是另外一个异常大数的位置,通过这样就将异常大数的位置信息保留下来,这样在解压的时候能够快速恢复原始数据。
异常链表头则存放一个指针,指向了异常链表的第一个数值的位置,本例中链表头的值为1,意即跳过后续一个常规数值即可获得第一个异常大数的位置,通过链表头,就可以将所有异常大数快速串联起来。
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4557330.html