标签:style blog http color 文件 数据
SSTable是leveldb 的核心模块,这也是其称为leveldb的原因,leveldb正是通过将数据分为不同level的数据分为对应的不同的数据文件存储到磁盘之中的。为了理解其机制,我们首先看看SSTable中的基本概念。
首先看看数据的整体存储结构:

可以从图中看到了几个概念:Datablock,Metablock, MetaIndex block, Indexblock, Footer.具体他们的含义可以大致解释如下:
1. Datablock,我们知道文件中的k/v对是有序存储的,他们被划分到连续排列的Data Block里面顺序存储起来;
2. 紧跟数据存储区的是Meta Block,存储的是Filter信息,比如Bloom过滤器,用于快速判断key是否在对应数据块;
3. MetaIndex Block是对Meta Block的索引,它只有一条记录,为meta index的名字(也就是Filter的名字)和指向meta Block的BlockHandle;
4. Index block是对Data Block的索引,对于其中的每个记录,其key >=Data Block最后一条记录的key,同时<其后Data Block的第一条记录的key;value是指向data index的BlockHandle;
5. 最后的是一个定长的Footer,他包含了MetaIndex block和Indexblock 的BlockHandle,以及填充区和一个magic数字。其逻辑格式如下图
 了解了每个块的大致作用以后,我们再来详细分析每个组成部分,首先是Datablock其总体格式如下图
了解了每个块的大致作用以后,我们再来详细分析每个组成部分,首先是Datablock其总体格式如下图
 Block data存储的就是我们leveldb中最关键的数据KV对,而type是一个标记Block data是否采用了Snappy压缩算法,crc32顾名思义则是整个block的一个crc校验值,用于判断block是否出错。知道整体结构以后我们再来看看具体的block data部分的存储格式:
Block data存储的就是我们leveldb中最关键的数据KV对,而type是一个标记Block data是否采用了Snappy压缩算法,crc32顾名思义则是整个block的一个crc校验值,用于判断block是否出错。知道整体结构以后我们再来看看具体的block data部分的存储格式:
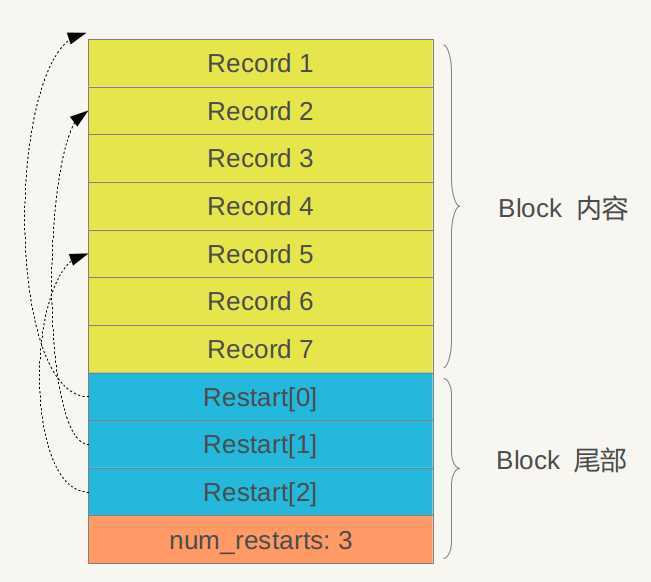
也许你会以为在划分好block的数据存储区域以后那么就是一个一个的KV对(如图中的Record)了,但是其实不是,leveldb为了降低数据的存储量和快速的查找引入了一个重启点(restartpoint)的概念。这里的restart是指kv对的K的重现完整存储的概念,我们来看看每个record的存储格式以理解这里的restartpoint这个概念。

在leveldb中每一个KV对被分为了如上图的几个部分,因为Block内容里的KV记录是按照Key大小有序的,所以相邻的两条记录之间的Key很可能存在一个相同的部分,比如key i=“the Car”,Key i+1=“the color”,那么两者存在相同部分“the c”。leveldb就可以利用这个相邻记录存在相同部分来尽量减少Key的存储量,比如Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。所以整个存储区就存在这样的一个存储情况:一条记录存储完整的Key,而之后的记录开始连续一定的记录数都采取只记载不同的Key部分,然后在是一个重新存储完整的Key值的记录,然后再是一定数量的存储不完整Key的记录,那么我们就称这里的存储完整的Key值的记录为重启点。所以上面的图中的Restart就是用来记录这些存储完整Key的Record的地址,而num_restarts则更容易理解了,就是我们这个block中一共有多少个这样存储了完整Key的Record。
倒过去理解,最后我们首先看本block有多少个存储了完整Key的记录,然后这些记录的位置在那里,然后根据这些位置信息就可以定位到完整KV对,举个例子如下:
0|9|3|test comm|onn 5|4|4|hahaa|haha 0|9|4|testtest1|xxxx 4|4|4|tttt|tttt
开始
第三条记录的偏移量
2
将上面的展开就可以得到记录为
test comm|onn test hahaa|haha testtest1|xxxx testtttt|tttt
下一篇文章将从代码的角度进行分析
leveldb源码分析--SSTable之逻辑结构,布布扣,bubuko.com
标签:style blog http color 文件 数据
原文地址:http://www.cnblogs.com/KevinT/p/3815764.html